Downloaded 151 times











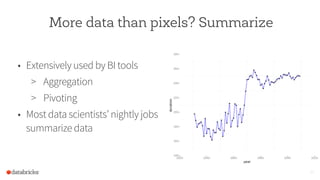
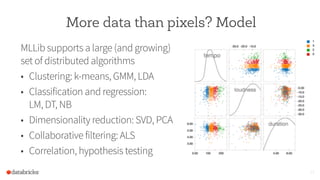
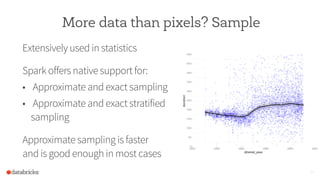




This document discusses using Spark to enable interactive visualization of big data in the browser. Spark can help address challenges of manipulating large datasets by caching data in memory to reduce latency, increasing parallelism, and summarizing, modeling, or sampling large datasets to reduce the number of data points. The goal is to put visualization back into the normal workflow of data analysis regardless of data size and enable sharing and collaboration through interactive and reproducible visualizations in the browser.








































































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)


