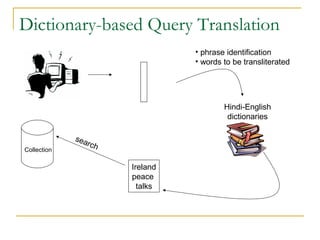
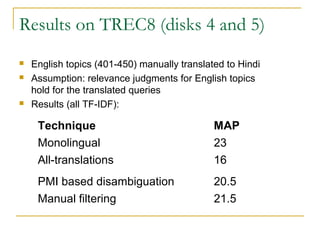
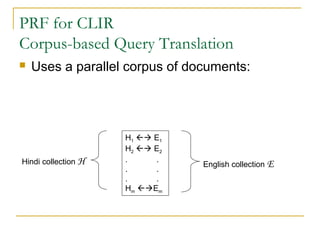
This document discusses cross-language information retrieval (CLIR). It defines CLIR as retrieving information written in a language different from the user's query language. It describes approaches to CLIR such as dictionary-based query translation and pseudo-relevance feedback. Dictionary-based query translation uses bilingual dictionaries but requires disambiguation due to ambiguity. Pseudo-relevance feedback assumes top documents are relevant and selects terms from them to expand the query. The document also discusses using parallel corpora to estimate cross-lingual relevance models and evaluate CLIR using conferences like TREC and CLEF.