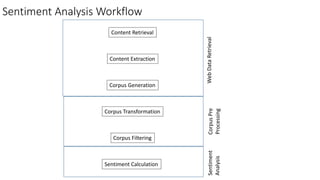
This document provides an introduction to text mining, including defining key concepts such as structured vs. unstructured data, why text mining is useful, and some common challenges. It also outlines important text mining techniques like pre-processing text through normalization, tokenization, stemming, and removing stop words to prepare text for analysis. Text mining methods can be used for applications such as sentiment analysis, predicting markets or customer churn.