Download to read offline



![Natural Language Processing and Text
Analytics
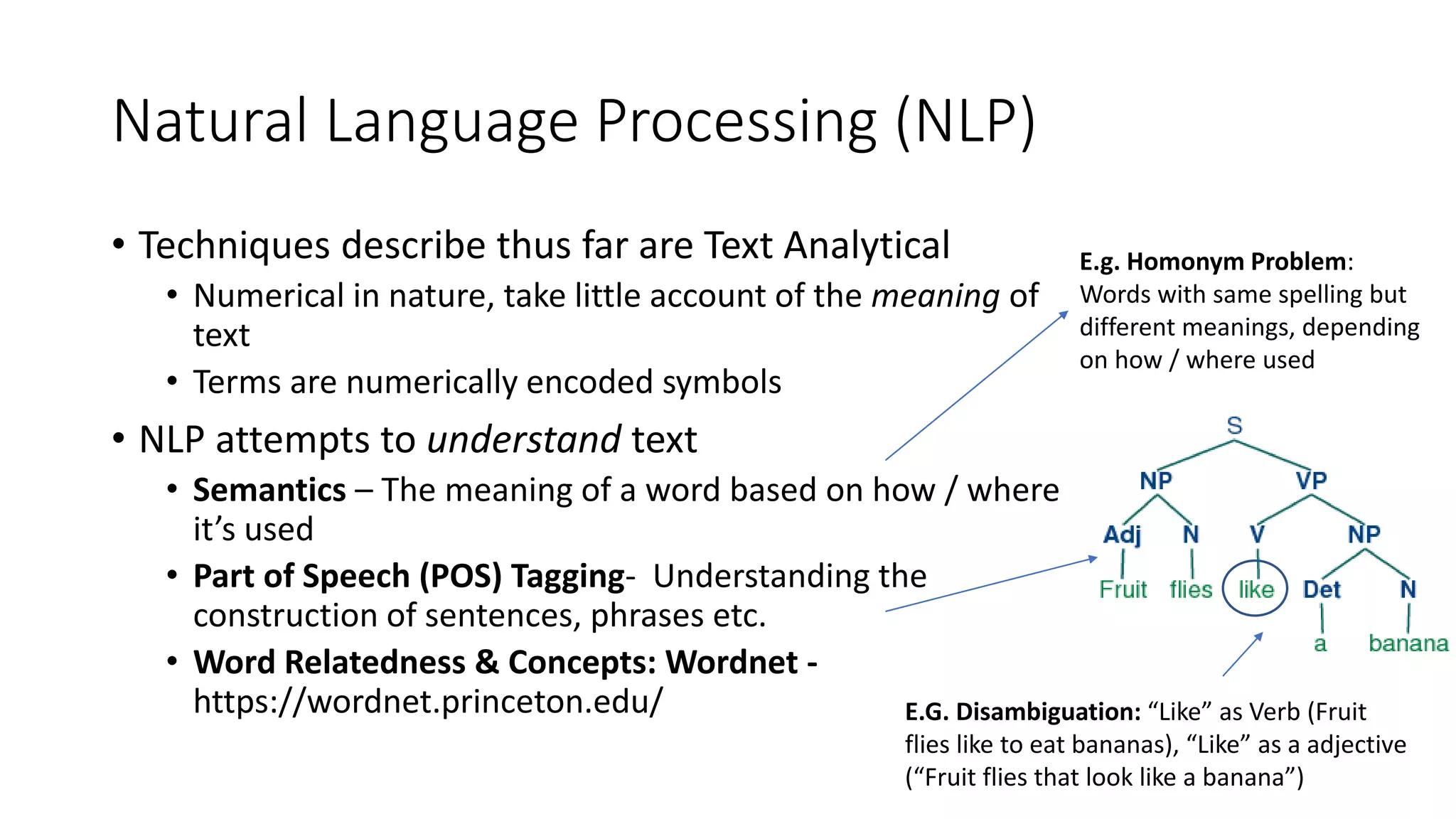
• Natural Language Processing (NLP)
• Area of AI concerned with interactions between computers and human natural
language, to process or “understand” natural language
• Common tasks: speech recognition, natural language understanding & generation,
automatic summarization, part-of-speech tagging, disambiguation, named entity
recognition …
• To fully understand and represent the meaning of language is a difficult goal (AI-
Complete) [1]
• Text Analytics (Text Mining):
• The process or practice of examining large collections of written resources in order
to generate new information (Oxford English Dictionary)
• Transforms text to data for information discovery, establishing relationships, often
using NLP](https://image.slidesharecdn.com/corkmeetup3-v3-180315133037/75/Cork-AI-Meetup-Number-3-4-2048.jpg)







![Resources and References
[1] “Natural Language Processing with Deep Learning” – Christopher Manning et
al, Stamford University. https://www.youtube.com/watch?v=OQQ-W_63UgQ
• Lecture series including excellent description of back propagation, word2vec and GLOVE
[2] “Hands-On Machine Learning with Scikit-Learn & TensorFlow”, Aurélien
Géron (O'Reilly Media, 2017)
• Excellent introduction, Jupyter Notebooks available here: https://github.com/ageron
[3] “Speech and Language Processing”, Daniel Jurafsky & James H. Martin (2nd
Edition, Pearson Education 2009)
• In-depth introduction to NLP
[4] “Introduction to Information Retrieval”, Christopher Manning et al
(Cambridge University Press, 2008)
• Probabilistic models for text retrieval, TF/IDF, Vector Space, Support Vector Machines…](https://image.slidesharecdn.com/corkmeetup3-v3-180315133037/75/Cork-AI-Meetup-Number-3-18-2048.jpg)

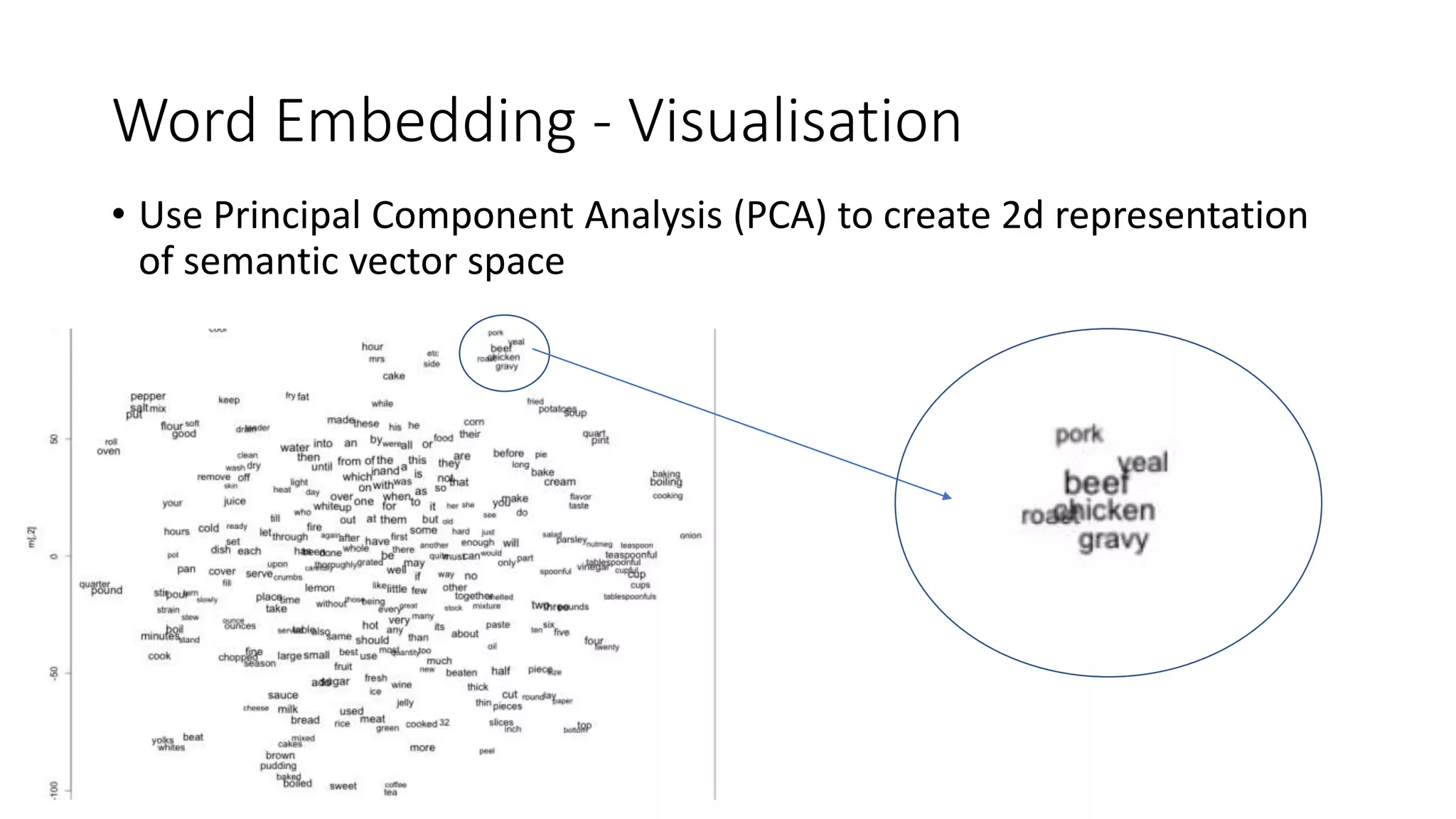
This document provides an introduction to text analytics and natural language processing techniques. It discusses bag-of-words models, term frequency-inverse document frequency (TF-IDF), vector space models, distance measures, document clustering, word embeddings using word2vec, and recurrent neural networks. The agenda covers traditional "frequentist" text analysis methods as well as deep learning techniques for semantic analysis. Hands-on examples in Python are provided to illustrate document clustering, creating word embeddings, and generating text with recurrent neural networks.





























![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

