Download to read offline












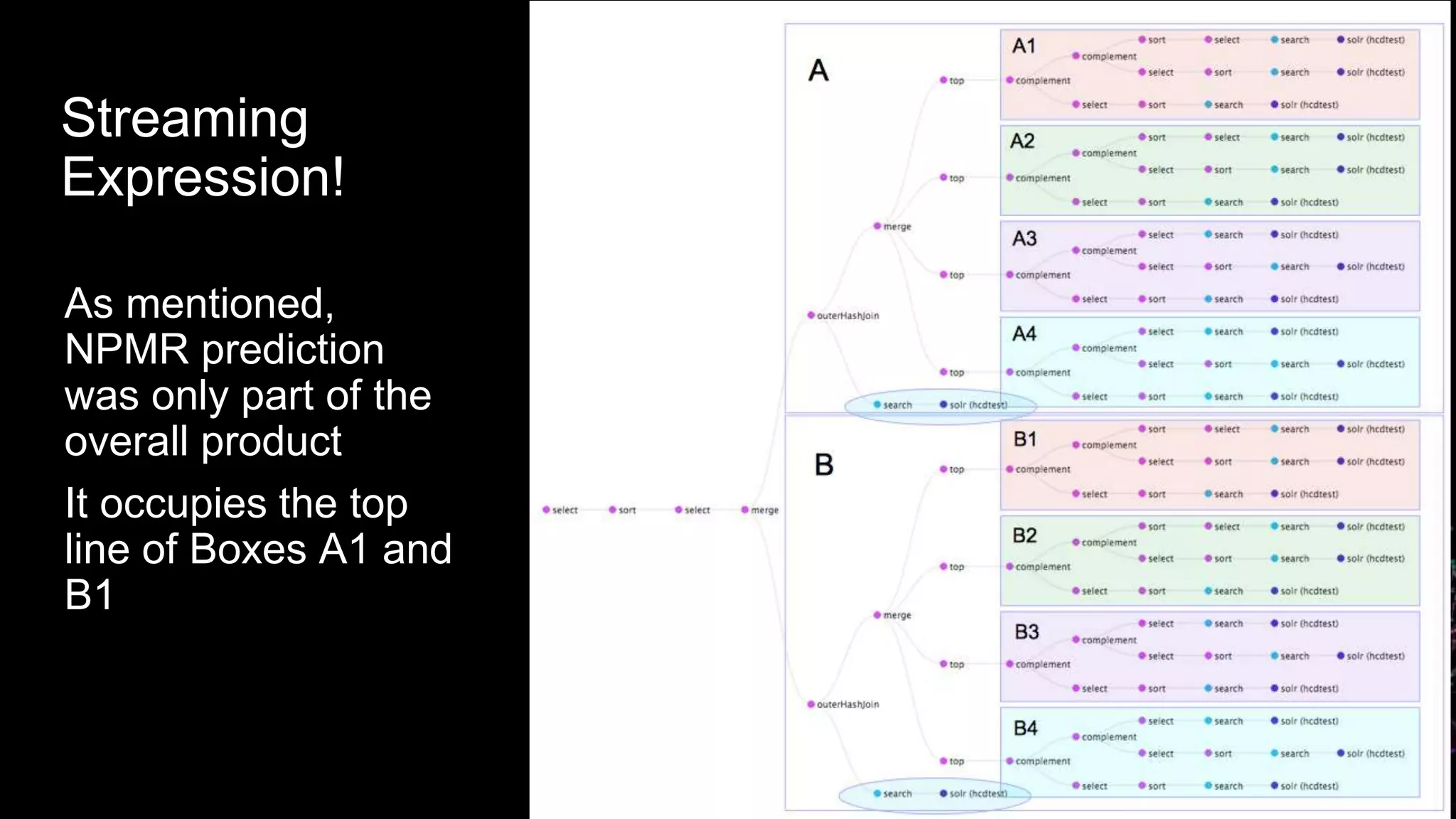


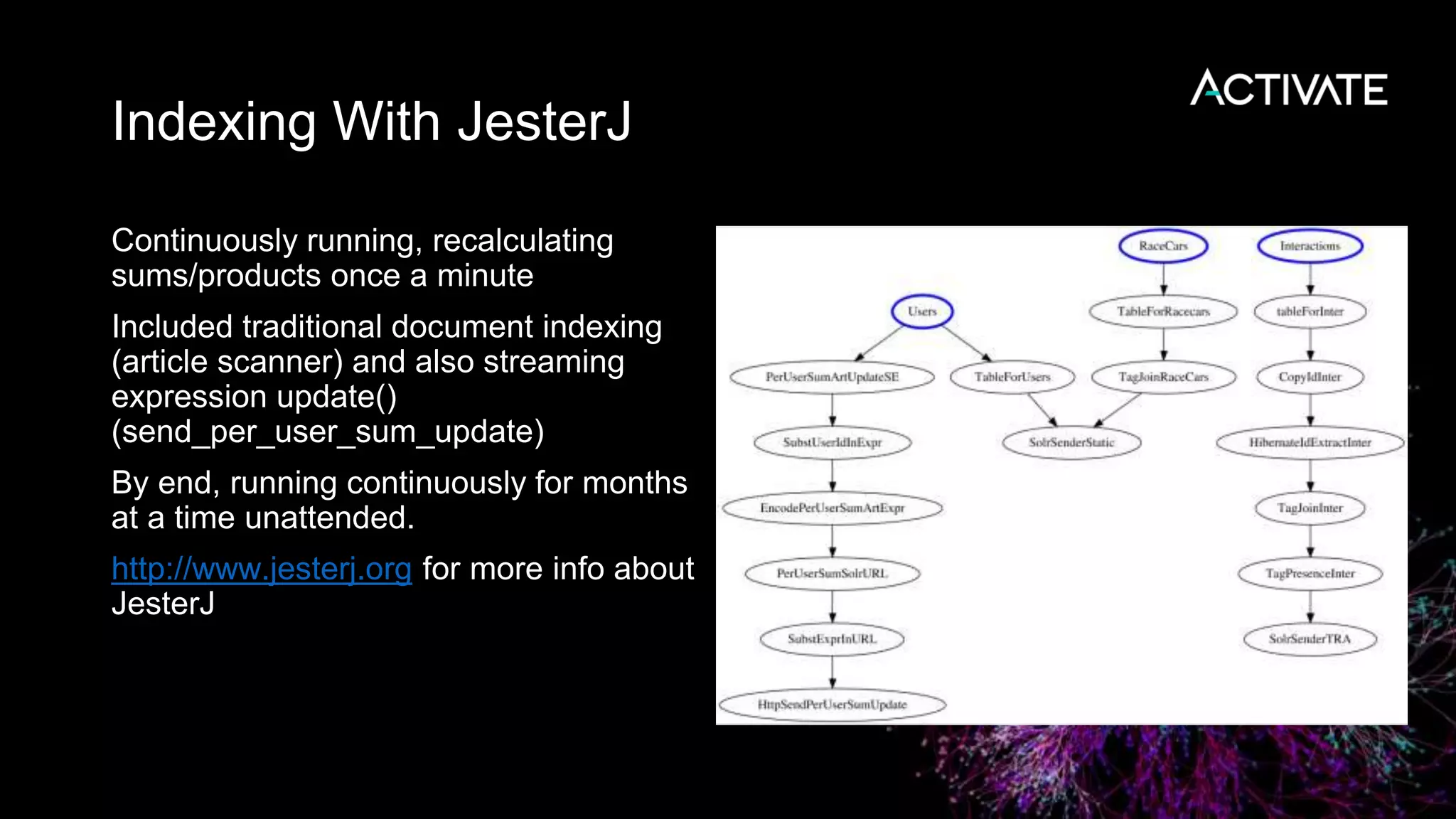













This document summarizes a presentation about query-time nonparametric regression and time routed aliases in Solr. It discusses how nonparametric multiplicative regression was used to continuously predict user interests for an online career coaching system based on click-through data. It also describes how time routed aliases in Solr provide a built-in way to implement time-partitioned indexing of timestamped data across multiple collections while automatically adding and removing collections over time.





















































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)














![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















