Downloaded 12 times





















![BigML, Inc 28Topic Models
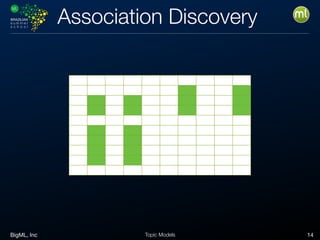
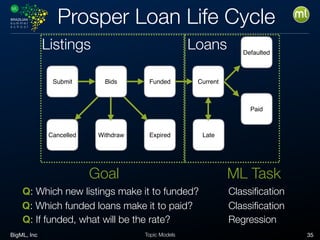
Aggregating
User Num.Playbacks Total Time Pref.Device
User001 3 830 Tablet
User002 1 218 Smartphone
User003 3 1019 TV
User005 2 521 Tablet
Aggregated data (list of users)
When the entity to model is different from the provided data, an
aggregation to get the entity might be needed.
Content Genr
e
Duration Play Time User Device
Highway
star
Rock 190 2015-05-12
16:29:33
User001 TV
Blues alive Blues 281 2015-05-13
12:31:21
User005 Tablet
Lonely
planet
Tech
no
332 2015-05-13
14:26:04
User003 TV
Dance,
dance
Disco 312 2015-05-13
18:12:45
User001 Tablet
The wall Reag
ge
218 2015-05-14
09:02:55
User002 Smartphone
Offside
down
Tech
no
240 2015-05-14
11:26:32
User005 Tablet
The
alchemist
Blues 418 2015-05-14
21:44:15
User003 TV
Bring me
down
Class
ic
328 2015-05-15
06:59:56
User001 Tablet
The
scarecrow
Rock 269 2015-05-15
12:37:05
User003 Smartphone
Original data (list of playbacks)
create table violations_aggregated select business_id,count(*) as violation_num,group_concat(description) as violation_txt from
violations group by business_id;
create table scores_last_label_violations select * from scores_last_label left join violations_aggregated USING (business_id);
tail -n+2 playlists.csv | cut -d',' -f5 | sort | uniq -c
tail -n+2 playlist.csv | awk -F',' '{arr[$5]+=$3} END {for (i in arr) {print arr[i],i}}'
SET @@group_concat_max_len = 15000
select 'name', 'address', 'city', 'state', 'postal_code', 'latitude', 'longitude', 'violation_num', 'violation_txt', 'score_label'
UNION select name, address, city, state, postal_code, latitude, longitude, violation_num, violation_txt, score_label from
scores_last_label_violations into outfile "./scores_last_label_violations_headers.csv" ;](https://image.slidesharecdn.com/bssml17-basic-transformations-171201123242/85/BSSML17-Basic-Data-Transformations-28-320.jpg)









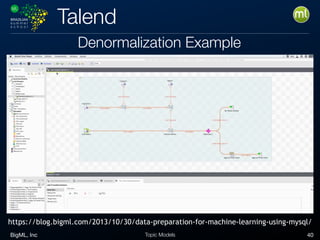



The document discusses preparing data for machine learning models. It describes how real-world data is often messy and unstructured, requiring transformations like cleaning, labeling, aggregation, and structuring to make it suitable for ML tasks. The document provides examples of common data transformations including denormalizing, adding labels, handling missing values, and structuring output in CSV format. It emphasizes that the goal of transformations is to end up with tabular data where each row is an observation and each column is a feature.























































































