Download as PDF, PPTX








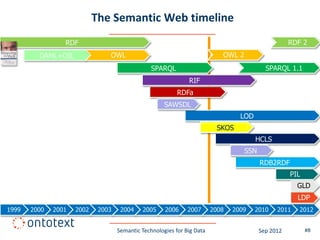


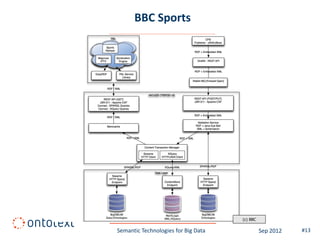



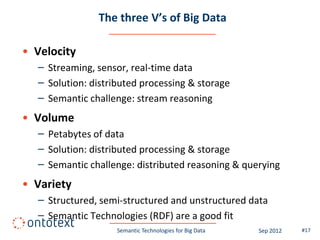


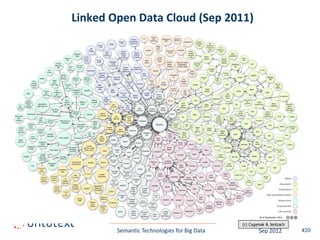



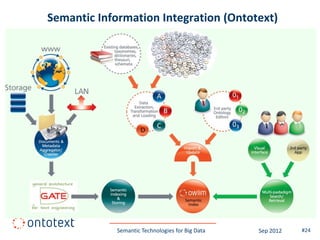

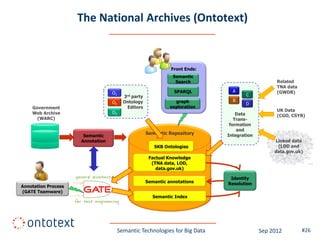



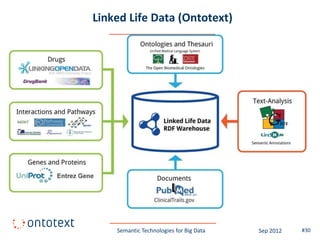



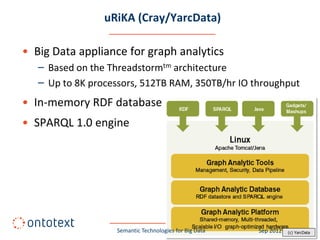





This document summarizes a presentation about semantic technologies for big data. It discusses how semantic technologies can help address challenges related to the volume, velocity, and variety of big data. Specific examples are provided of large semantic datasets containing billions of triples and semantic applications that have integrated and analyzed disparate data sources. Semantic technologies are presented as a good fit for addressing big data's variety, and research is making progress in applying them to velocity and volume as well.


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















