Download to read offline






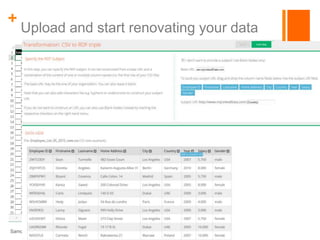
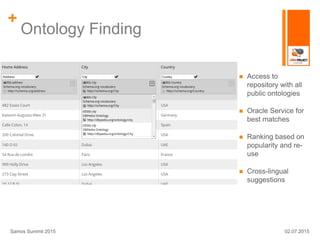







The LINDa project aims to simplify the publication of linked open data for non-experts, particularly targeting small and medium-sized enterprises (SMEs). It provides a set of tools for transforming, enriching, and publishing data while addressing shortcomings of existing solutions, such as user interface accessibility and integration with ontology services. The project is supported by a grant and aims to enhance the reach and usability of linked open data.
































































