Downloaded 381 times



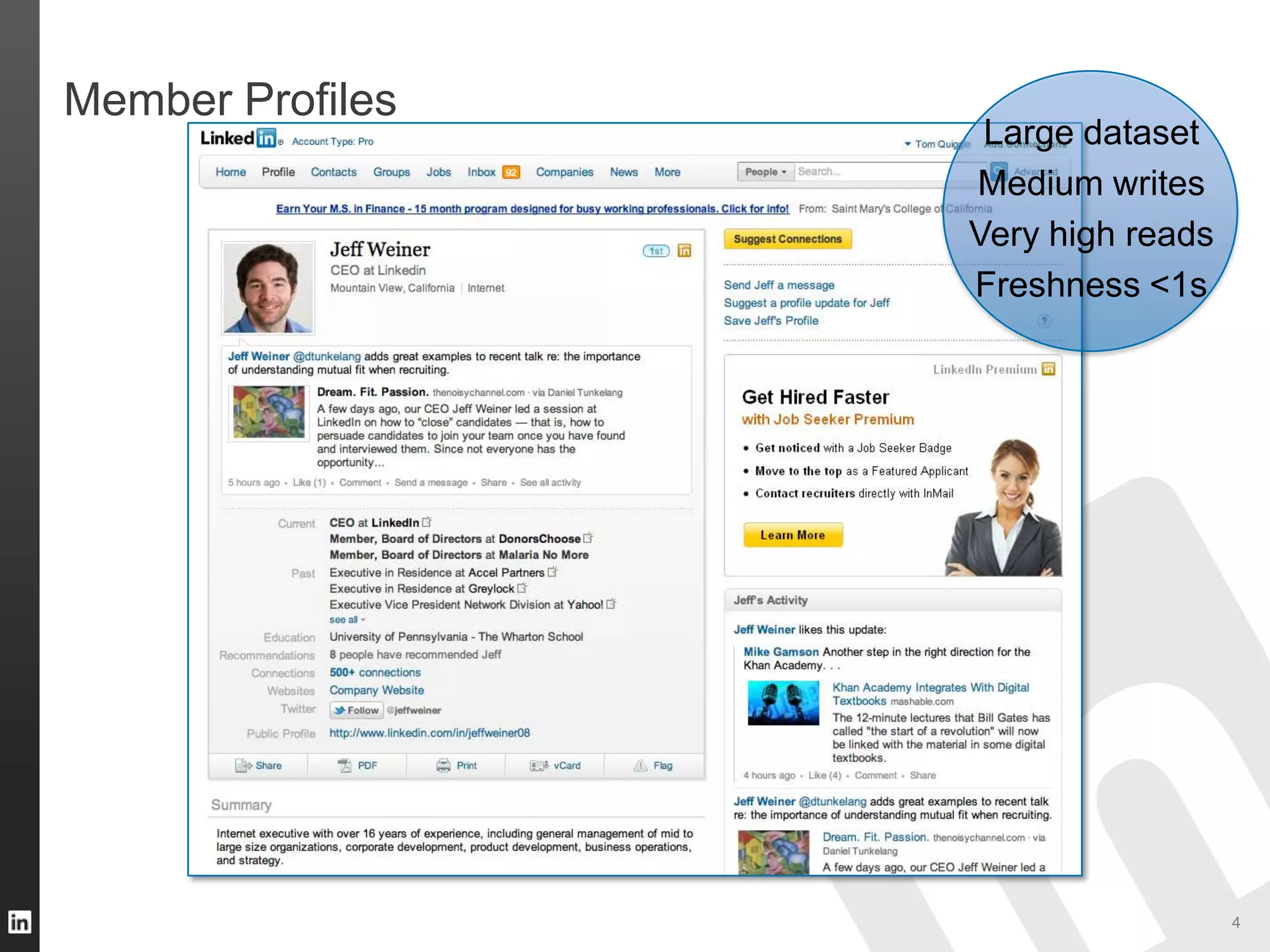
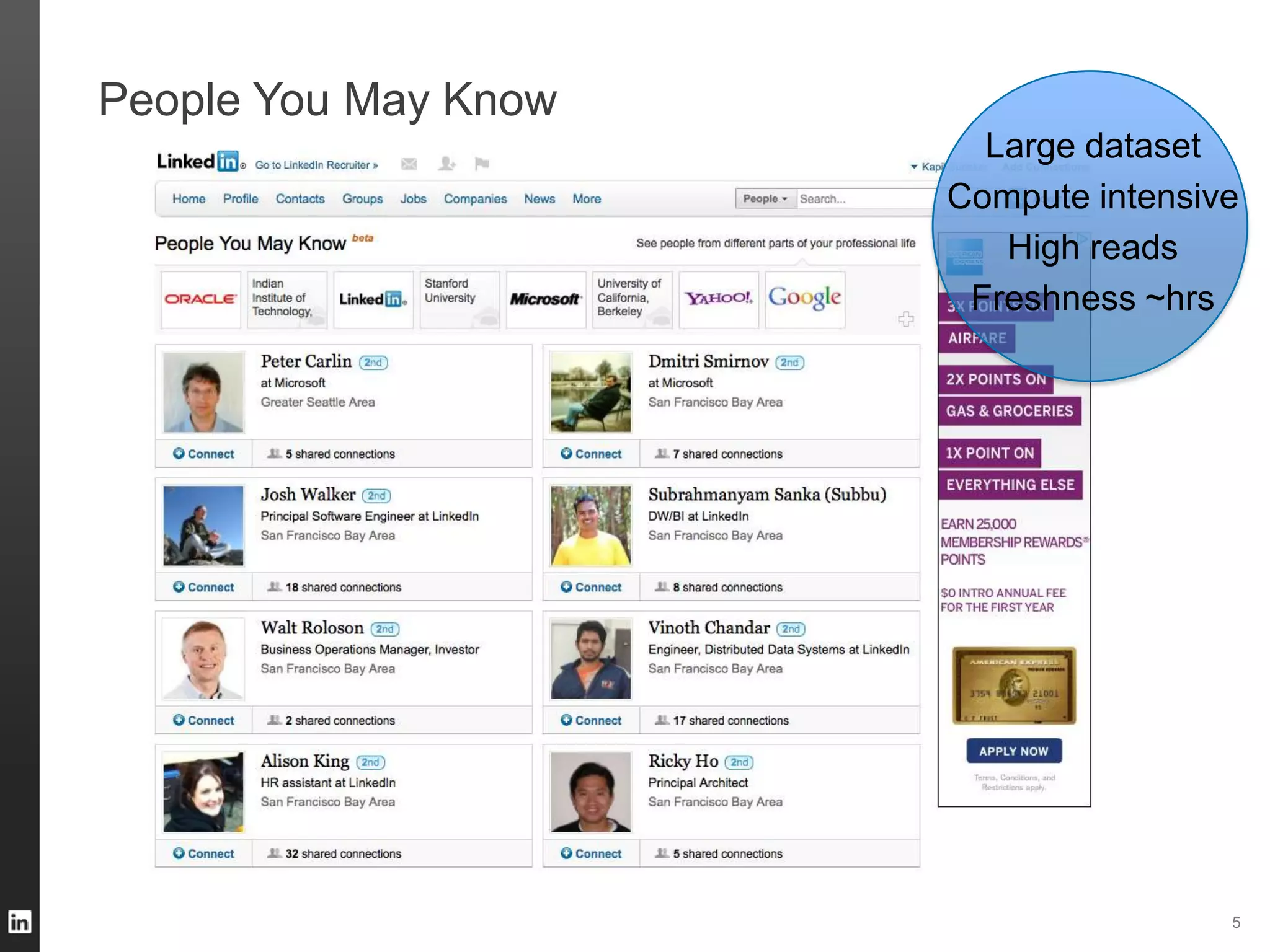
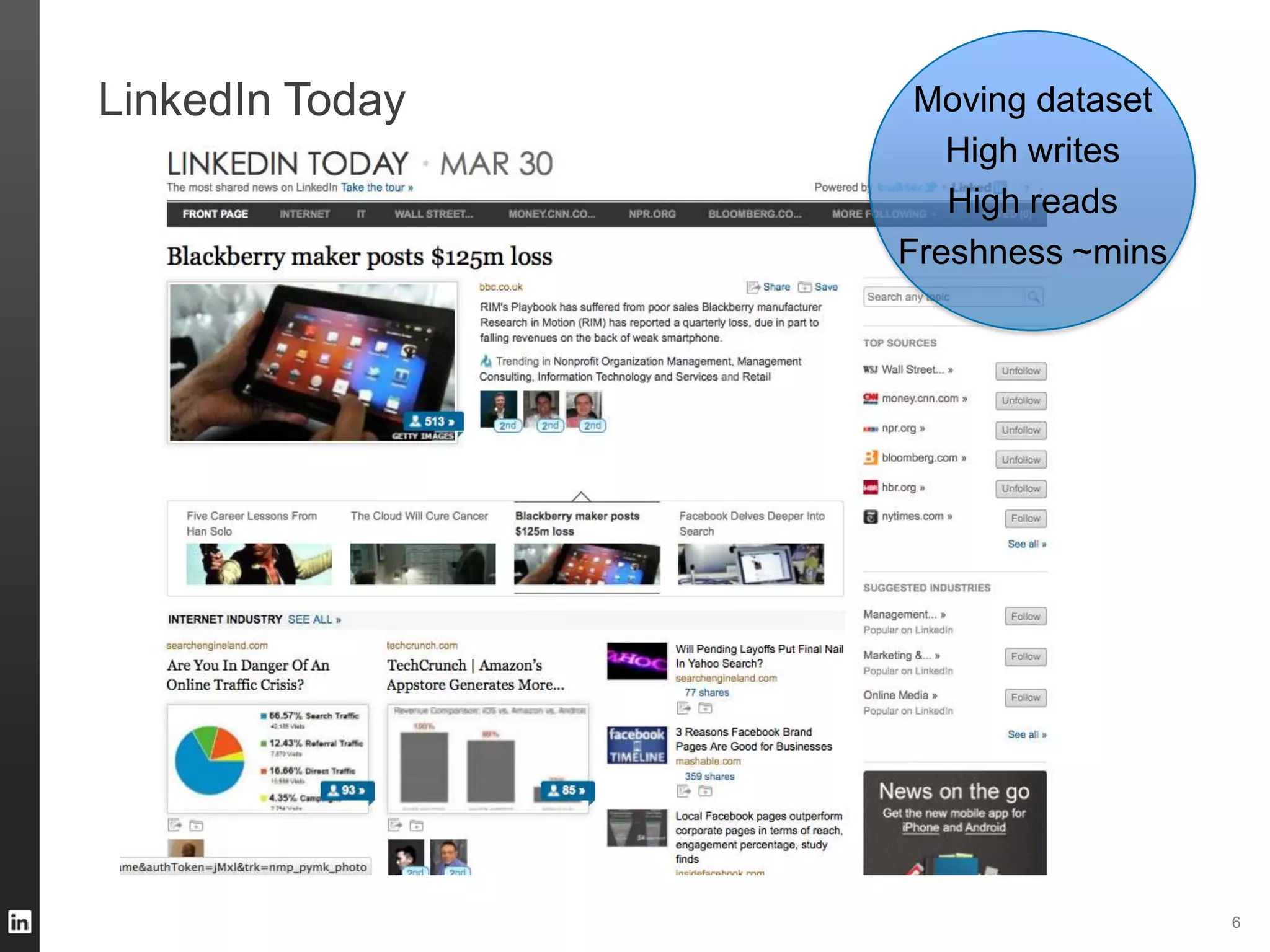
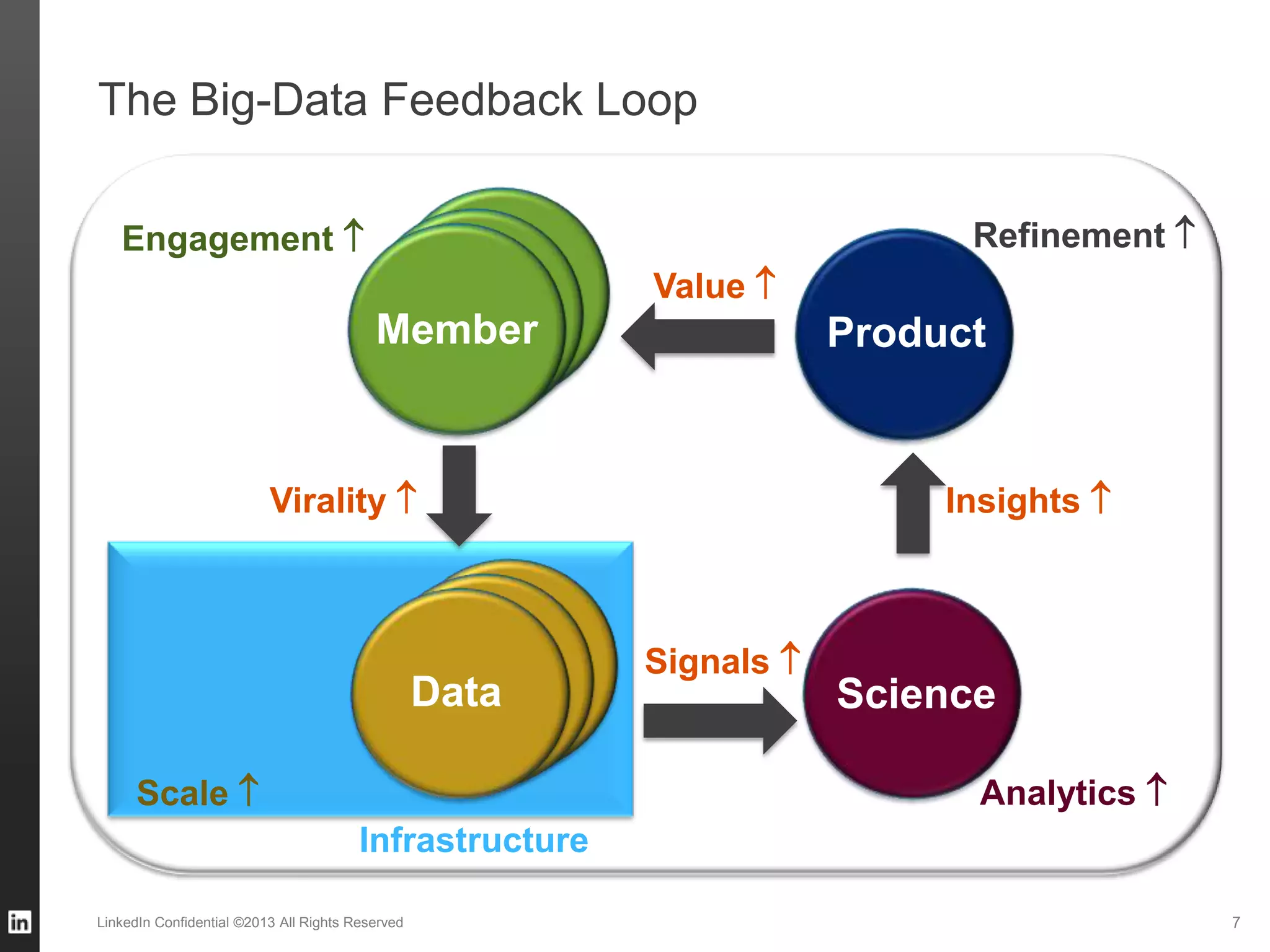
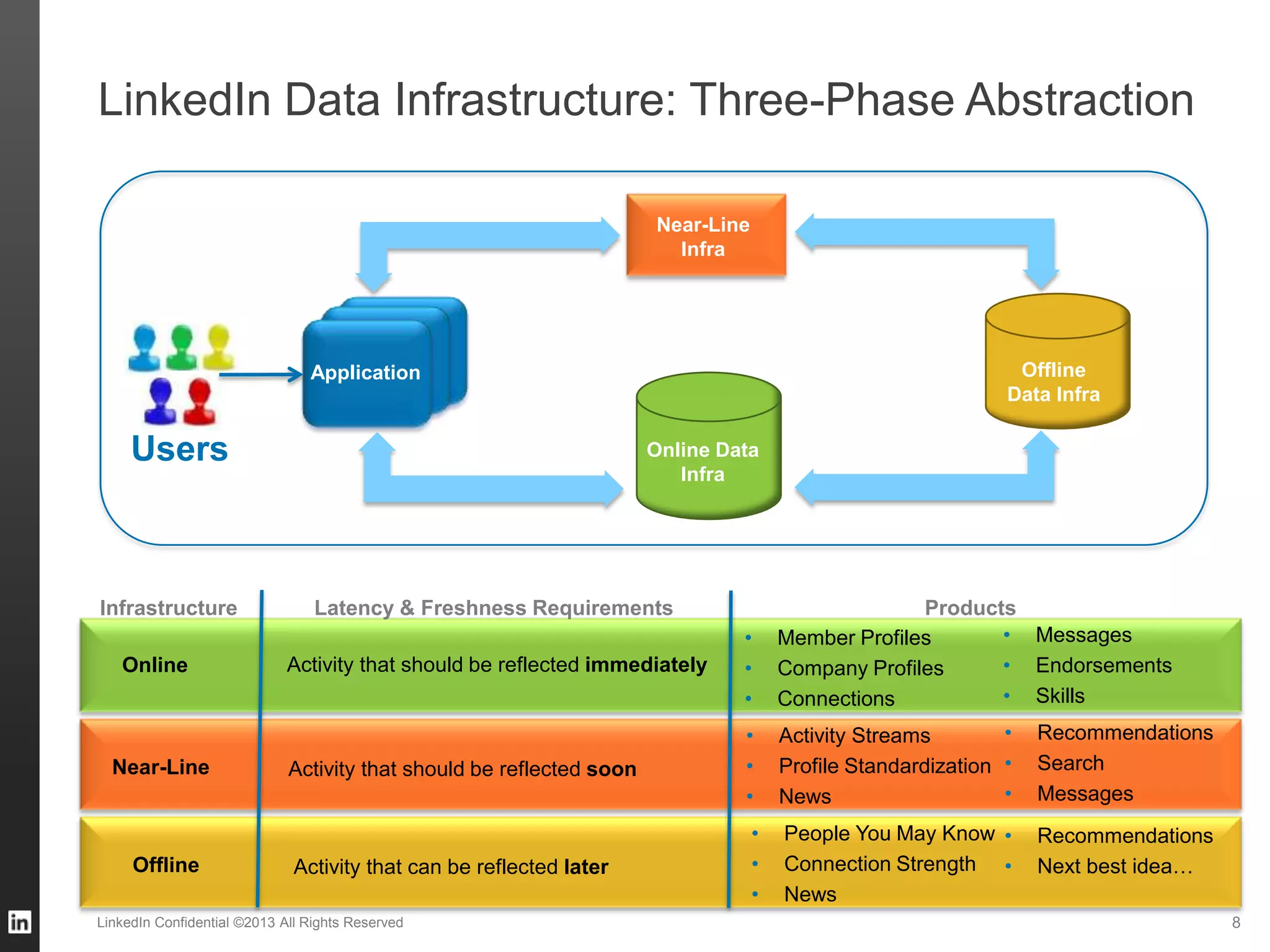
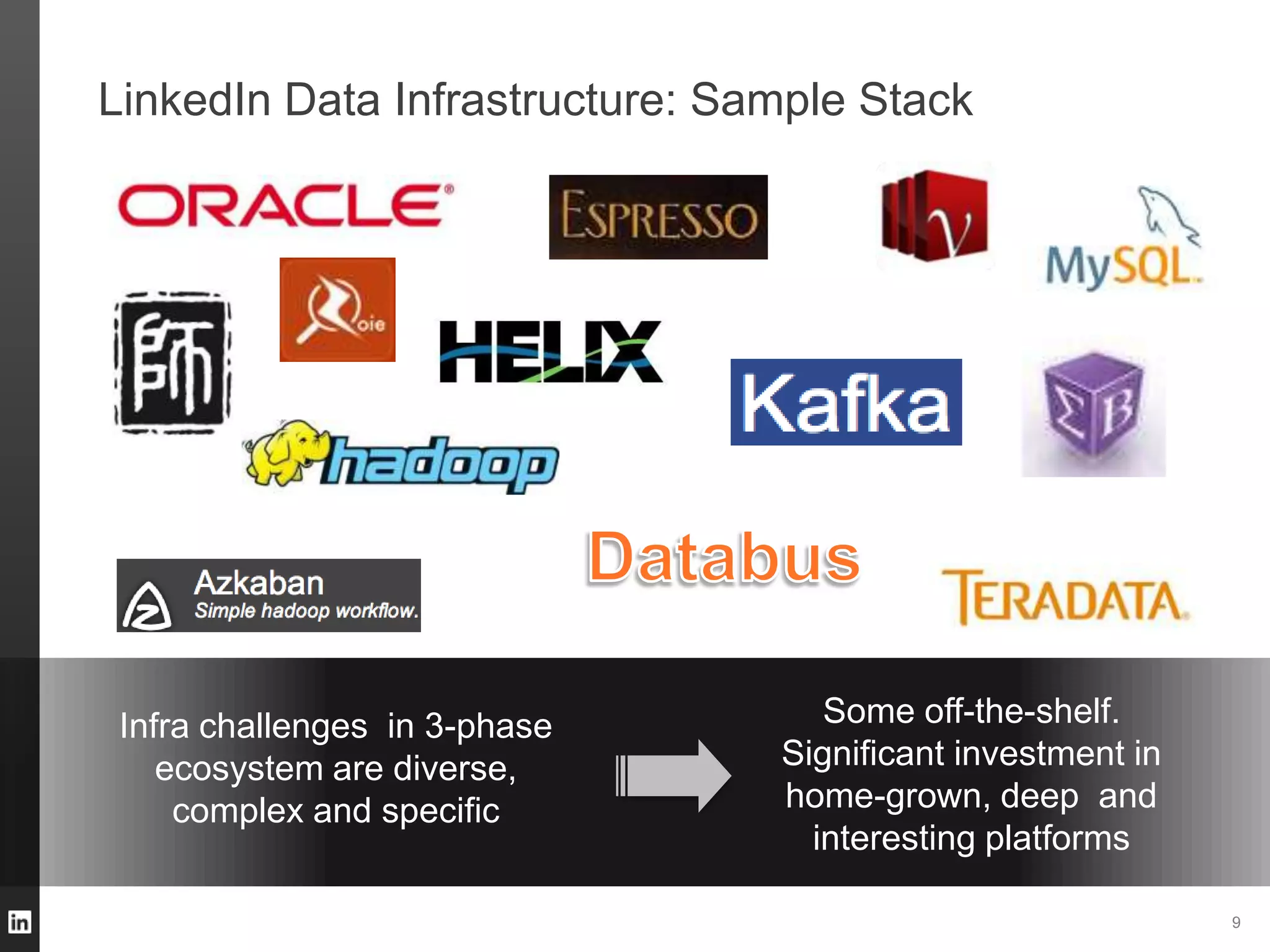
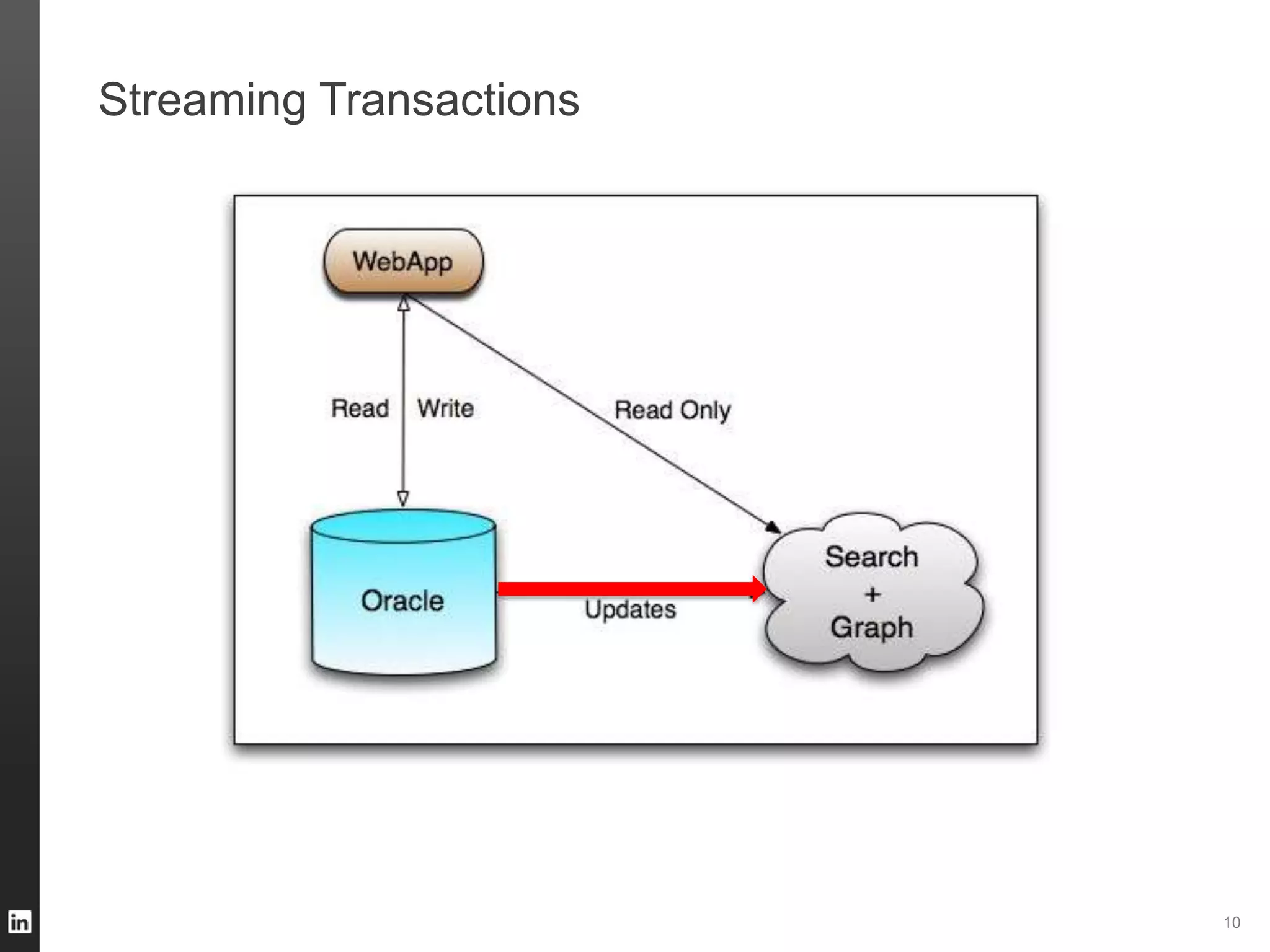

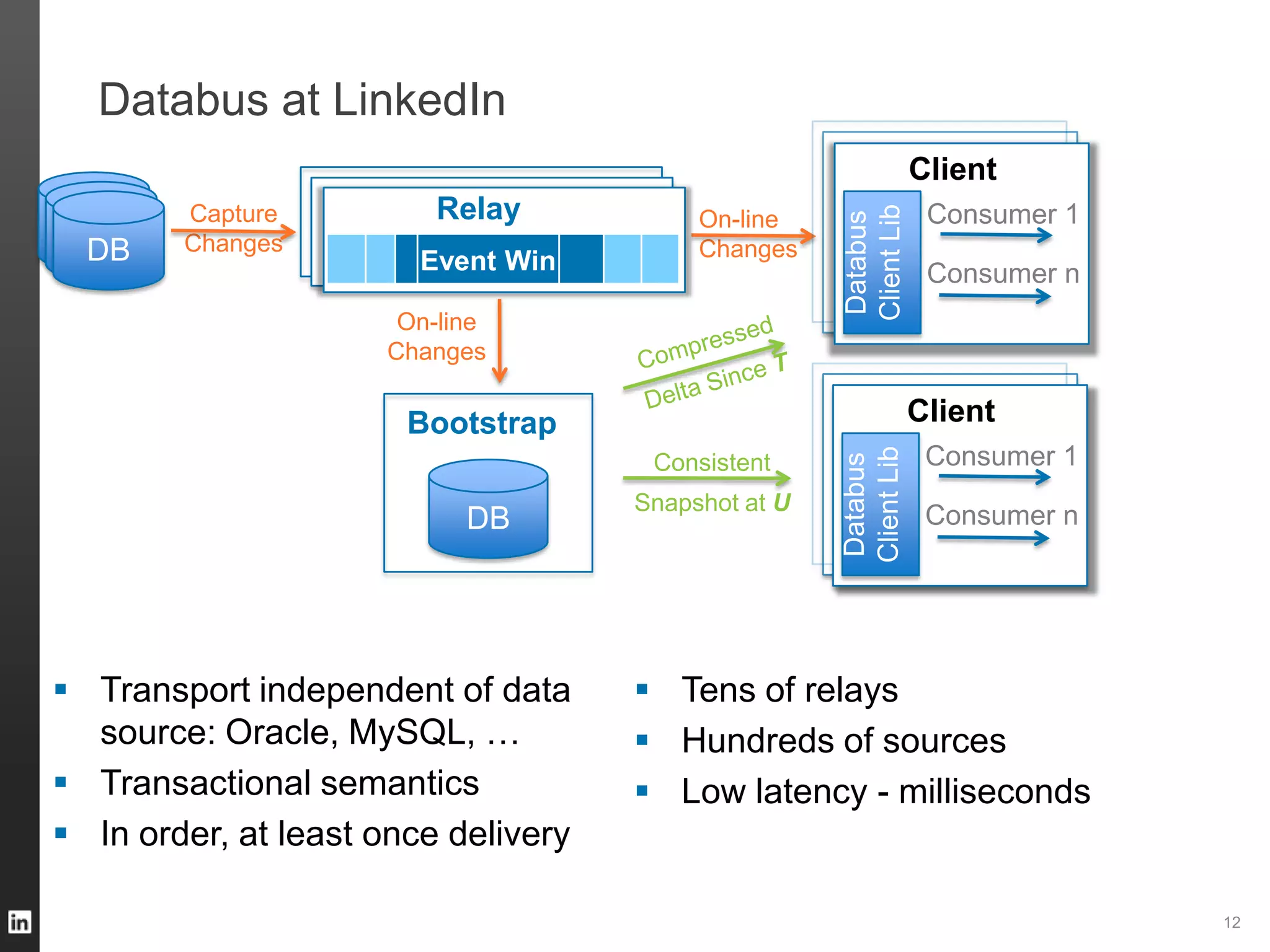
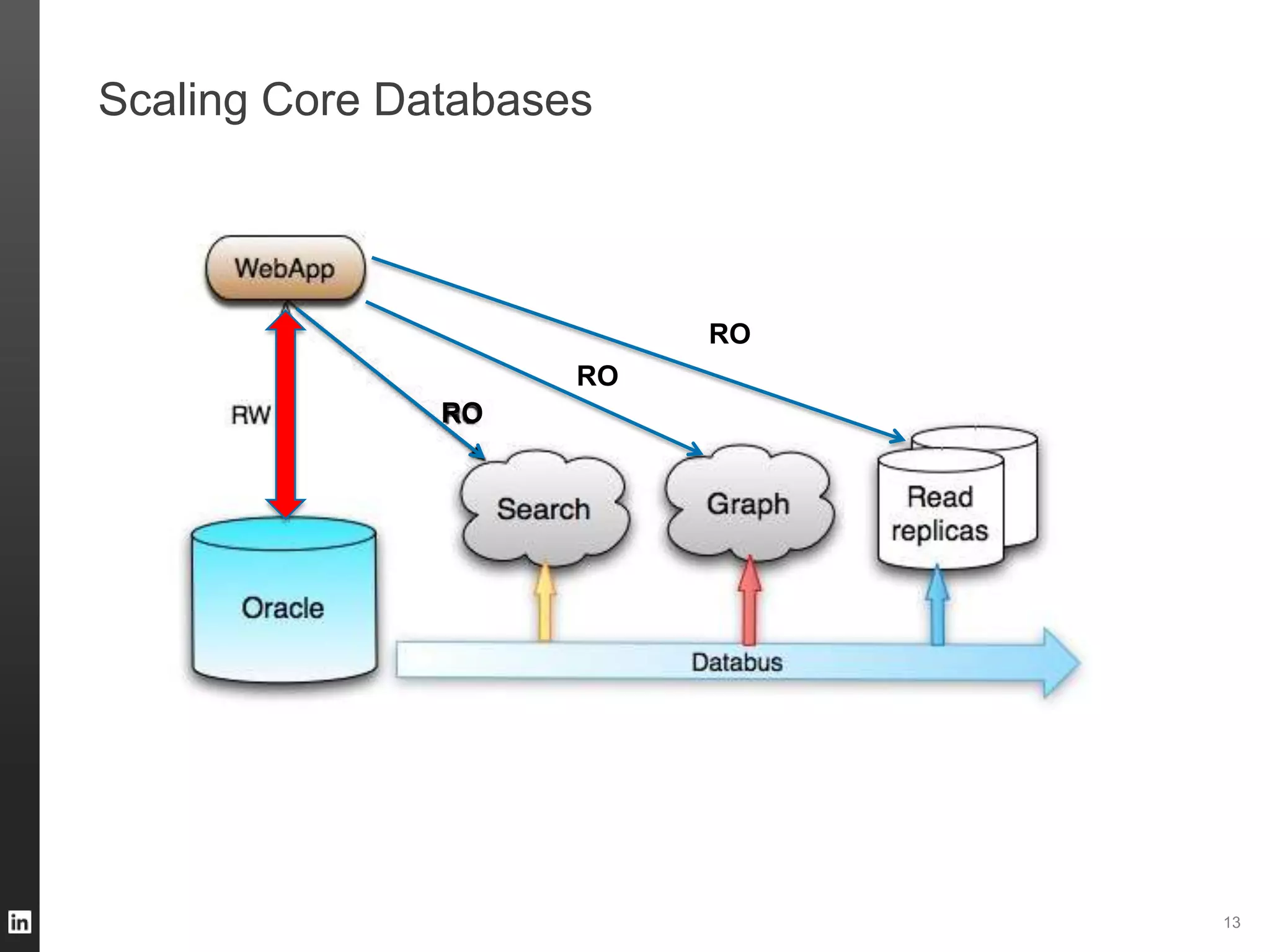

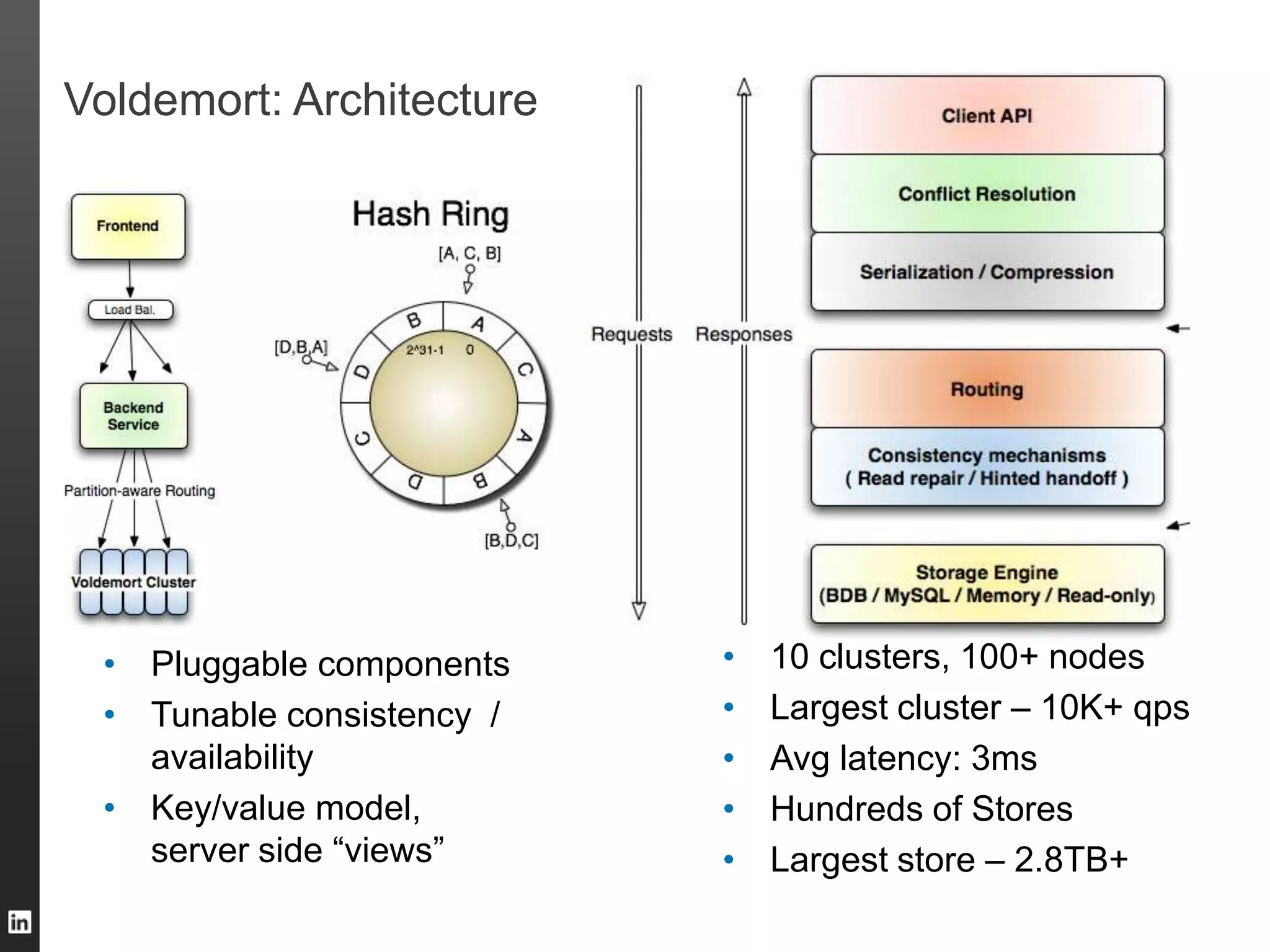
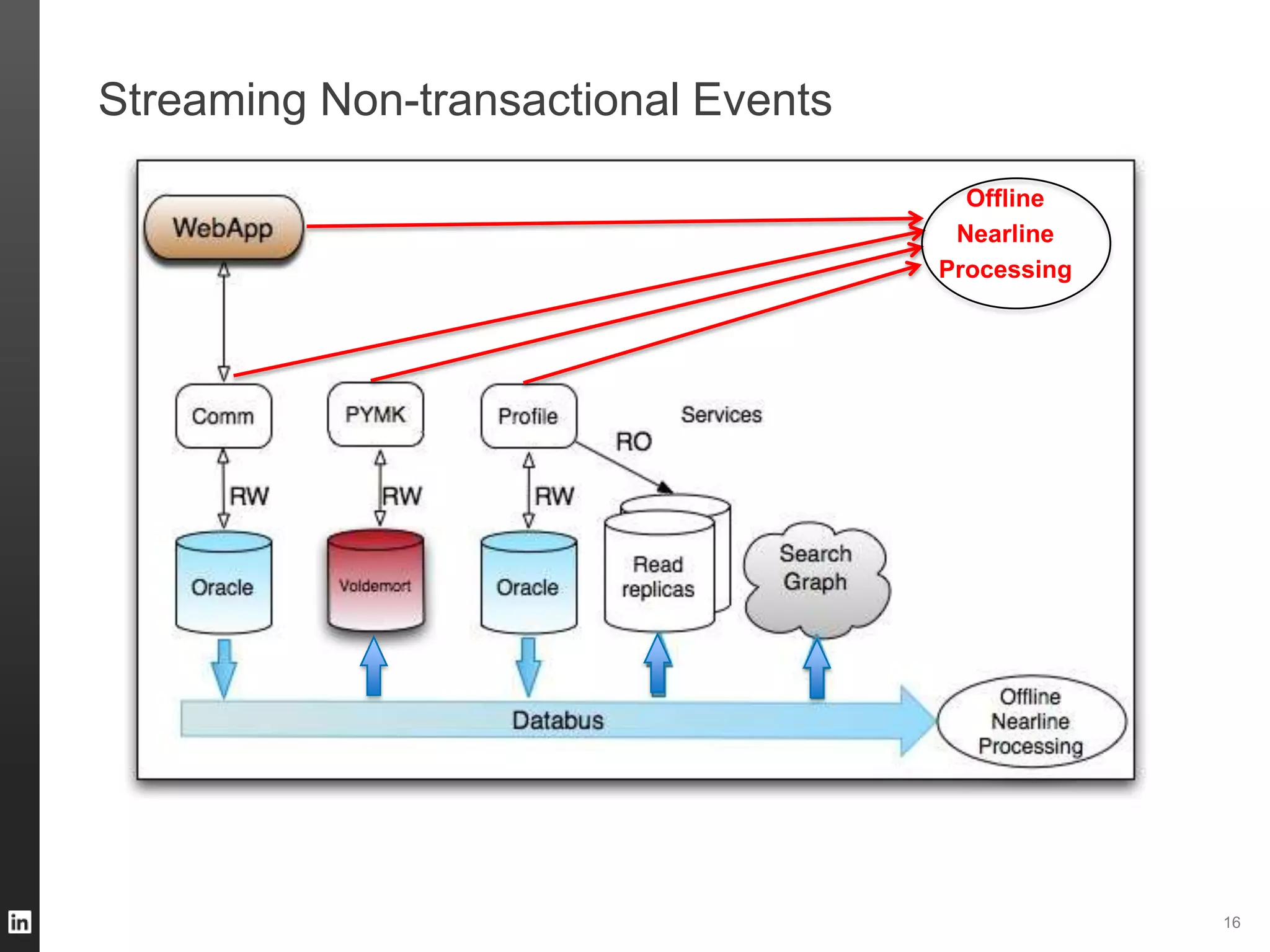

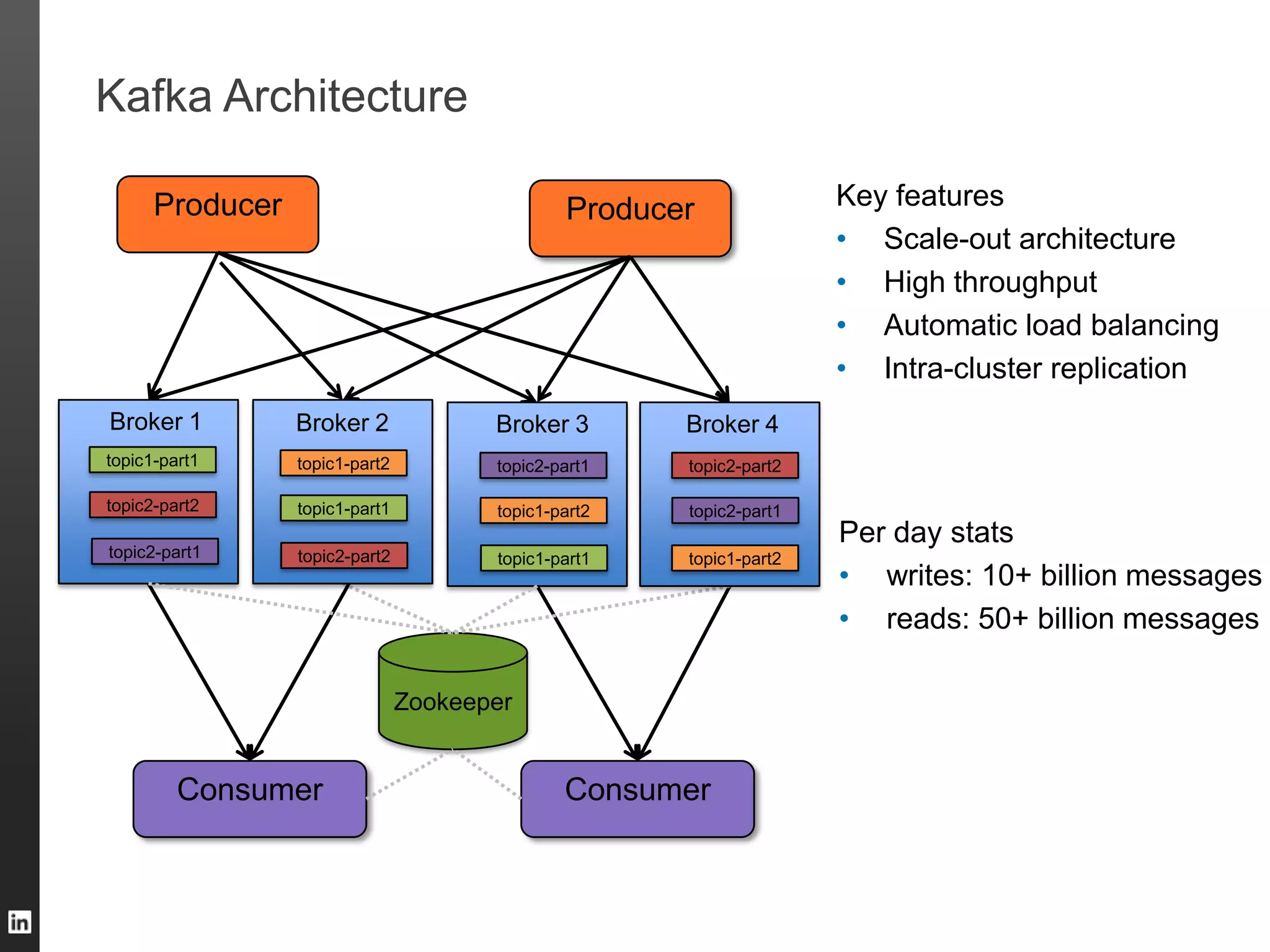
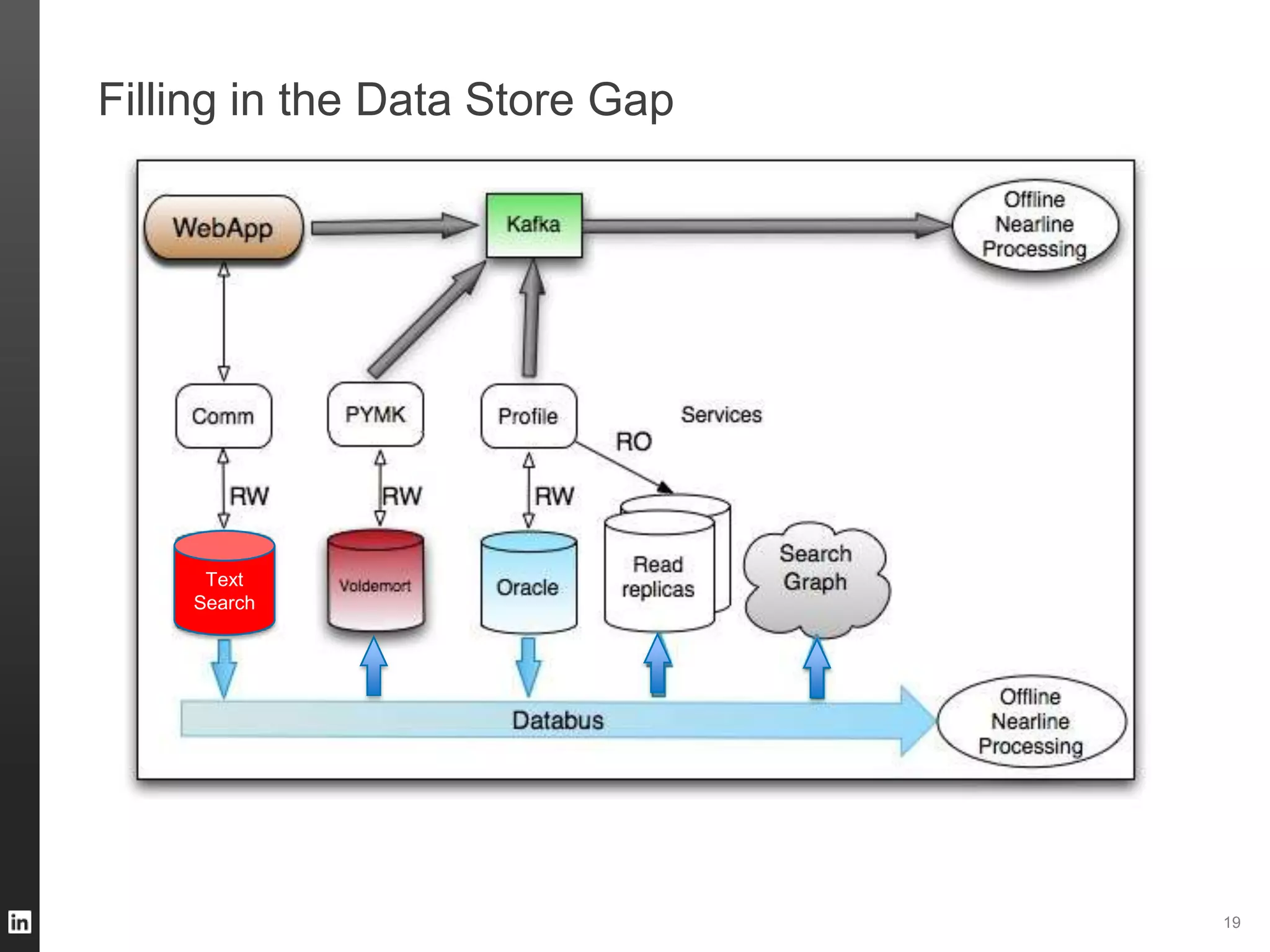

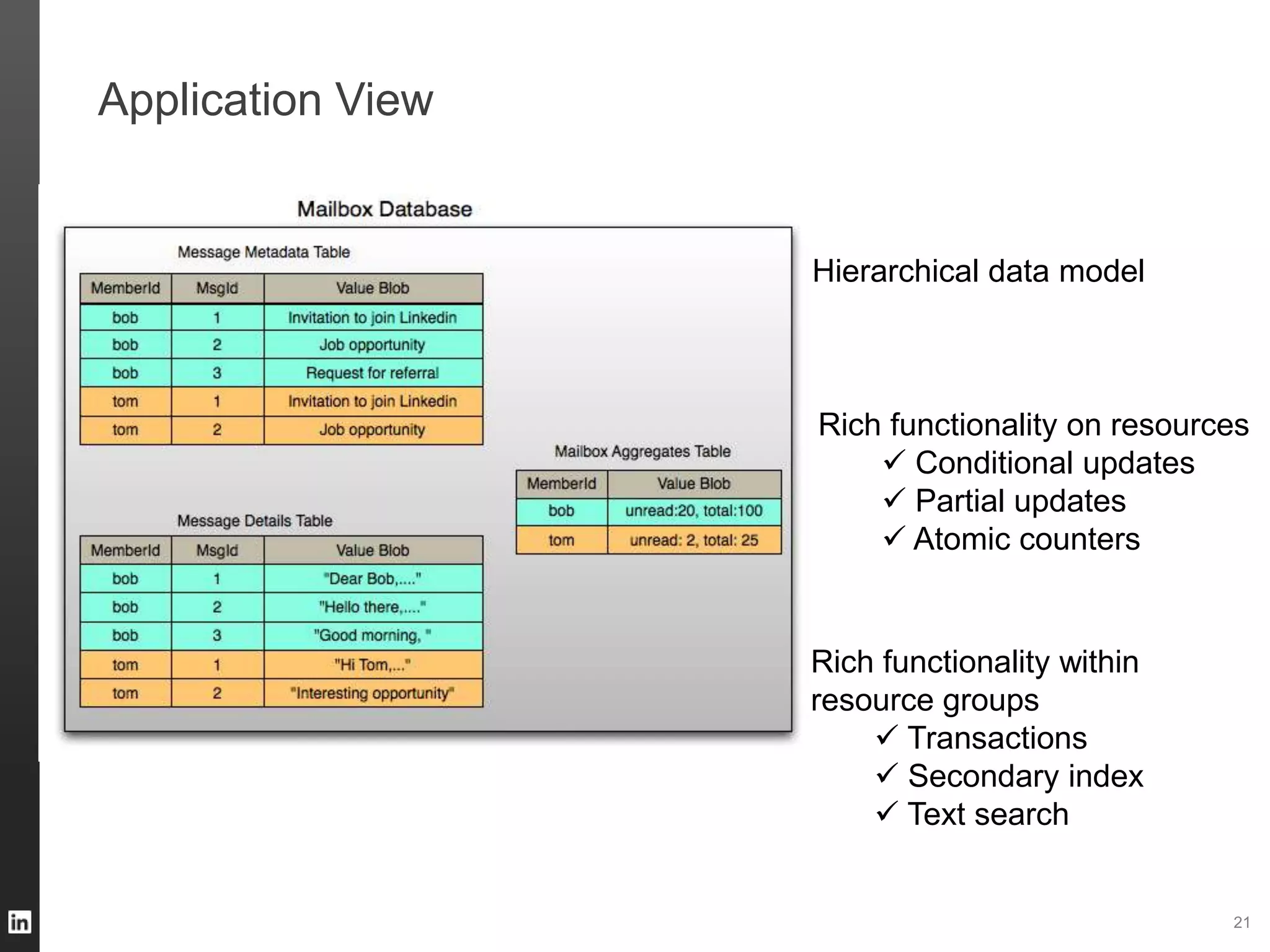
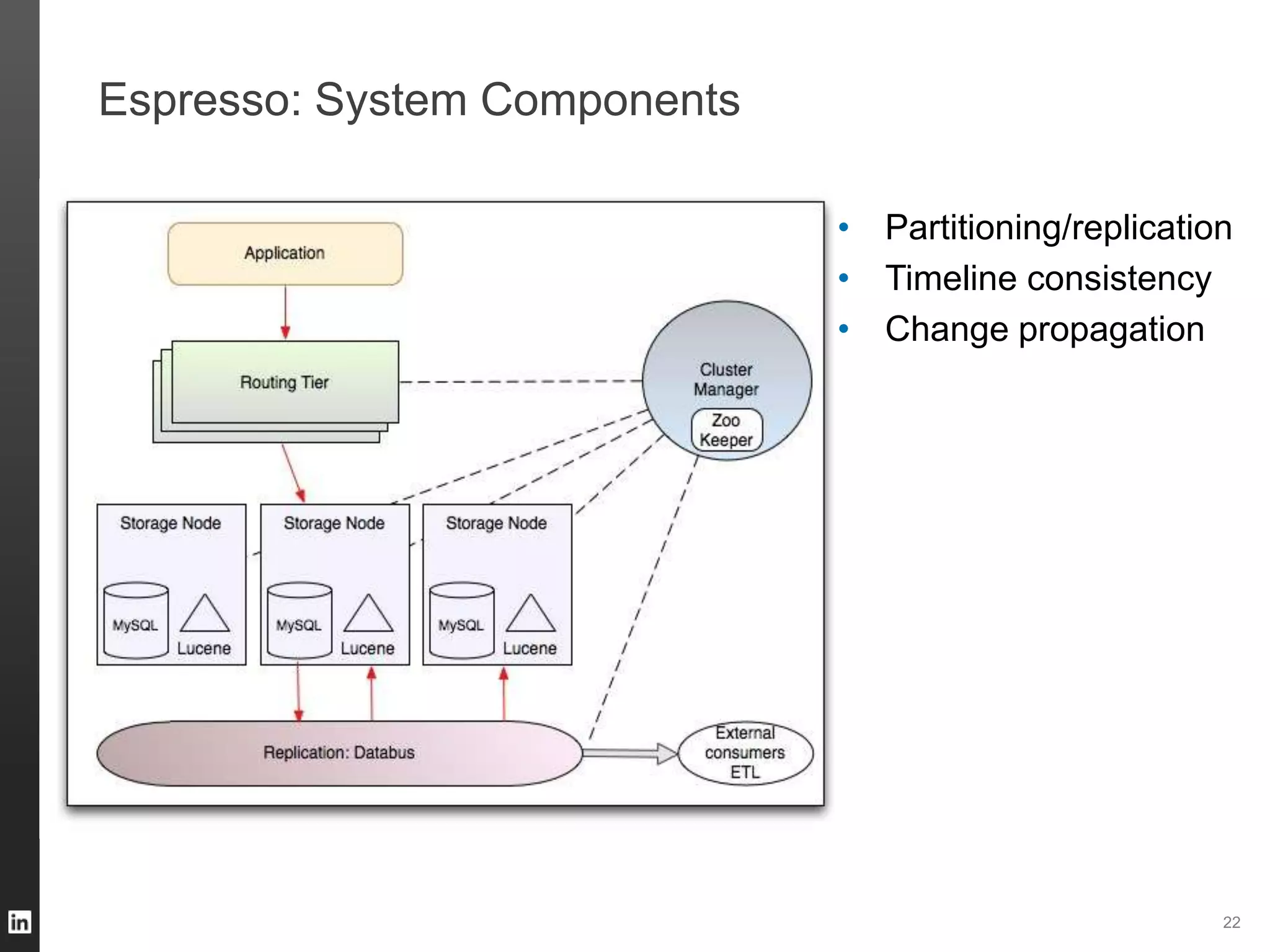
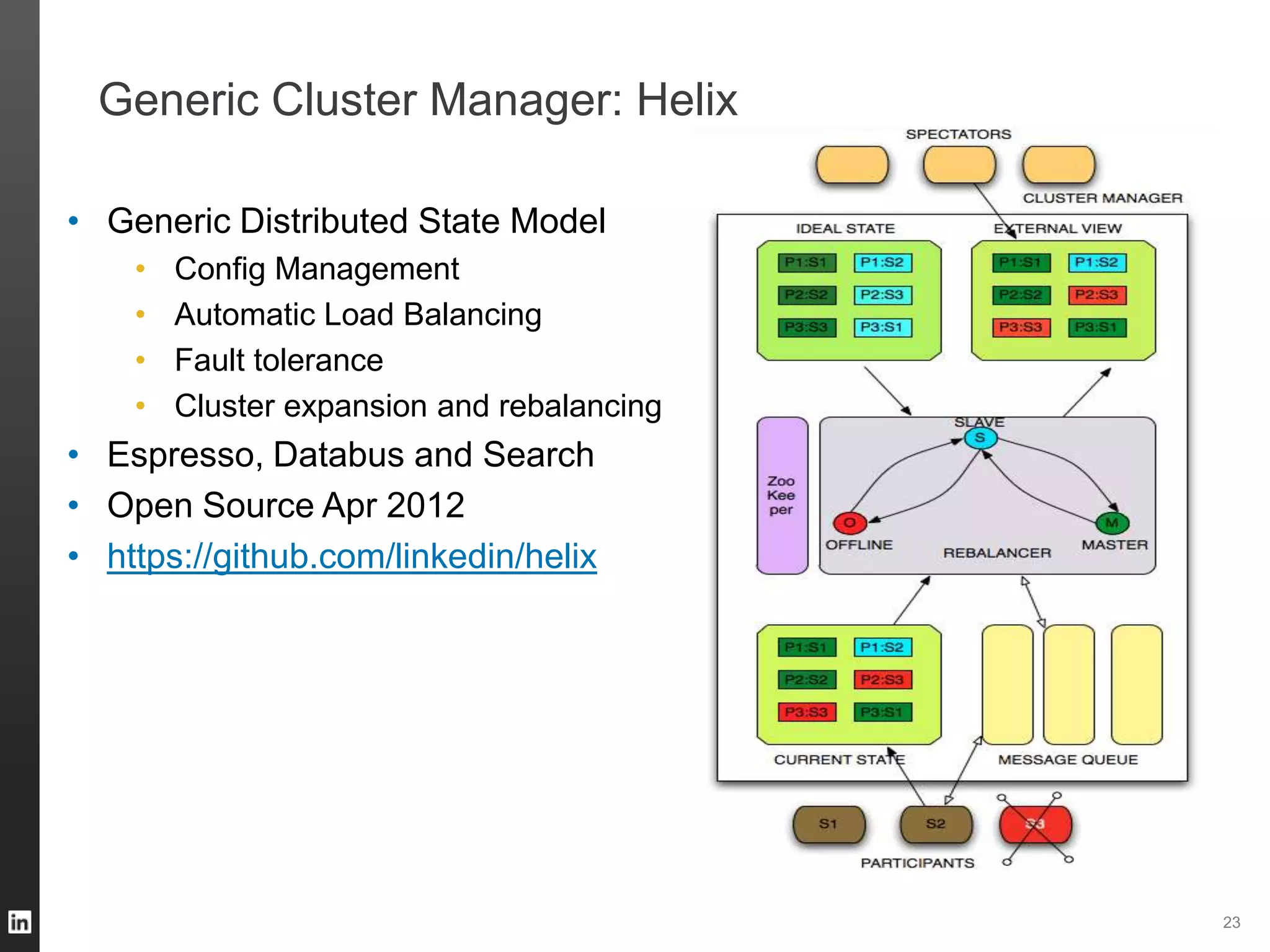




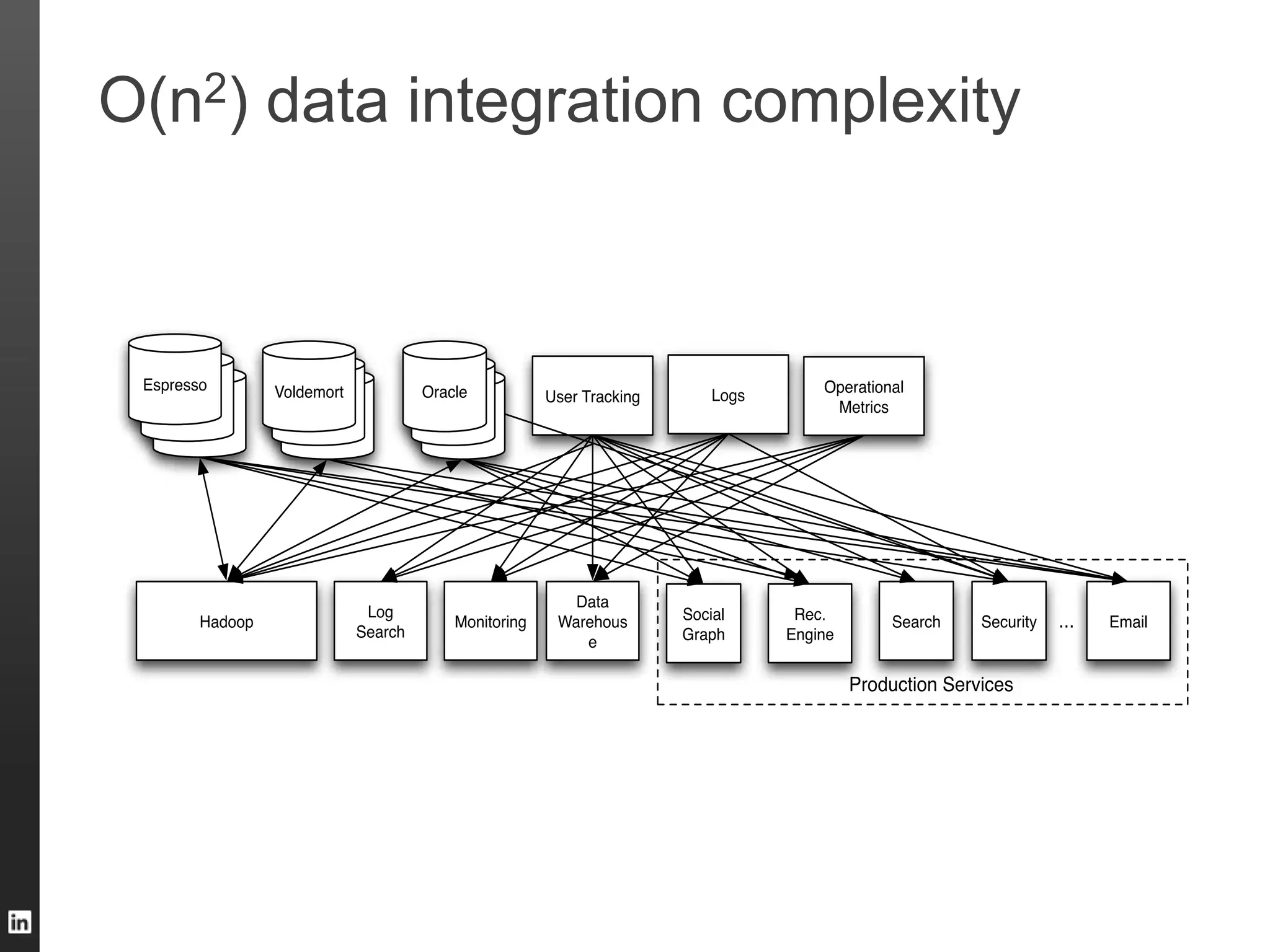
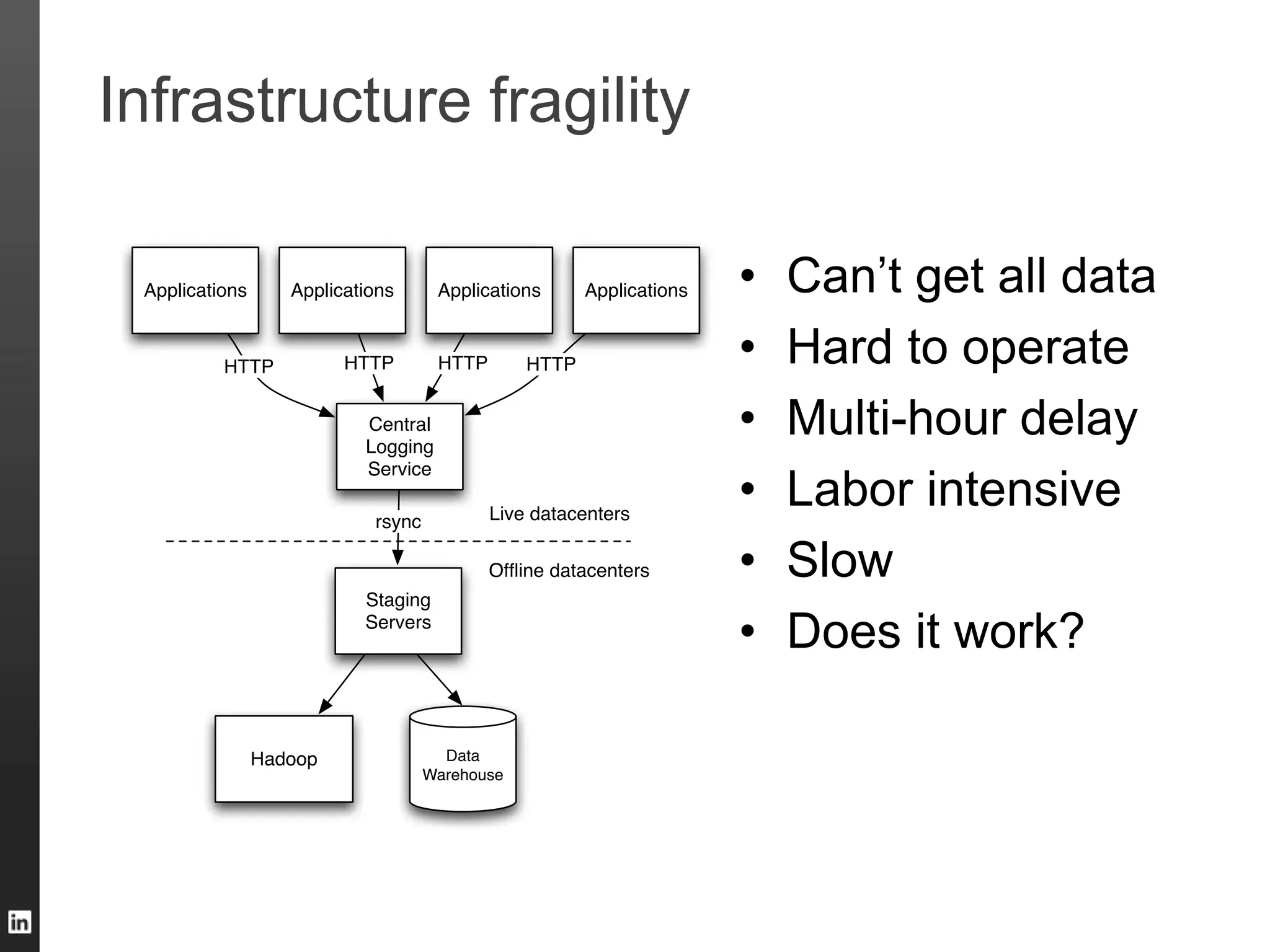
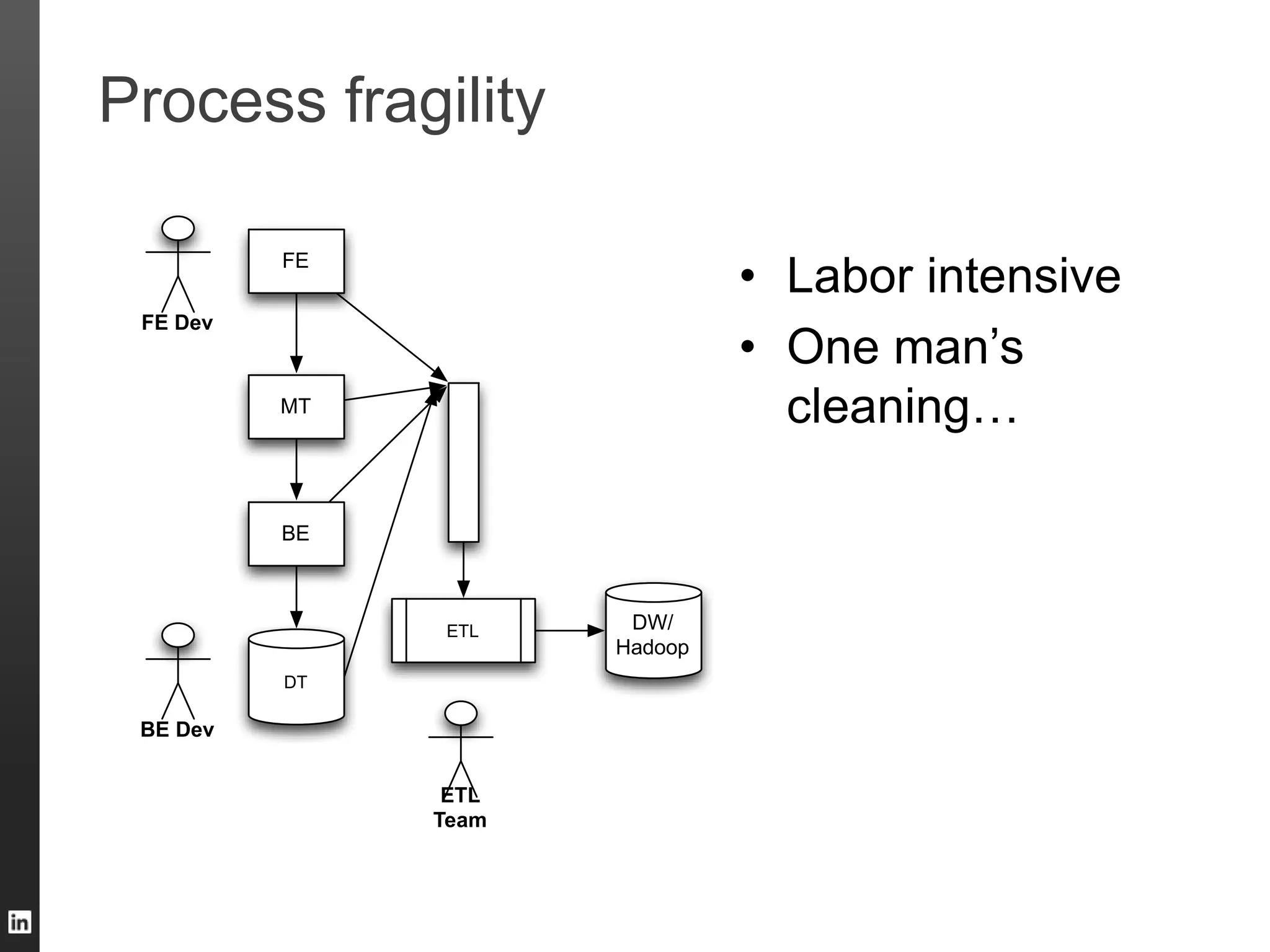
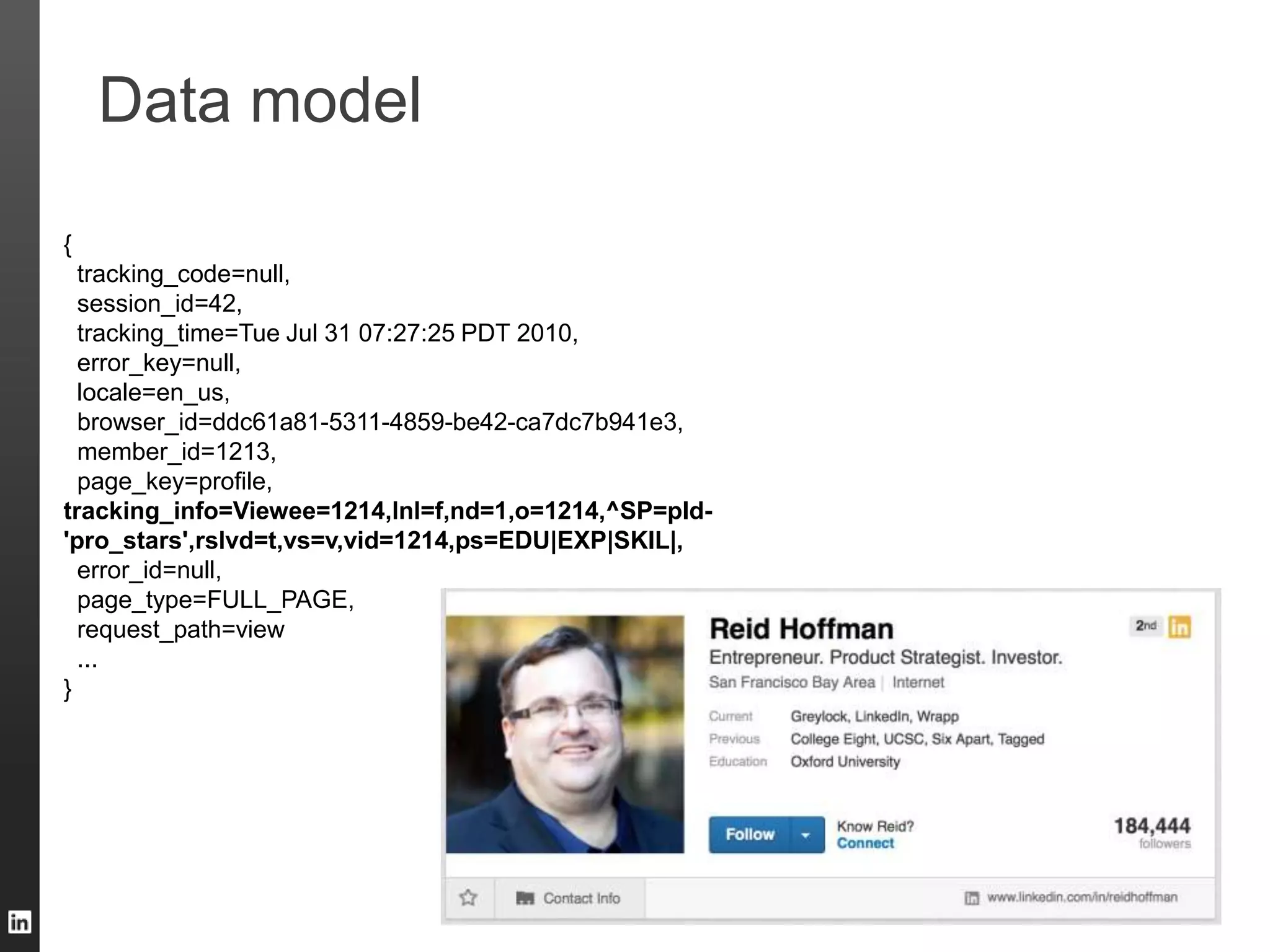
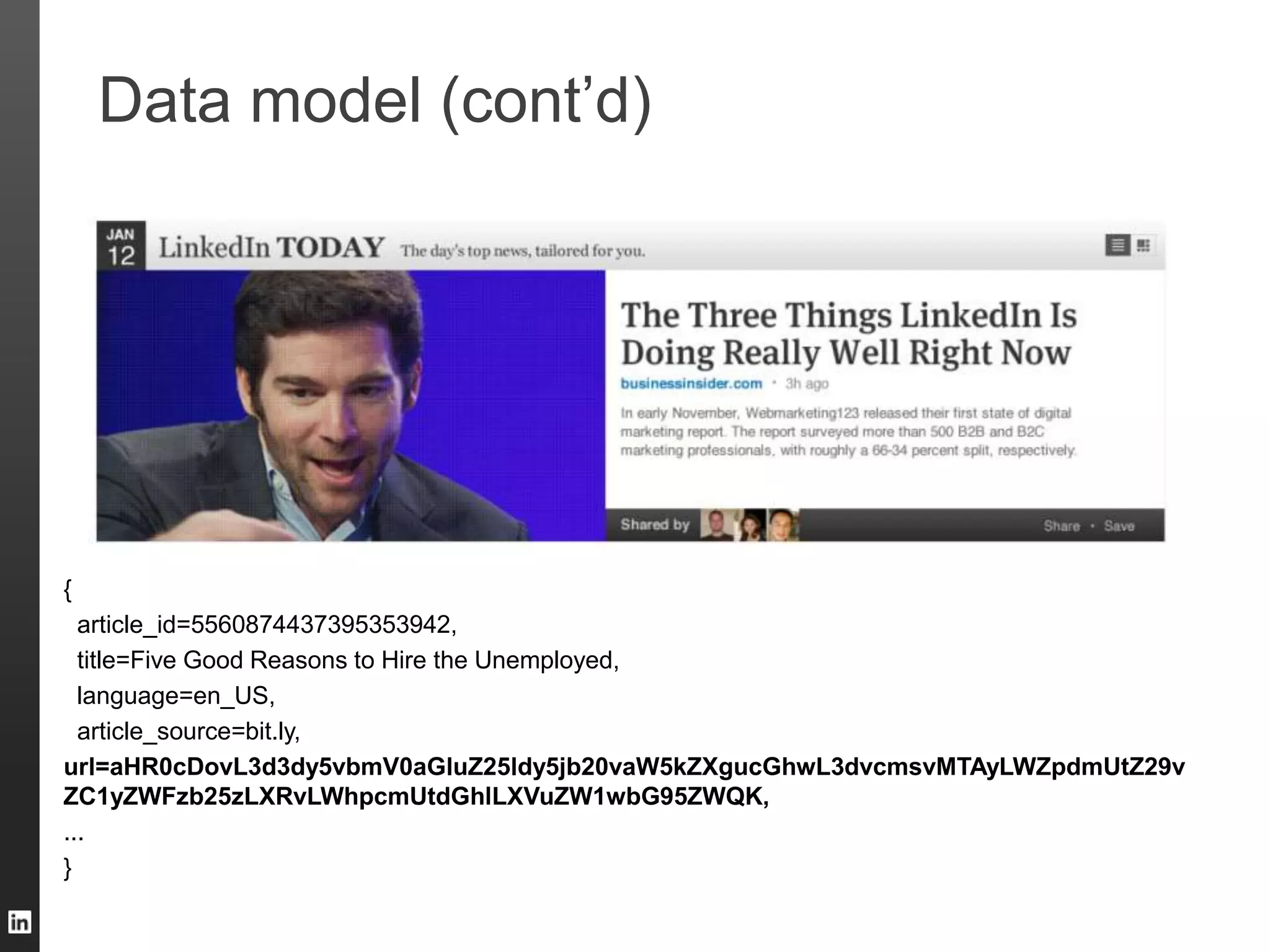


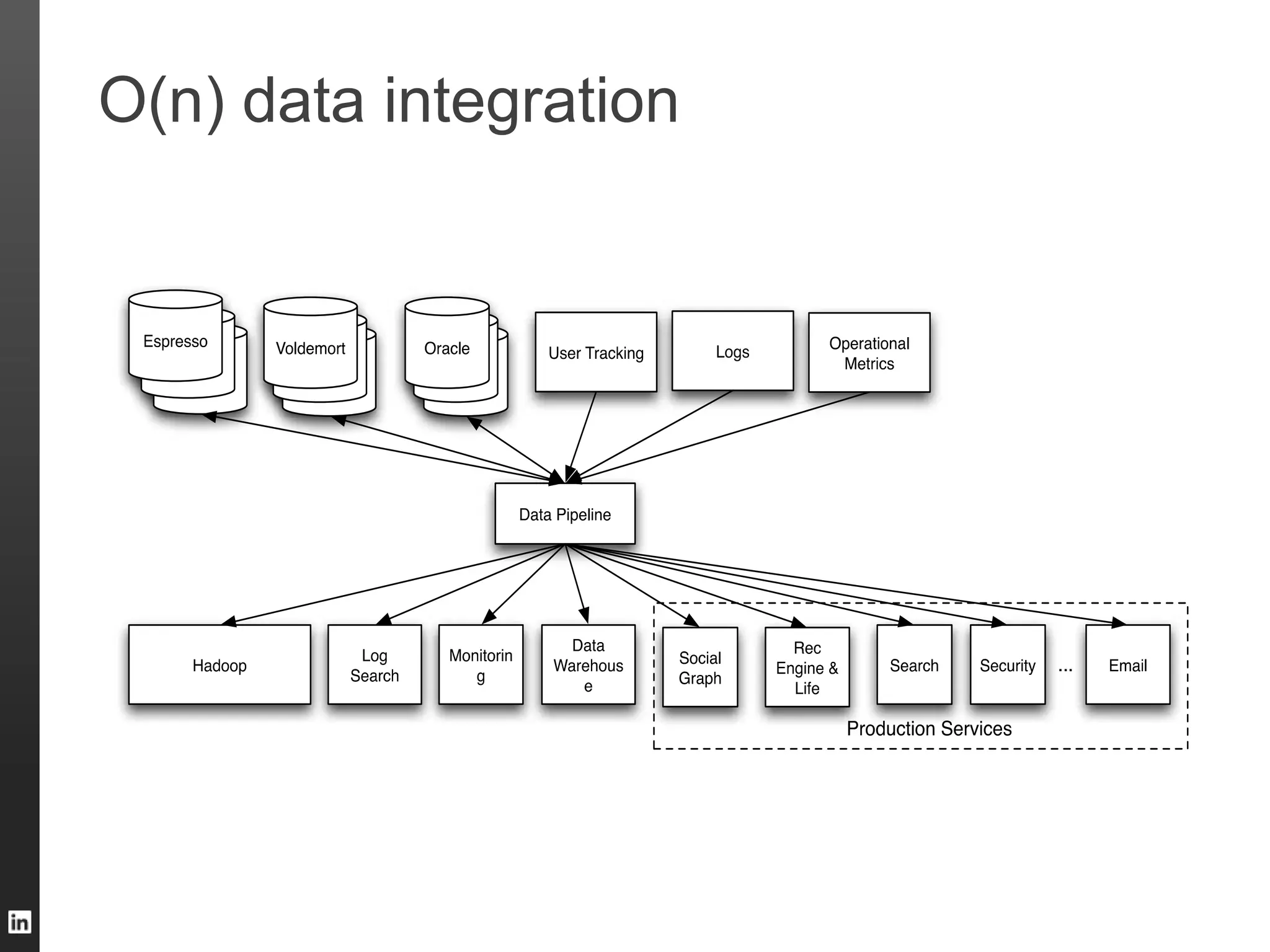
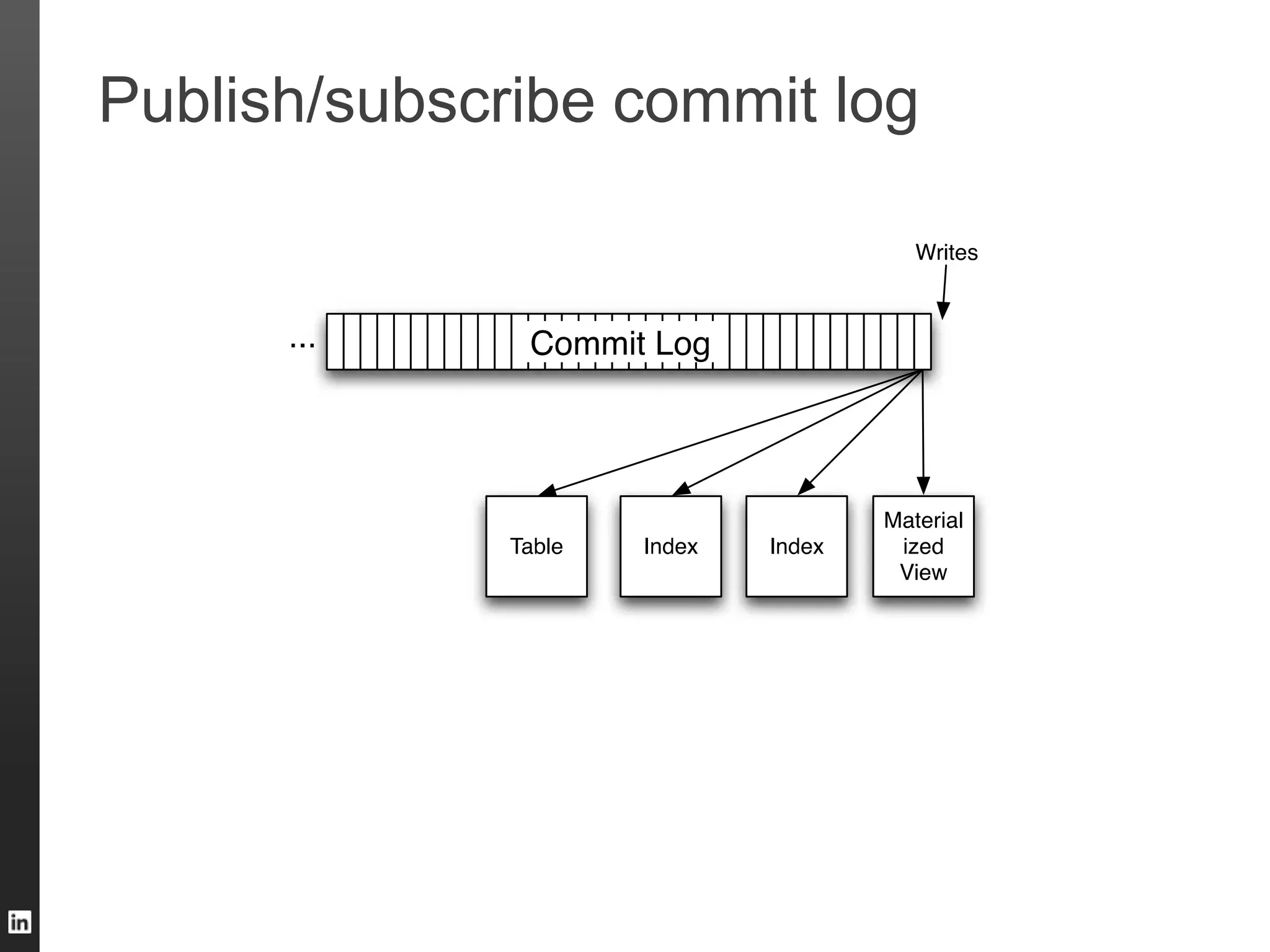




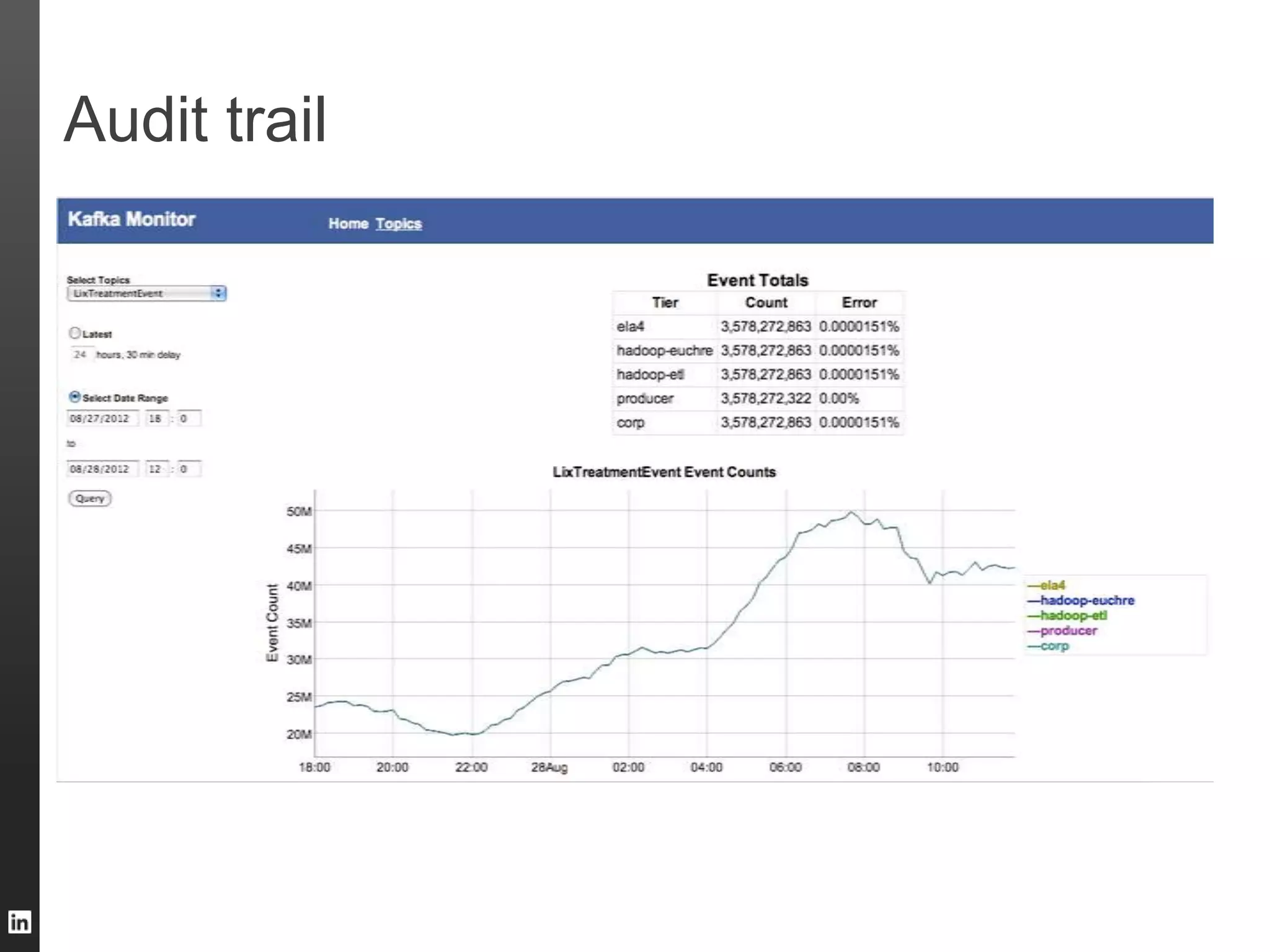




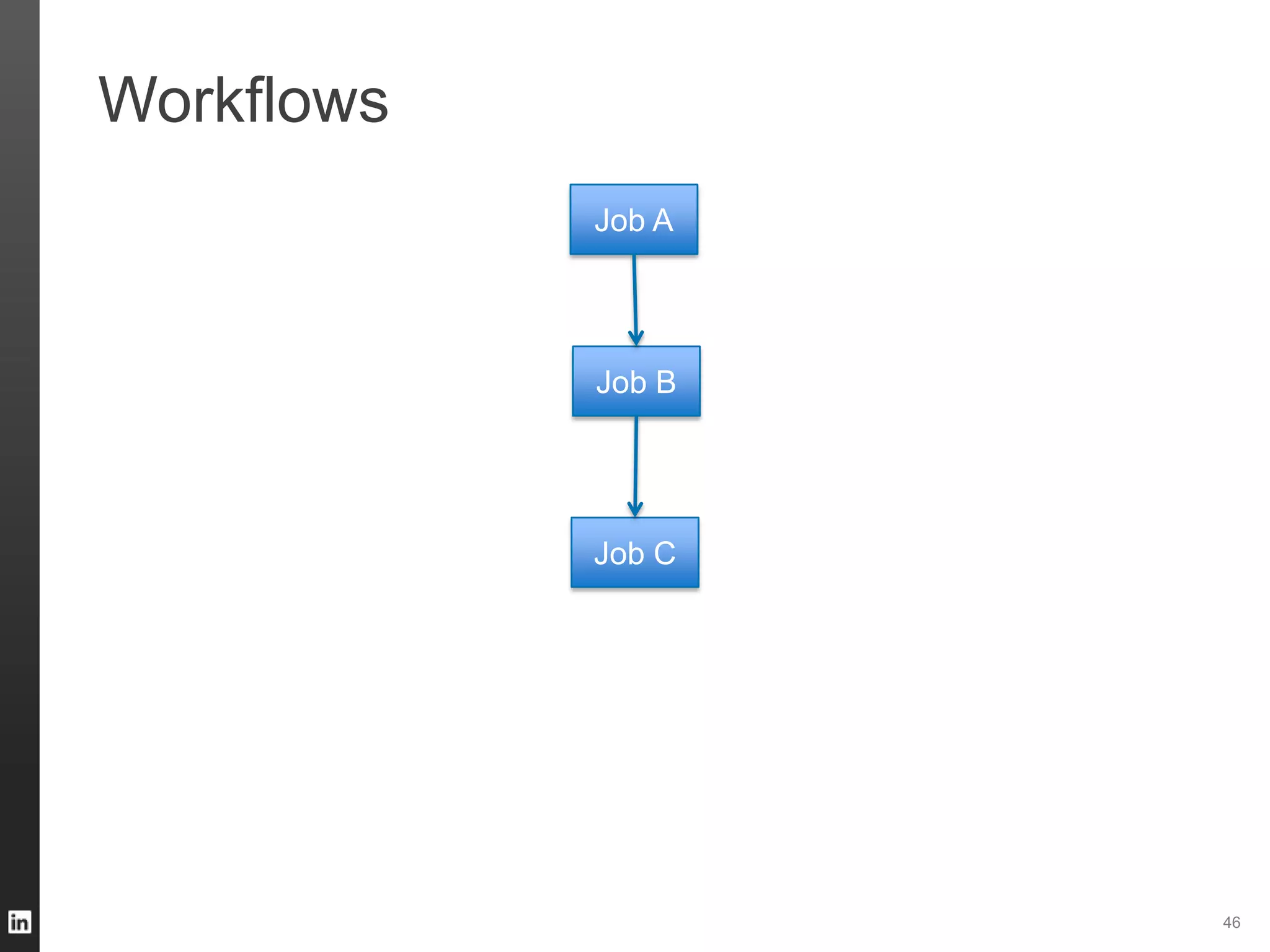
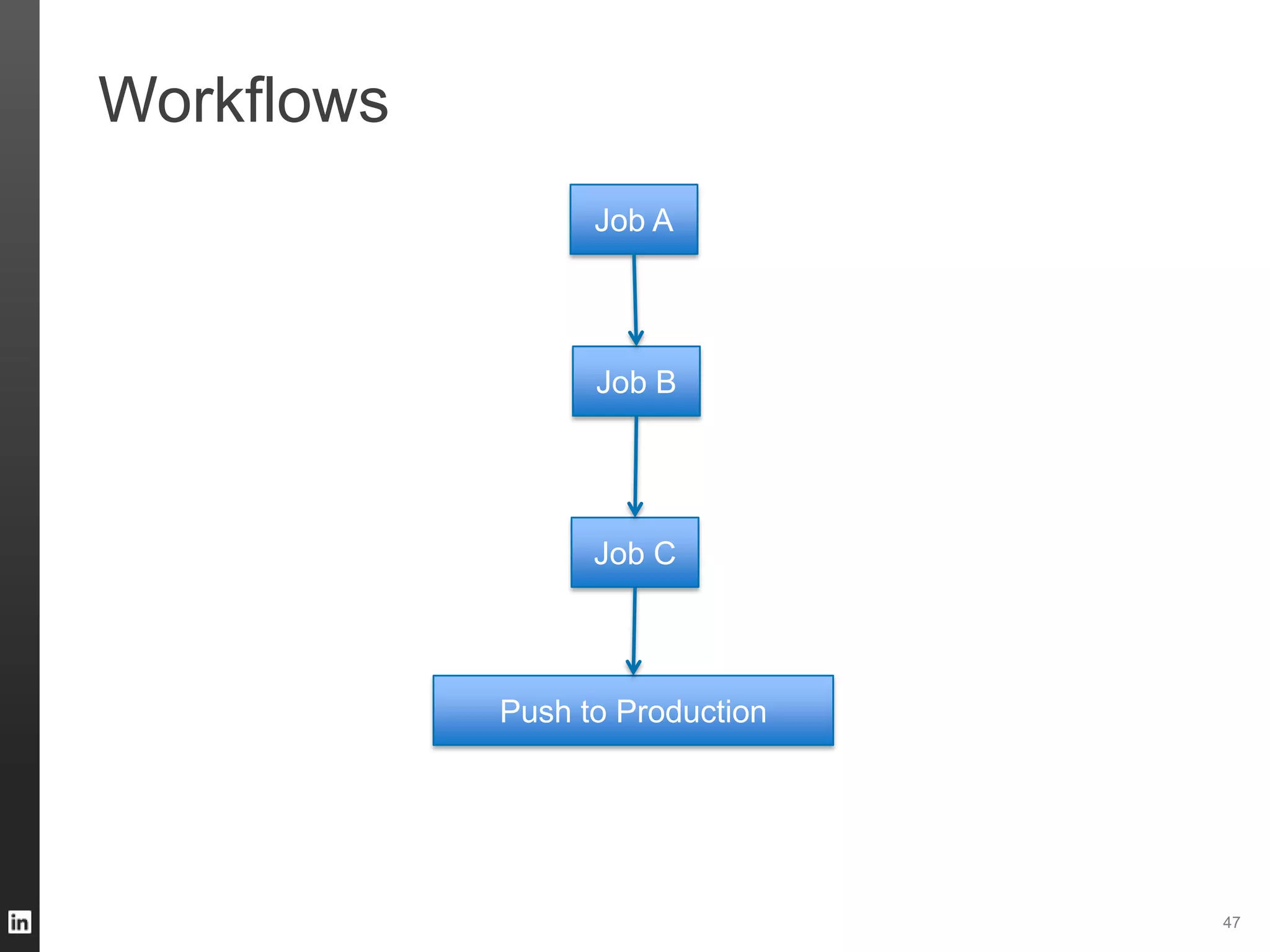
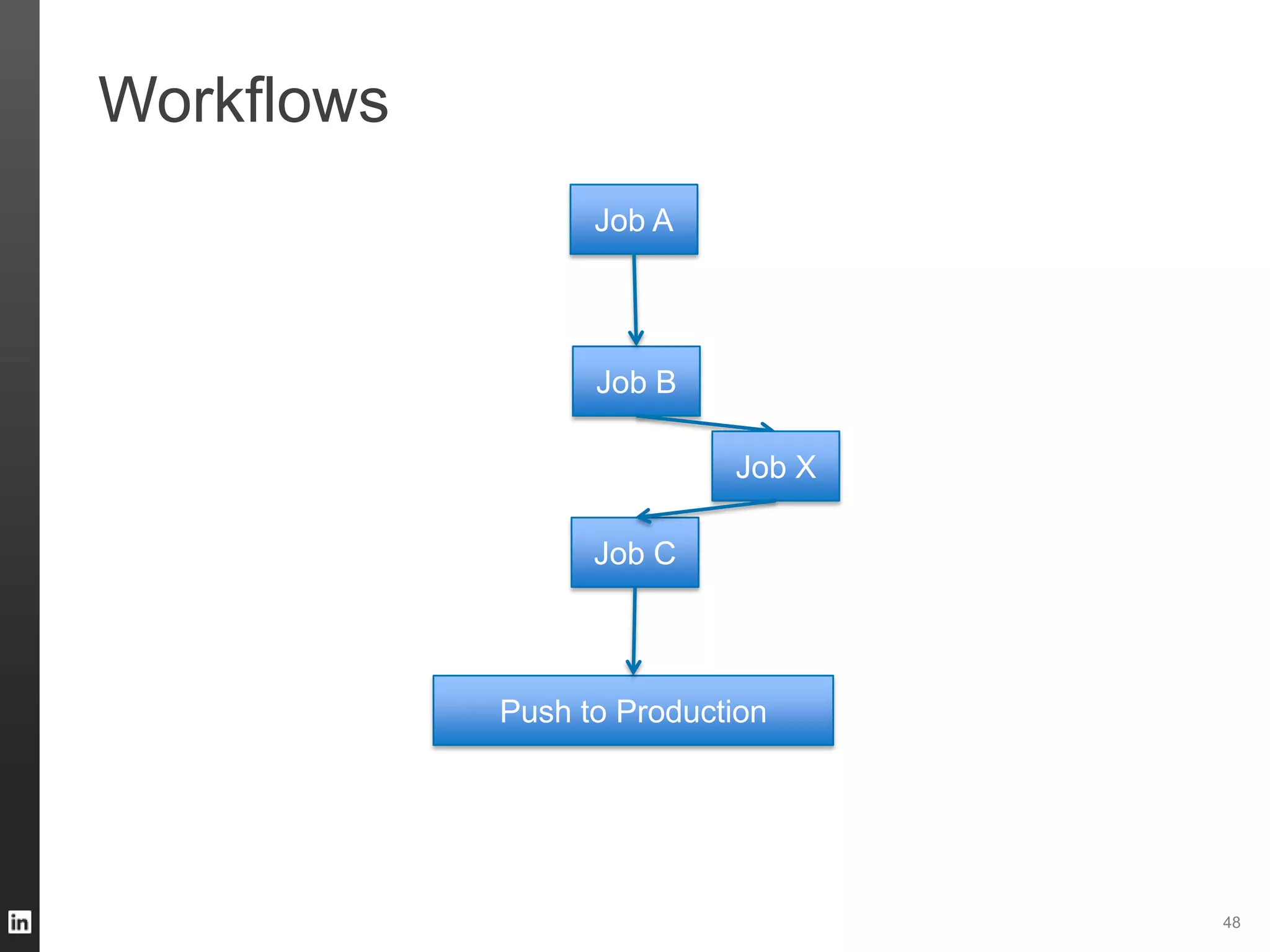
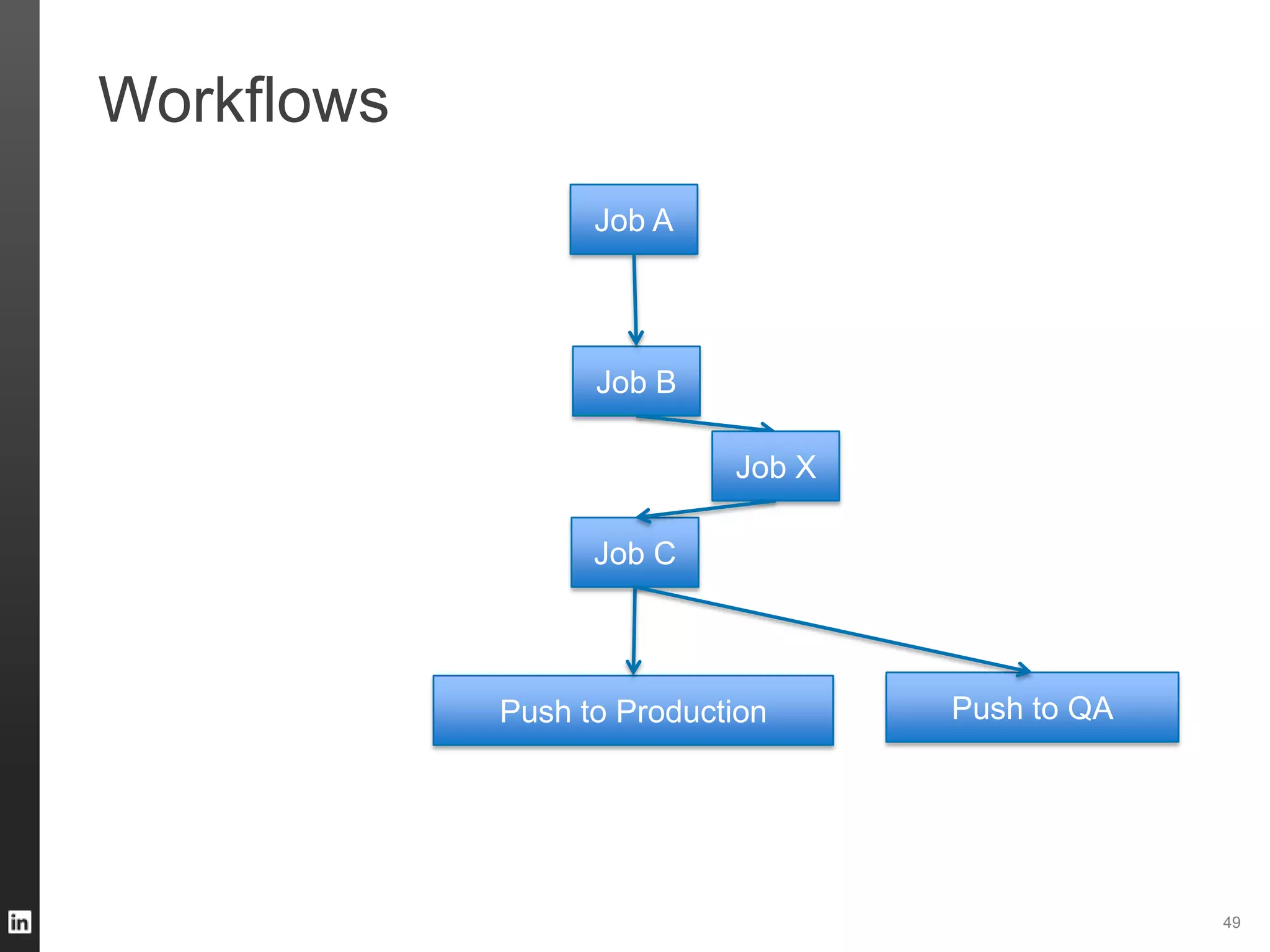


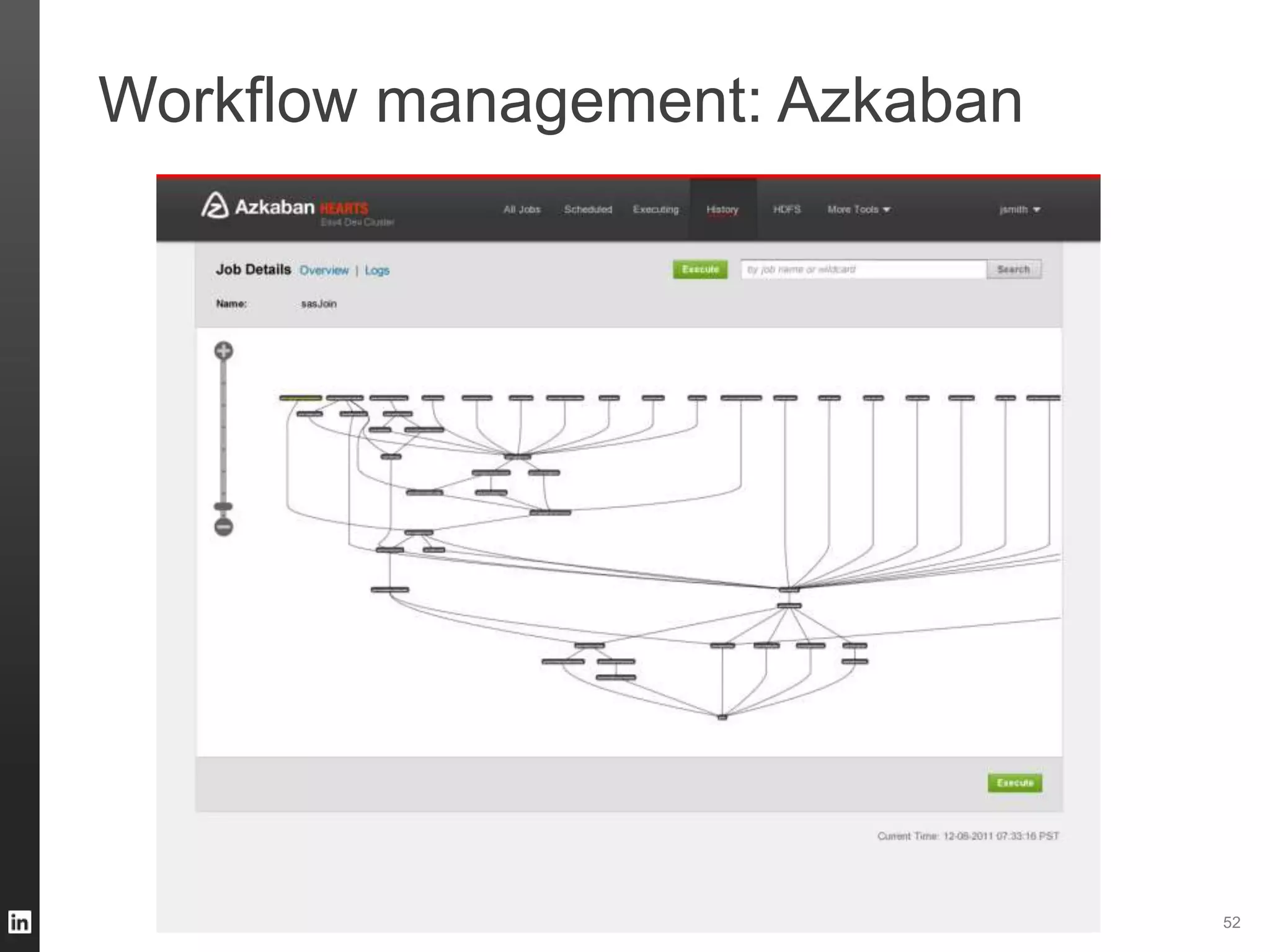
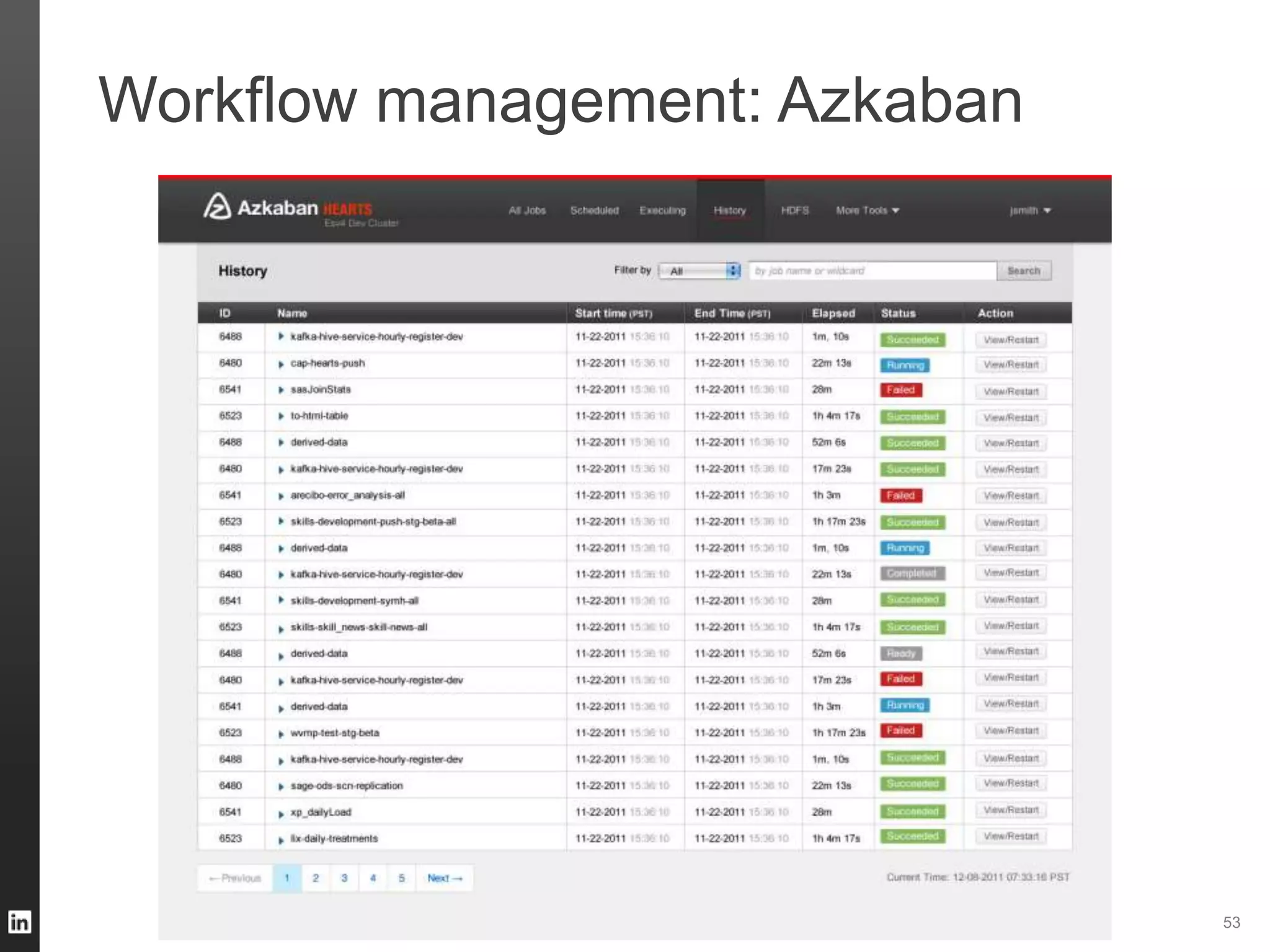

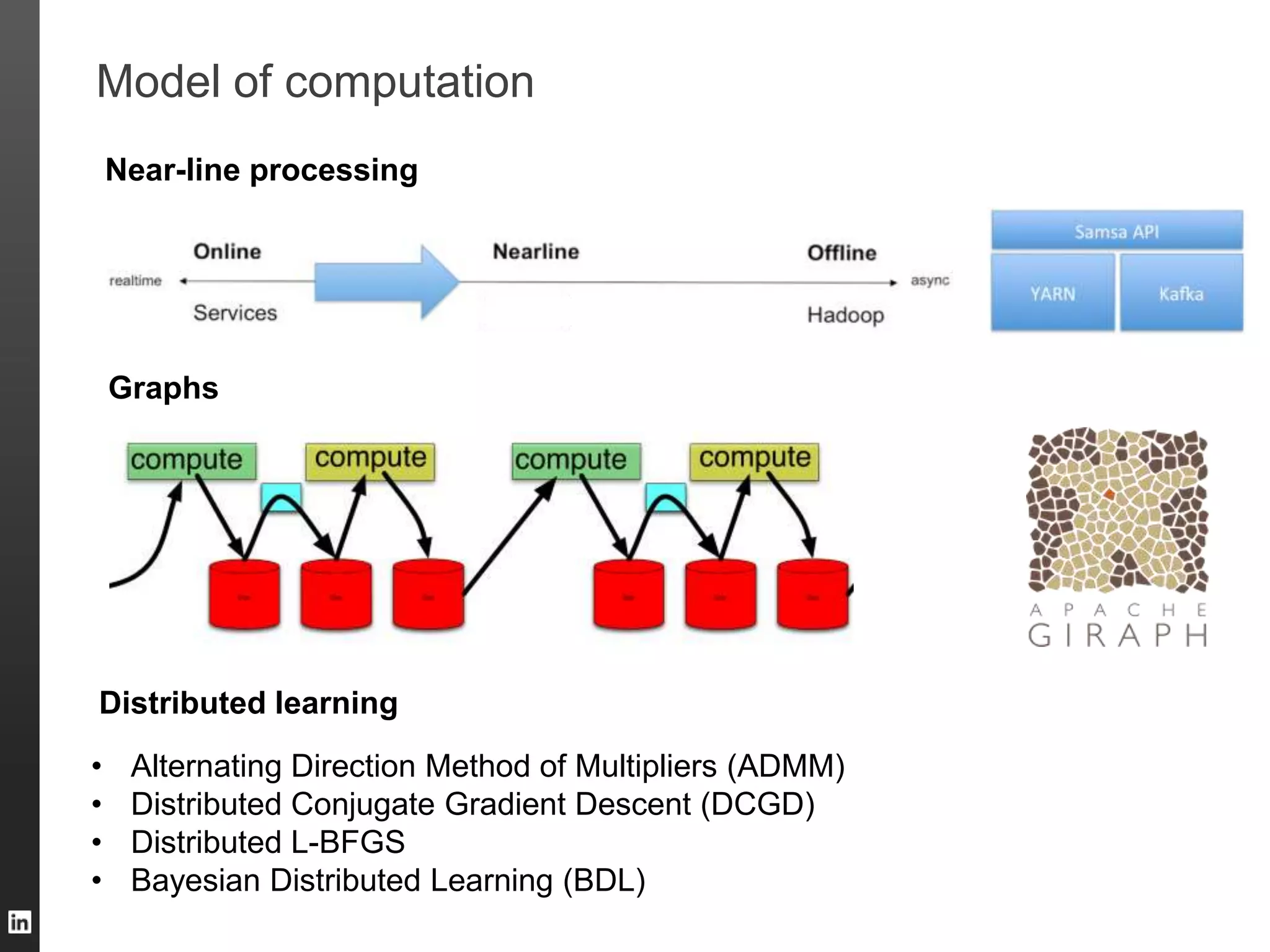
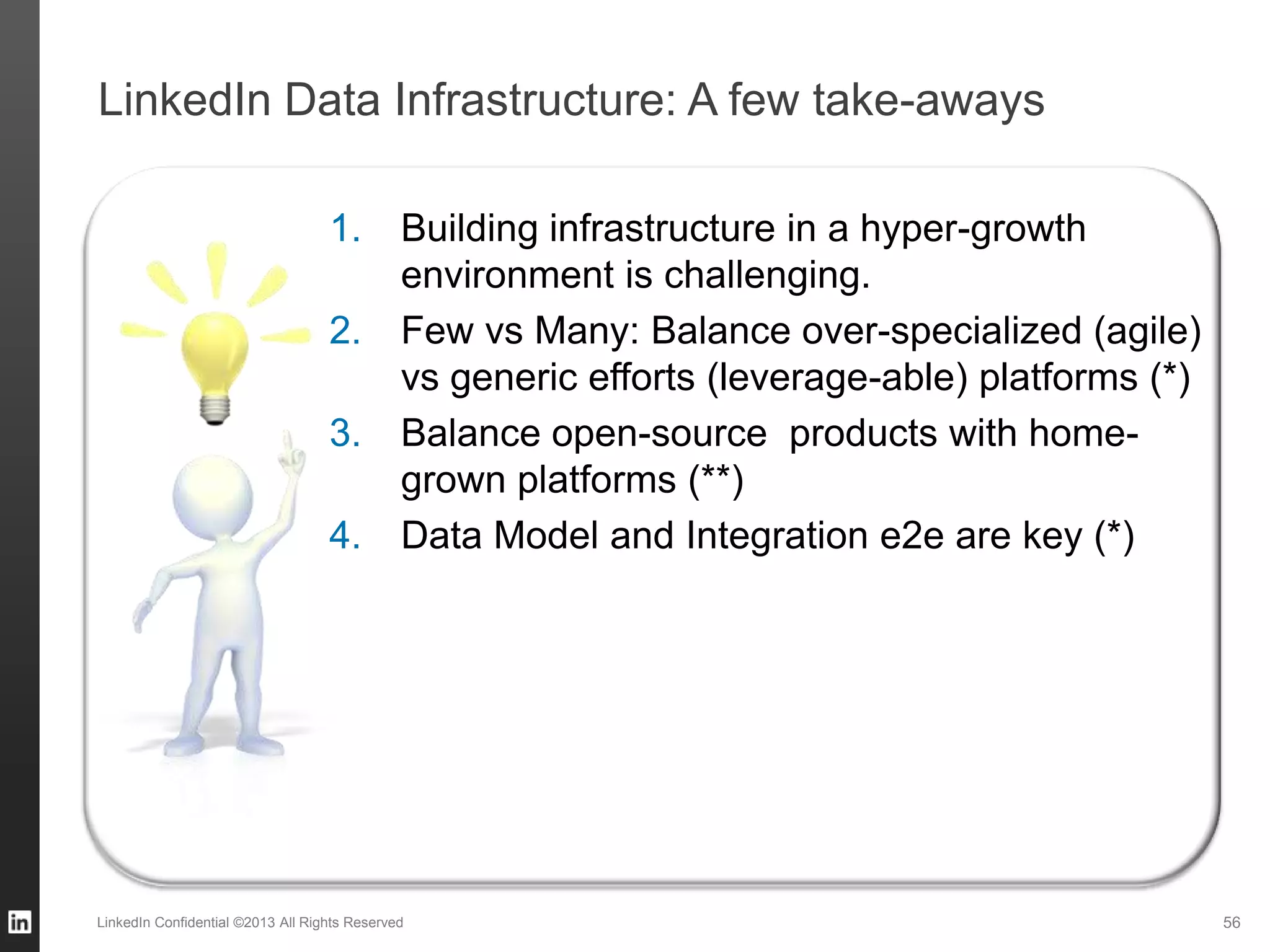


The document outlines LinkedIn's data infrastructure, detailing its online, near-line, and offline data processing systems, and addressing the challenges and solutions in managing large datasets. It highlights components like Databus for consistent data changes and Kafka for messaging, while discussing workflow management and data integration issues faced by data scientists. Key takeaways emphasize the importance of balancing specialized and generic solutions for effective infrastructure in a rapidly growing environment.























































![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



































