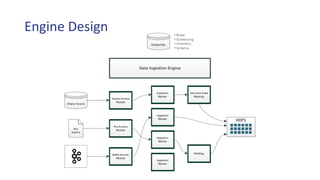
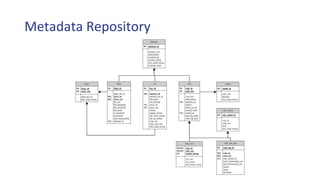
The document provides an overview of a data ingestion engine designed for big data. It discusses the motivation for the engine, including challenges with existing ETL and data integration approaches. The key aspects of the engine include a metadata repository that drives the ingestion process, access modules that connect to different data sources, and transform modules that process and mask the data. The metadata-driven approach provides benefits like automatically handling schema changes, tracking data lineage, and enabling retention policies based on metadata rather than scanning data. Future enhancements may include using KSQL to enrich streaming data and provisioning data to external locations by launching workflows.