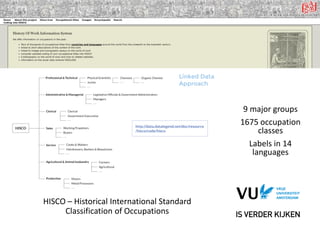
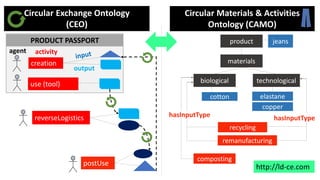
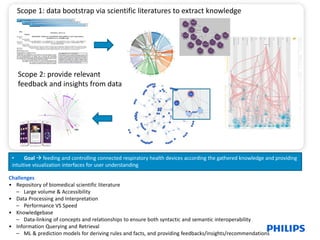
The document describes the DALICC Vocabulary, which was developed as part of the DALICC project to represent legal expressions from licenses in a machine-readable way. The vocabulary extends the ODRL and CCRel ontologies with additional properties needed to capture the full semantic spectrum of copyright statements. Examples are provided showing how the BSD 3.0, CC-BY, and Apache licenses can be represented using the DALICC vocabulary. The goal is to significantly reduce the costs of license clearance for derivative works by developing a framework that can understand and process license information.






![Semantic mining of respiratory health knowledge from
scientific literature and clinical guidelines
Sergio Consoli, Xiao Ming Zhou, Wei-Shun Bao, Declan P. Kelly, Vincent Lou
Philips Research: [name.surname]@philips.com
• Application of NLP, data mining, and advanced text analytics into advanced AI systems for semantically mining
information from scientific literature and clinical guidelines to extract new knowledge on the respiratory health domain
• Curated repository of selected medical documents into knowledge-base in respiratory health](https://image.slidesharecdn.com/zv2aqgdwqnksa6j7em9w-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155759/85/Session-0-0-poster-minutes-madness-11-320.jpg)














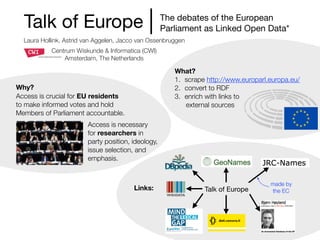
![Introduction
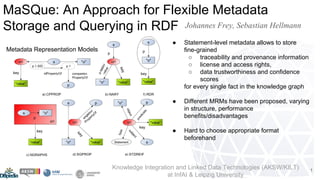
DALICC stands for Data Licenses Clearance Center. The
project‘s aim is to develop a software framework that
significantly reduces the costs of license clearance in the
creation of derivative (data) works.
DALICC follows a deontic approach to express machine-
readable permissions, prohibitions and duties defined in a
license. DALICC utilizes the ODRL 2.0 ontology in
combination with CCRel. Additionally DALICC utilizes an
extended set of properties that are necessary to capture the
full semantic spectrum of legal expressions defined in a
license text.
By doing so DALICC allows to represent property rights
policies in a legally valid and machine-processable way.
Partners:
• UAS St. Pölten (Lead) – Tassilo Pellegrini, Andrea Schönhofer, Peter Judmaier, Stefanie Größbacher
• Vienna University of Economics & Business – Simon Steyskal, Sabrina Kirrane, Axel Polleres
• University of Innsbruck – Oleksandra Panasiuk, Anna Fensel
• Höhne, In der Maur & Partner Rechtsanwälte OG – Markus Dörfler
• Semantic Web Company GmbH – Thomas Thurner, Victor Mireles-Chavez, Kurt Moser
Contact: www.dalicc.net
Acknowledgment: DALICC is funded by the Austrian Federal Ministry of Transport, Innovation and Technology
(BMVIT) under the program "ICT of the Future" between November 2016 - October 2018. More information
https://iktderzukunft.at/en/
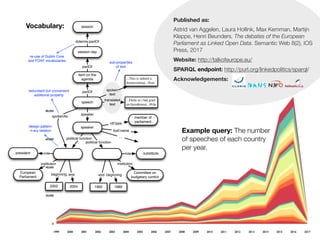
DALICC Vocabulary – REL Extension
The DALICC vocabulary extensions evolved from an in depth
analysis of 15 standard licenses (including CC, APACHE, BSD,
GPL MIT) under the supervision of legal experts. The following
expressions need to be added to cover the full semantic
spectrum of copyright statements:
PROPERTIES AFFECTING THE ASSET PROPERTIES AFFECTING THE LICENCE
dalicc:charge dalicc:addStatement
dalicc:sublicense dalicc:attributionNotice
dalicc:promote dalicc:attachOffer
dalicc:publish dalicc:chargeOffer
dalicc:irrevocable
dalicc:modificationNotice
dalicc:noWarrantyNotice
dalicc:patentFree
dalicc:patentNotice
dalicc:perpetual
dalicc:royaltyFree
dalicc:worldwide
The examples illustrate the RDF/Turle syntax of BSD 3.0, CC-BY
and APACHE using the DALICC properties (bold).
Example 3: APACHE
@prefix odrl:<http://www.w3.org/ns/odrl/2/> .
@prefix : <https://dalicc.net/license-finder> .
@prefix dalicc: <https://dalicc.poolparty.biz/DALICCVocabulary>.
@prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix cc:<http://creativecommons.org/ns#> .
@prefix dct: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
:APACHE_2.0 a odrl:Policy;
odrl:permission [
a odrl:Permission;
odrl:target
<http://purl.org/dc/dcmitype/Software>,
<http://purl.org/dc/dcmitype/Sound>,<http://purl.
org/dc/dcmitype/Text>,<http://purl.org/dc/dcmity
pe/Image>,<http://purl.org/dc/dcmitype/MovingI
mage>,<http://purl.org/dc/dcmitype/Dataset>;
odrl:action odrl:present, odrl:display, odrl:derive;
odrl:duty [
a odrl:Duty;
odrl:action cc:Notice;
]
];
odrl:permission [
a odrl:Permission;
odrl:target
<http://purl.org/dc/dcmitype/Software>,<http://p
url.org/dc/dcmitype/Sound>,<http://purl.org
/dc/dcmitype/Text>,<http://purl.org/dc/dcmitype
/Image>,<http://purl.org/dc/dcmitype/Movin
gImage>,<http://purl.org/dc/dcmitype/Dataset>;
odrl:action odrl:reproduce, odrl:distribute,
dalicc:sublicense, dalicc:addStatement,
dalicc:chargeOffer, dalicc:patentFree;
odrl:duty [
a odrl:Duty;
odrl:action dalicc:modificationNotice, cc:Notice,
dalicc:patentNotice, dalicc:atributionNotice,
dalicc:noWarrantyNotice, cc:ShareAlike,
dalicc:perpetual, dalicc:royaltyFree,
dalicc:irrevocable, dalicc:worldwide
]
];
odrl:prohibition [
a odrl:Prohibition;
odrl:target
<http://purl.org/dc/dcmitype/Software>,<http://p
url.org/dc/dcmitype/Sound>,<http://purl.org/dc/d
cmitype/Text>,<http://purl.org/dc/dcmitype/Image
>,<http://purl.org/dc/dcmitype/MovingImage>,
<http://purl.org/dc/dcmitype/Dataset>;
odrl:action odrl:ensureExclusivity, dalicc:charge;
].
Example 1: BSD 3.0
@prefix odrl:<http://www.w3.org/ns/odrl/2/> .
@prefix : <https://dalicc.net/license-finder> .
@prefix dalicc: <https://dalicc.poolparty.biz/DALICCVocabulary>.
@prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix cc:<http://creativecommons.org/ns#> .
@prefix dct: <http://purl.org/dc/terms/> .
:licBSD-3-Clause a odrl:Policy;
odrl:permission [
a odrl:Permission;
odrl:target <http://purl.org/dc/dcmitype/Software>;
odrl:action odrl:mofify, odrl:distribute, odrl:reproduce;
odrl:duty [
a odrl:Duty;
odrl:action cc:Notice, dalicc:nowarrantyNotice;
]
];
odrl:prohibition [
a odrl:Prohibition;
odrl:target <http://purl.org/dc/dcmitype/Software>;
odrl:action dalicc:promote
];
dct:title "The 3-Clause BSD License"@en ;
dct:alternative "BSD-3-Clause";
dct:source <https://opensource.org/licenses/BSD-3-Clause>.
Example 2: CC-BY
@prefix odrl:<http://www.w3.org/ns/odrl/2/> .
@prefix : <https://dalicc.net/license-finder> .
@prefix dalicc: <https://dalicc.poolparty.biz/DALICCVocabulary>.
@prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix cc:<http://creativecommons.org/ns#> .
@prefix dct: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
:CC-BY_4.0 a odrl:Policy;
odrl:permission [
a odrl:Permission;
odrl:target
<http://purl.org/dc/dcmitype/Dataset>,<http://purl.org/d
c/dcmitype/Sound>,<http://purl.org/dc/dcmitype/Text>,<
http://purl.org/dc/dcmitype/Image>,<http://purl.org/dc/
dcmitype/MovingImage>;
odrl:action odrl:distribute, odrl:reproduce,odrl:extract,
odrl:derive, odrl:present;
odrl:duty [
a odrl:Duty;
odrl:action cc:SourceCode, dalicc:royaltyFree,
dalicc:irrevocable, dalicc:worldwide, cc:Notice,
dalicc:noWarrantyNotice, dalicc:modificationNotice,
cc:attributionName
]
];
odrl:prohibition [
a odrl:Prohibition;
odrl:target
<http://purl.org/dc/dcmitype/Dataset>,<http://purl.org/dc
/dcmitype/Sound>,<http://purl.org/dc/dcmitype/Text>,
<hattp://purl.org/dc/dcmitype/Image>,<http://purl.org/dc
/dcmitype/MovingImage>;
odrl:action odrl:ensureExclusivity, dalicc:sublicense
];
dct:title "Attribution 4.0 International"@en ;
dct:alternative "CC BY 4.0";
dct:publisher "Creative Commons";
foaf:logo <http://i.creativecommons.org/l/by/4.0/88x31.png> ;
dct:source <http://creativecommons.org/licenses/by/4.0/> ;
cc:legalcode
"""https://creativecommons.org/licenses/by/4.0/legalcode"""@en.
Future Work
The DALICC Framework will consist of four components:
• License Composer: Lets you create customized licenses
• License Library: Lets you choose from a set of standard licenses
• License Annotator: Provides you with a machine-readable and human-readable version of
your license
• License Negotiator: Checks compatibility, detects conflicts and supports conflict resolution
Data Set
N License N
License
{A … N} Derivative Work
Data Set
… License …
Data Set
B License B
Data Set
A License A
License
Composer
License
Annotator
License
Library
DALICC Framework
License
Negotiator
consults
tags audits proposes
• Compatibility
• Conflict Detection
• Conflict Resolution](https://image.slidesharecdn.com/zv2aqgdwqnksa6j7em9w-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155759/85/Session-0-0-poster-minutes-madness-34-320.jpg)