![Tokens andTypes
>>> from nltk.token import *
>>> my_word_type = 'dog‘
'dog’
>>> my_word_token =Token(my_word_type) ‘dog'@[?]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-11-320.jpg)
![Text Locations
• Text location @ [s:e] specifies a region of a text
– s is the start index
– e is the end index
• Specifies the text beginning at s, and including everything up to (but not
including) the text at e
• Consistent with Python slice](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-12-320.jpg)





![Accessing Corpora
• # tell Python we want to use the Gutenberg corpus
• from nltk.corpus import gutenberg
• # which files are in this corpus?
• print(gutenberg.fileids())
• >>> ['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-
kjv.txt', ...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-18-320.jpg)
![Accessing Corpora - RawText
• # get the raw text of a corpus = one string
• >>> emmaText = gutenberg.raw("austen-emma.txt")
• # print the first 289 characters of the text
• >>> emmaText = gutenberg.raw("austen-emma.txt")
• >>> emmaText[:289]
• '[Emma by Jane Austen 1816]nnVOLUME InnCHAPTER InnnEmmaWoodhouse, handsome, clever,
and rich, with a comfortable homenand happy disposition, seemed to unite some of the best
blessingsnof existence; and had lived nearly twenty-one years in the worldnwith very little to distress or
vex her.‘](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-19-320.jpg)
![Accessing Corpora -Words
• # get the words of a corpus as a list
• emmaWords = gutenberg.words("austen-emma.txt")
• # print the first 30 words of the text
• >>> print(emmaWords[:30])
• ['[', 'Emma', 'by', 'Jane', 'Austen', '1816', ']', 'VOLUME', 'I', 'CHAPTER', 'I', 'Emma',
'Woodhouse‘, 'handsome', ',', 'clever', ',', 'and', 'rich', ',', 'with', 'a', 'comfortable', 'home',
'and‘, 'happy', 'disposition', ',', 'seemed']](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-20-320.jpg)
![Accessing Corpora: Sentences
• # get the sentences of a corpus as a list of lists - one list of words per sentence
• >>> senseSents = gutenberg.sents("austen-sense.txt")
• # print out the first four sentences
• >>> print(senseSents[:4])
• [['[', 'Sense', 'and', 'Sensibility', 'by', 'Jane', 'Austen', '1811', ']'], ['CHAPTER', '1'], ['The',
'family', 'of', 'Dashwood', 'had', 'long‘, 'been', 'settled', 'in', 'Sussex', '.'], ['Their', 'estate',
'was', 'large', ',', 'and‘, 'their', 'residence', 'was', 'at', ...]]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-21-320.jpg)


![List Elements Operations
• List comprehension
– >>> len(set([word.lower() for word in
text4 if len(word)>5]))
– 7339
– >>> [w.upper() for w in text4[0:5]]
– ['FELLOW', '-', 'CITIZENS', 'OF', 'THE']
• Loops and conditionals
• For word in text4[0:5]:
if len(word)<5 and word.endswith('e'):
print word, ' is short and ends with e‘
elif word.istitle():
print word, ' is a titlecase word‘
else:
print word, 'is just another word'](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-24-320.jpg)
![Brown Corpus
• First million-word electronic corpus of English
• Created at Brown University in 1961
• Text from 500 sources, categorized by genre
• >>> from nltk.corpus import brown
• >>> print(brown.categories())
• ['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor‘,
'learned', 'lore', 'mystery', 'news', 'religion‘, 'reviews', 'romance', 'science_fiction']](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-25-320.jpg)
![Brown Corpus – RetrieveWords by Category
• >>> from nltk.corpus import brown
• >>> news_words = brown.words(categories = "news")
• >>> print(news_words)
• ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation',
'of', "Atlanta's“, 'recent', 'primary', 'election', 'produced', ...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-26-320.jpg)
![Brown Corpus – RetrieveWords by Category
• >>> adv_words = brown.words(categories = "adventure")
• >>> print(adv_words)
• ['Dan', 'Morgan', 'told', 'himself', 'he', 'would‘, 'forget', 'Ann', 'Turner', '.', ...]
• >>> reli_words = brown.words(categories = "religion")
• >>> print(reli_words)
• ['As', 'a', 'result', ',', 'although', 'we', 'still', 'make', 'use', 'of', 'this', 'distinction', ',',...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-27-320.jpg)

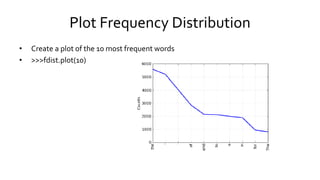
![Frequency Distribution
• >>>news_words = brown.words(categories = "news")
• >>>fdist = nltk.FreqDist(news_words)
• >>>print("shoe:", fdist["shoe"])
• >>>print("the: ", fdist["the"])](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-29-320.jpg)


![Stylistics
• from nltk import FreqDist
• # Define modals of interest
• >>>modals = ["may", "could", "will"]
• # Define genres of interest
• >>>genres = ["adventure", "news",
"government", "romance"]
• # count how often they occur in the genres
of interest
• >>>for g in genres:
• >>>words = brown.words(categories = g)
• >>>fdist = FreqDist([w.lower() for w in
words
• >>> if w.lower() in modals])
• >>>print g, fdist](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-33-320.jpg)
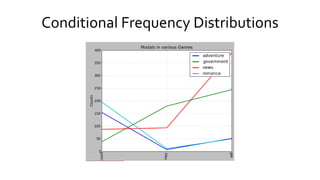
![Conditional Frequency Distributions
• >>>from nltk import ConditionalFreqDist
• >>>cfdist = ConditionalFreqDist()
• >>>for g in genres:
words = brown.words(categories = g)
for w in words
if w.lower() in modals:
cfdist[g].inc(w.lower())
• >>> cfdist.tabulate()
could may will
Adventure 154 7 51
Government 38 179 244
News 87 93 389
Romance 195 11 49
• >>>cfdist.plot(title="Modals in various Genres")](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-34-320.jpg)
![Processing RawText
• Assume you have a text file on your disk...
• # Read the text
• >>> path = "holmes.txt“
• >>> f = open(path)
• >>> rawText = f.read()
• >>> f.close()
• >>> print(rawText[:165])
• THE ADVENTURES OF SHERLOCK HOLMES
• By
• SIR ARTHUR CONAN DOYLE
I. A Scandal in Bohemia
II.The Red-headed League](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-36-320.jpg)
![SentenceTokenization
• # Split the text up into sentences
• >>> sents = nltk.sent_tokenize(raw)
• >>> print(sents[20:22])
• ['I had seen little of Holmes lately.', 'My marriage had drifted usrnaway from
each other.‘, ...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-37-320.jpg)
![WordTokenization
• >>># Tokenize the sentences using nltk
• >>>tokens = []
• >>>for sent in sents:
tokens += nltk.word_tokenize(sent)
• >>>print(tokens[300:350])
• [’such’, ’as’, ’his’, ’.’, ’And’, ’yet’, ’there’, ’was’, ’but’, ’one’, ’woman’, ’to’, ’him’, ’,’, ’and’, ’that’,
’woman’, ’was’, ’the’, ’late’, ’Irene’, ’Adler’, ’,’, ’of’, ’dubious’, ’and’, ’questionable’, ’memory’,
...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-38-320.jpg)




![WordNet
• Structured, semantically oriented English dictionary
• Synonyms, antonyms, hyponims, hypernims, depth of a synset, trees, entailments,
etc.
• >>> from nltk.corpus import wordnet as wn
• >>> wn.synsets('motorcar')
• [Synset('car.n.01')]
• >>> wn.synset('car.n.01').lemma_names
• ['car', 'auto', 'automobile', 'machine', 'motorcar']](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-43-320.jpg)
![WordNet
• >>> wn.synset('car.n.01').definition
• 'a motor vehicle with four wheels; usually propelled by an internal combustion engine'
• >>> for synset in wn.synsets('car')[1:3]:
• ... print synset.lemma_names
• ['car', 'railcar', 'railway_car', 'railroad_car'] ['car', 'gondola']
• >>> wn.synset('walk.v.01').entailments()
• #Walking involves stepping
• [Synset('step.v.01')]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-44-320.jpg)
![Getting InputText - HTML
• >>> from urllib import urlopen
• >>> url = "http://www.bbc.co.uk/news/science-environment-21471908"
• >>> html = urlopen(url).read()
• html[:60]
• >>> raw = nltk.clean_html(html)
• '<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN" "http'
• >>> tokens = nltk.word_tokenize(raw)
• >>> tokens[:15]
• ['BBC', 'News', '-', 'Exoplanet', 'Kepler', '37b', 'is', 'tiniest‘, 'yet', '-', 'smaller', 'than', 'Mercury', 'Accessibility',
'links‘]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-45-320.jpg)
![Getting InputText - User
• >>> s = raw_input("Enter some text: ")
• Use your own files on disk
• >>> f = open('C:DataFilesUK_natl_2010_en_Lab.txt')
• >>> raw = f.read()
• >>> print raw[:100]
• #Foreword by Gordon Brown
• This General Election is fought as our troops are bravely fighting to def](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-46-320.jpg)
![Import Files as Corpus
• >>> from nltk.corpus import PlaintextCorpusReader
• >>> corpus_root = "C:/Data/Files/"
• >>> wordlists = PlaintextCorpusReader(corpus_root, '.*.txt')
• >>> wordlists.fileids()[:3]
• ['UK_natl_1987_en_Con.txt', 'UK_natl_1987_en_Lab.txt',
• 'UK_natl_1987_en_LibSDP.txt']
• >>> wordlists.words('UK_natl_2010_en_Lab.txt')
• ['#', 'Foreword', 'by', 'Gordon', 'Brown', '.', 'This', ...]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-47-320.jpg)
![Stemming
• Strip off affixes
• >>>porter = nltk.PorterStemmer()
• >>>[porter.stem(t) for t in tokens]
• Porter stemmer lying - lie, women - women
• >>>lancaster = nltk.LancasterStemmer()
• >>>[lancaster.stem(t) for t in tokens]
• Lancaster stemmer lying - lying, women - wom](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-48-320.jpg)
![Lemmatization
• Removes affixes if in dictionary
• >>>wnl = nltk.WordNetLemmatizer()
• >>>[wnl.lemmatize(t) for t in tokens]
• lying - lying, women - woman](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-49-320.jpg)



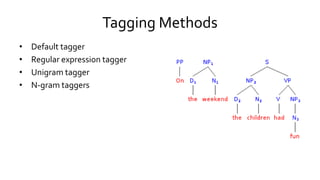

![Tagging Examples
• Some corpora already tagged
• >>> nltk.corpus.brown.tagged_words()
• [('The', 'AT'), ('Fulton', 'NP-TL'), ...]
• A simple example
• >>> nltk.pos_tag(text)
• [('And', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different', 'JJ')]
– CC is coordinating conjunction; RB is adverb; IN is preposition; NN is noun; JJ is adjective
– Lots of others - foreign term, verb tenses, “wh” determiner etc](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-55-320.jpg)
![Tagging Examples
• An example with homonyms
• >>> text = nltk.word_tokenize("They refuse to permit us to obtain the
refuse permit")
• >>> nltk.pos_tag(text)
• [('They', 'PRP'), ('refuse', 'VBP'), ('to', 'TO'), ('permit‘, 'VB'), ('us', 'PRP'),
('to', 'TO'), ('obtain', 'VB'), ('the‘, 'DT'), ('refuse', 'NN'), ('permit', 'NN')]](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-56-320.jpg)







![Example – Identify Gender by Name
• Relevant feature: last letter
• Create a feature set (a dictionary) that maps feature’s names to their values
– >>>def gender_features(word):
– >>>return {'last_letter': word[-1]}
• Import names, shuffle them
– >>>from nltk.corpus import names
– >>>import random
– >>>names = ([(name, 'male') for name in names.words('male.txt')] + [(name, 'female') for
name in names.words('female.txt')])
– >>>random.shuffle(names)](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-68-320.jpg)
![Example – Identify Gender by Name
• Divide list of features into training set and test set
– >>>featuresets = [(gender_features(n), g) for (n,g) in names]
– >>>from nltk.classify import apply_features
– >>>#Use apply if you're working with large corpora
– >>>train_set = apply_features(gender_features, names[500:])
– >>>test_set = apply_features(gender_features, names[:500])
• Use training set to train a naive Bayes classier
– >>>classifier = nltk.NaiveBayesClassifier.train(train_set)](https://image.slidesharecdn.com/nltkmaster-150830120224-lva1-app6892/85/NLTK-69-320.jpg)






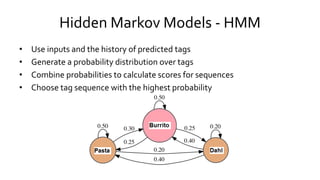




This document provides an overview of the Natural Language Toolkit (NLTK), a Python library for natural language processing. It discusses NLTK's modules for common NLP tasks like tokenization, part-of-speech tagging, parsing, and classification. It also describes how NLTK can be used to analyze text corpora, frequency distributions, collocations and concordances. Key functions of NLTK include tokenizing text, accessing annotated corpora, analyzing word frequencies, part-of-speech tagging, and shallow parsing.