Download as PDF, PPTX





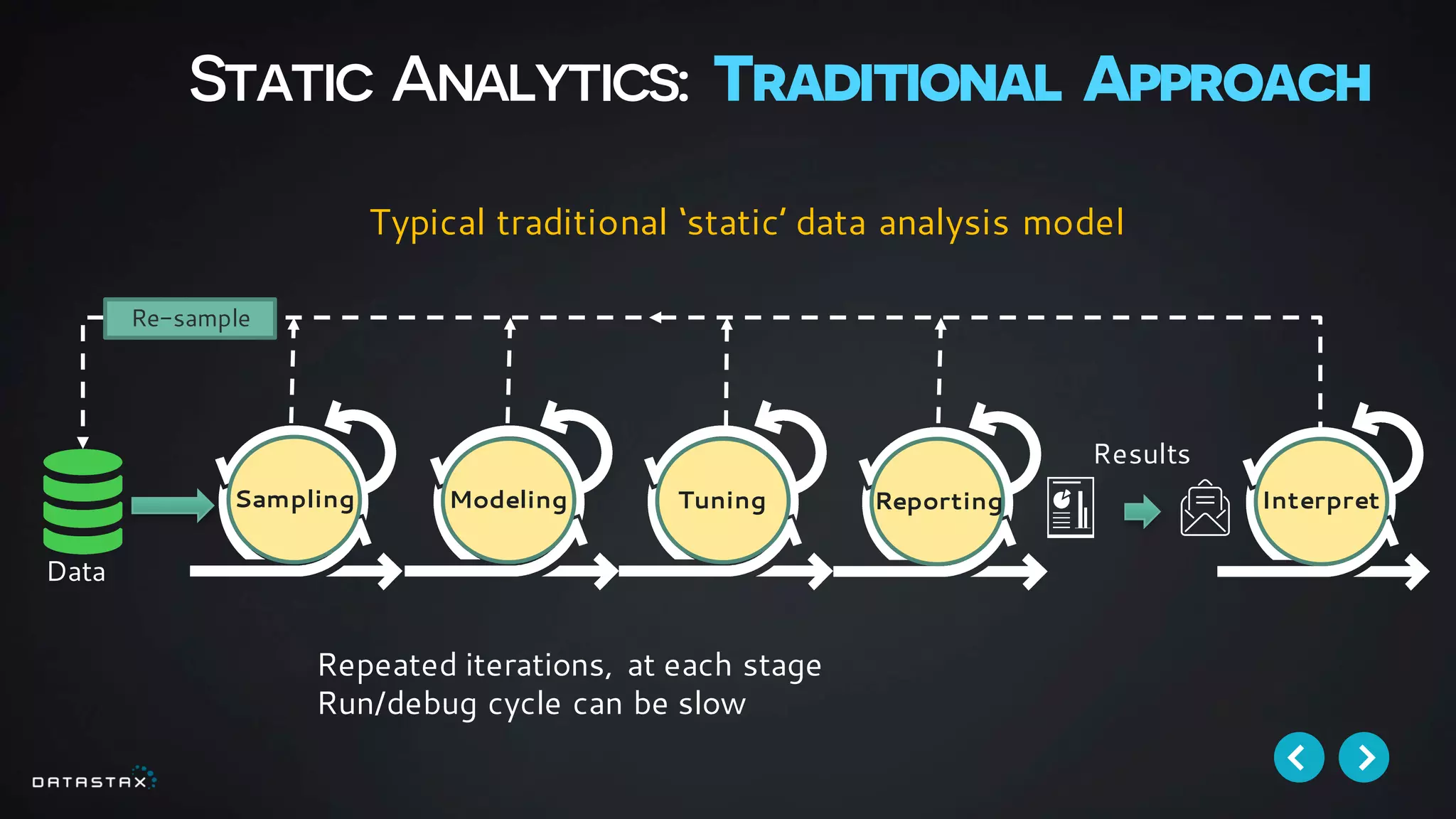










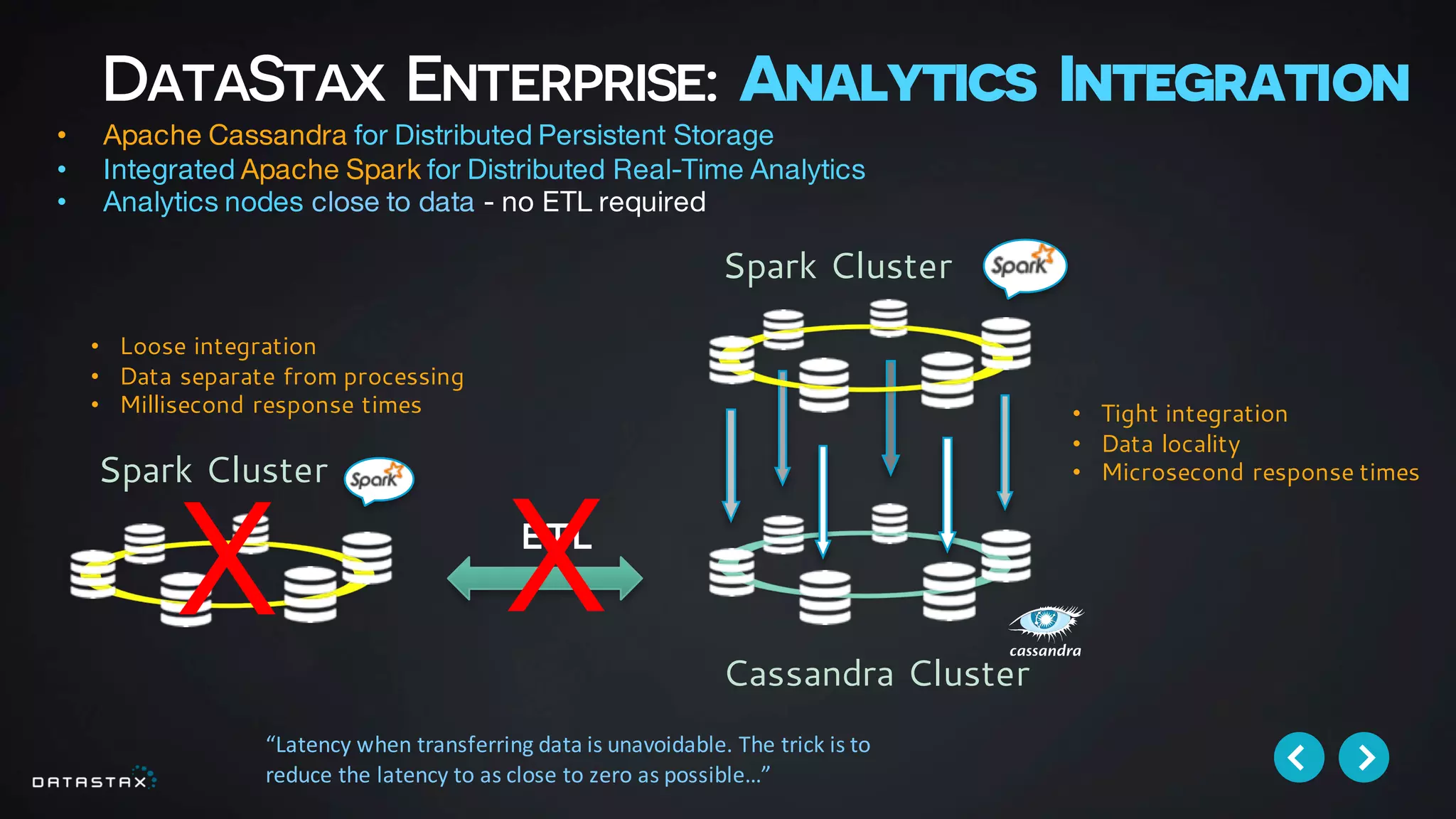




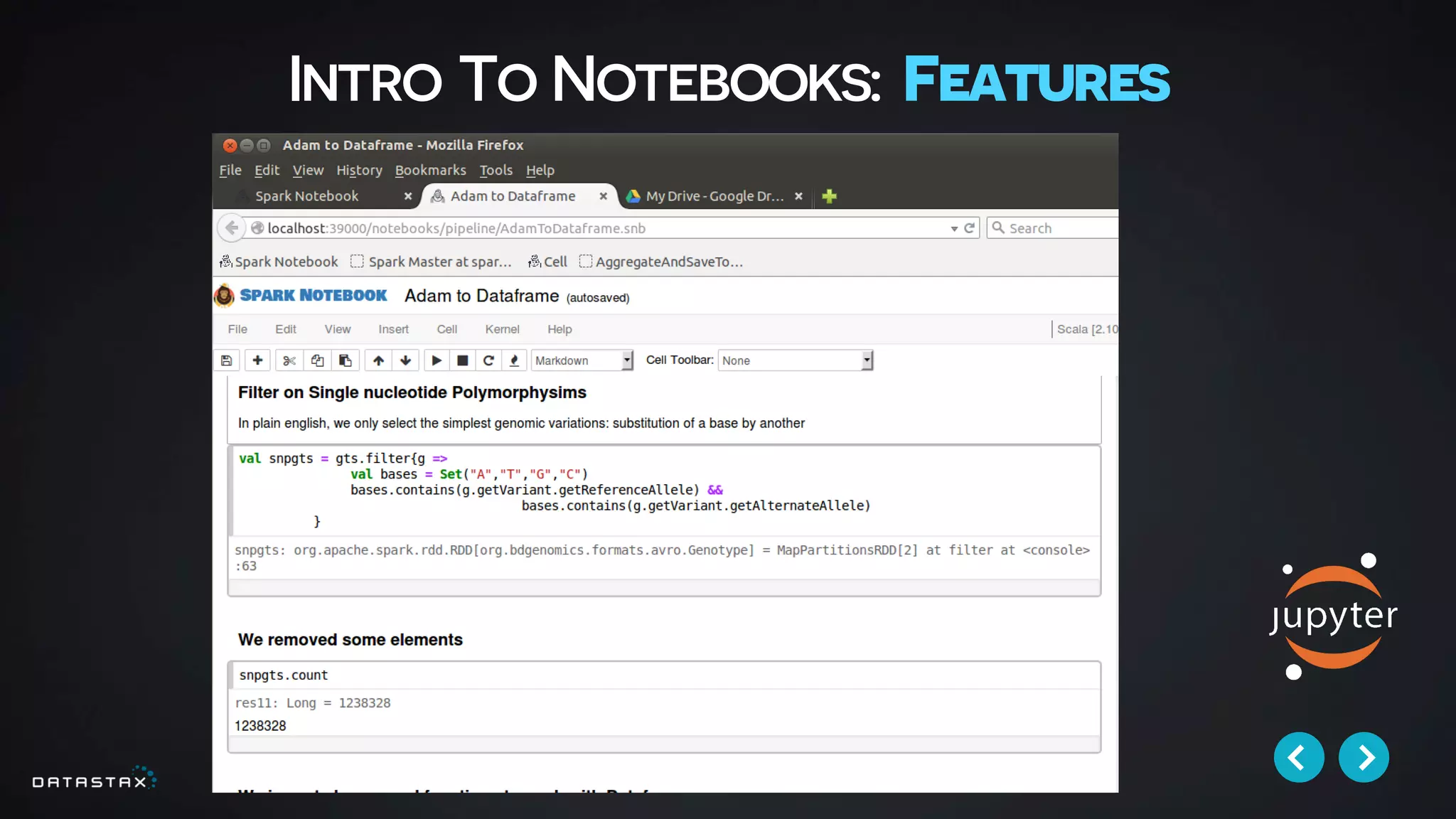

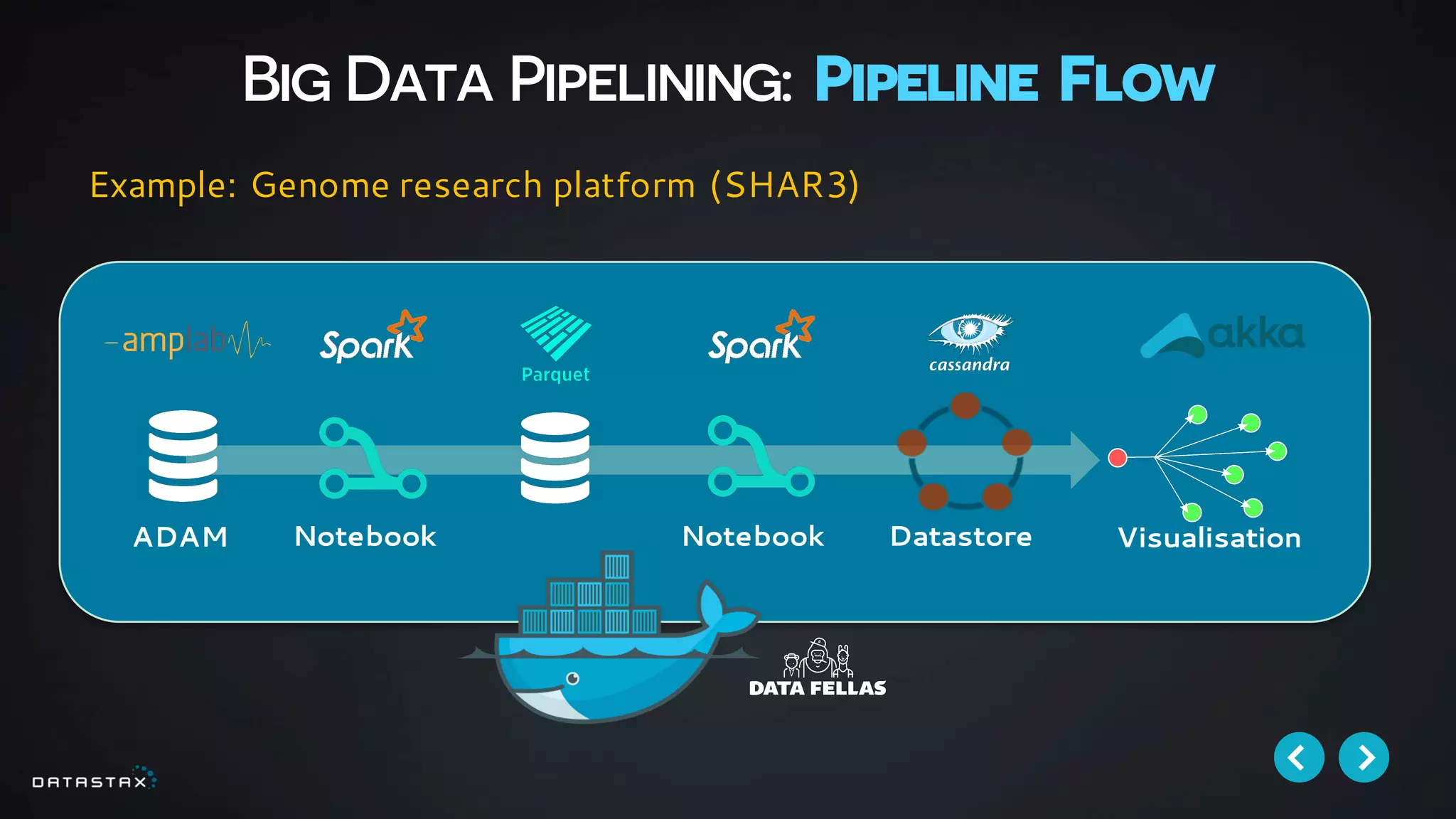

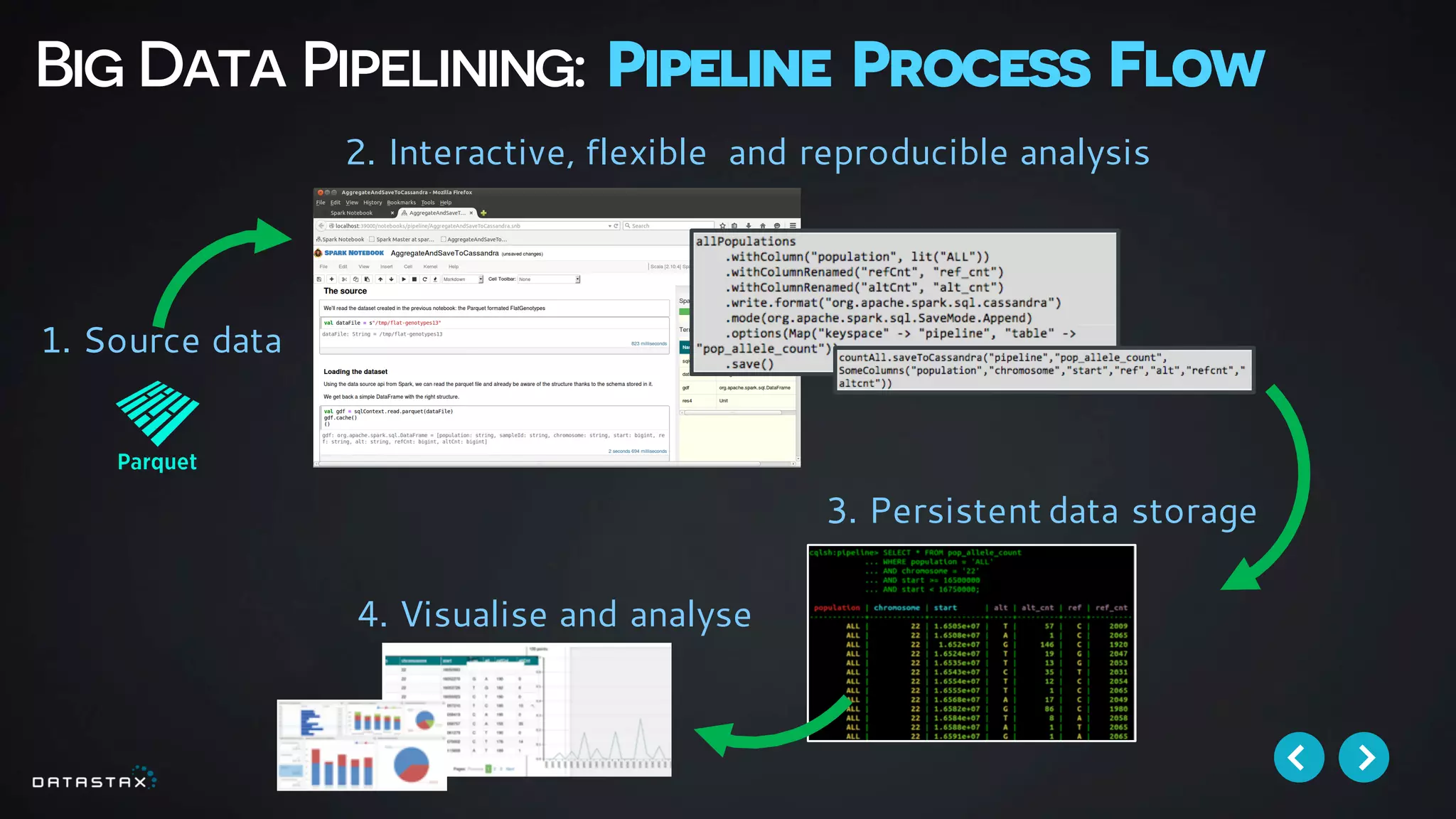
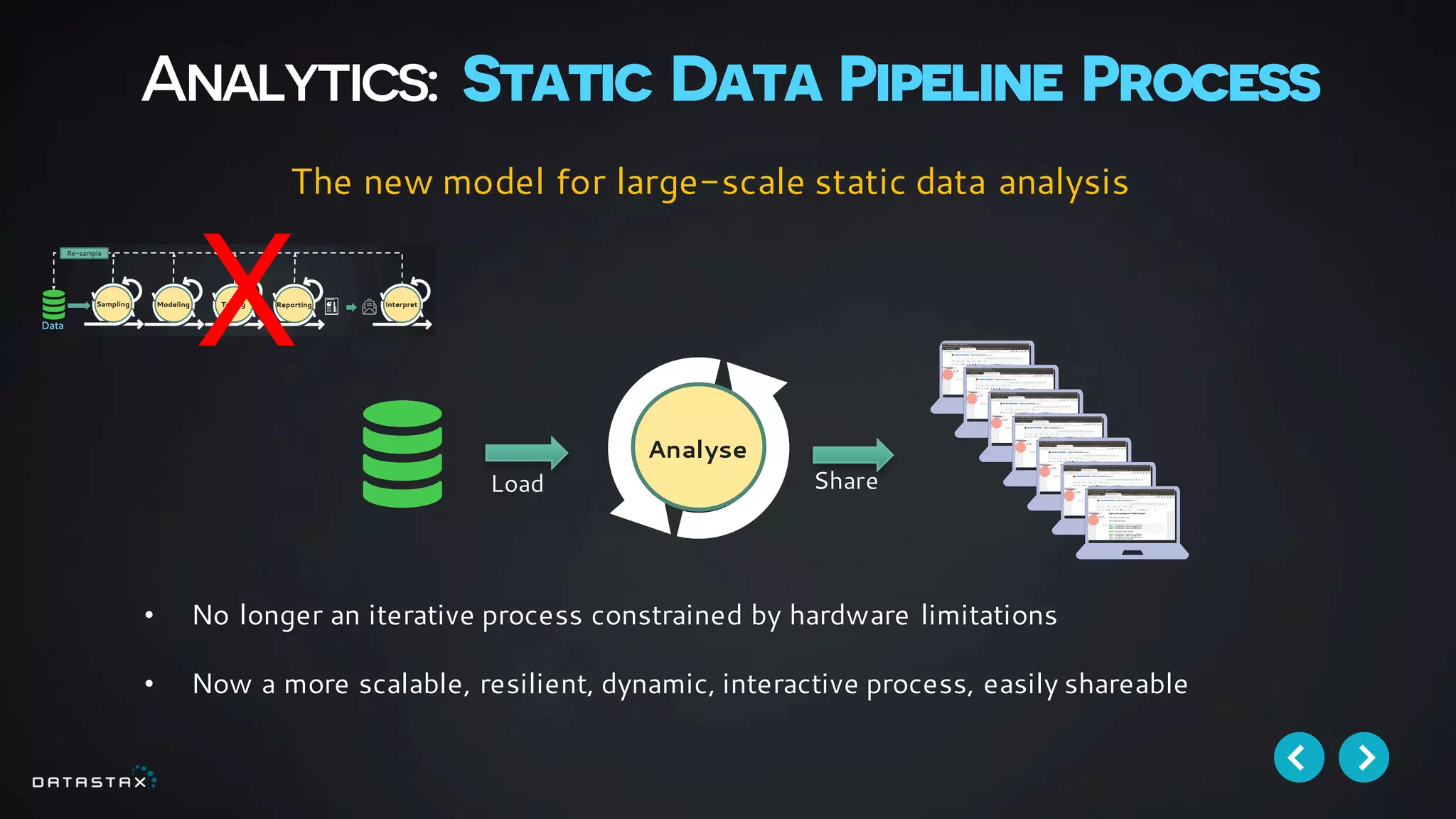







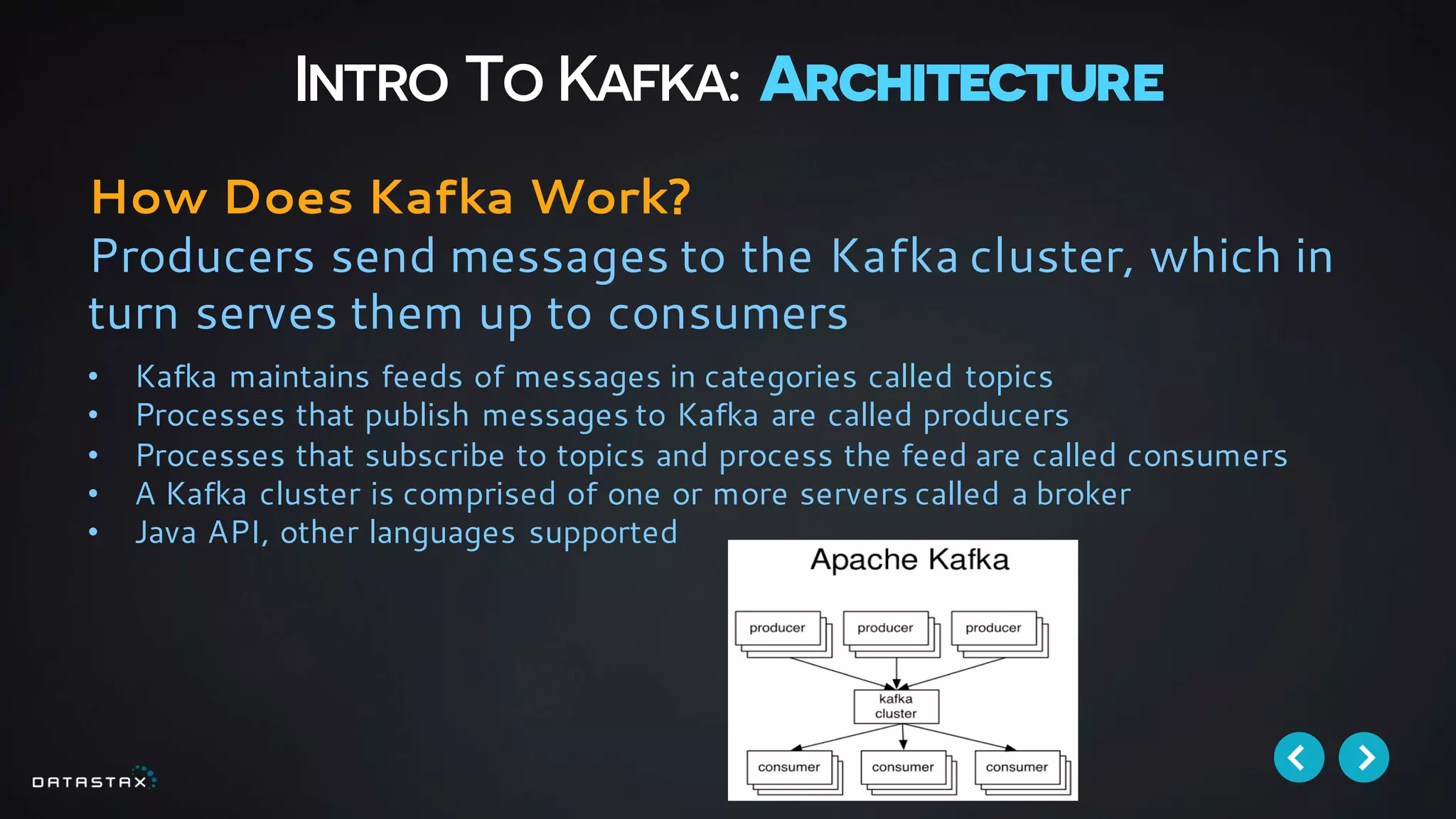

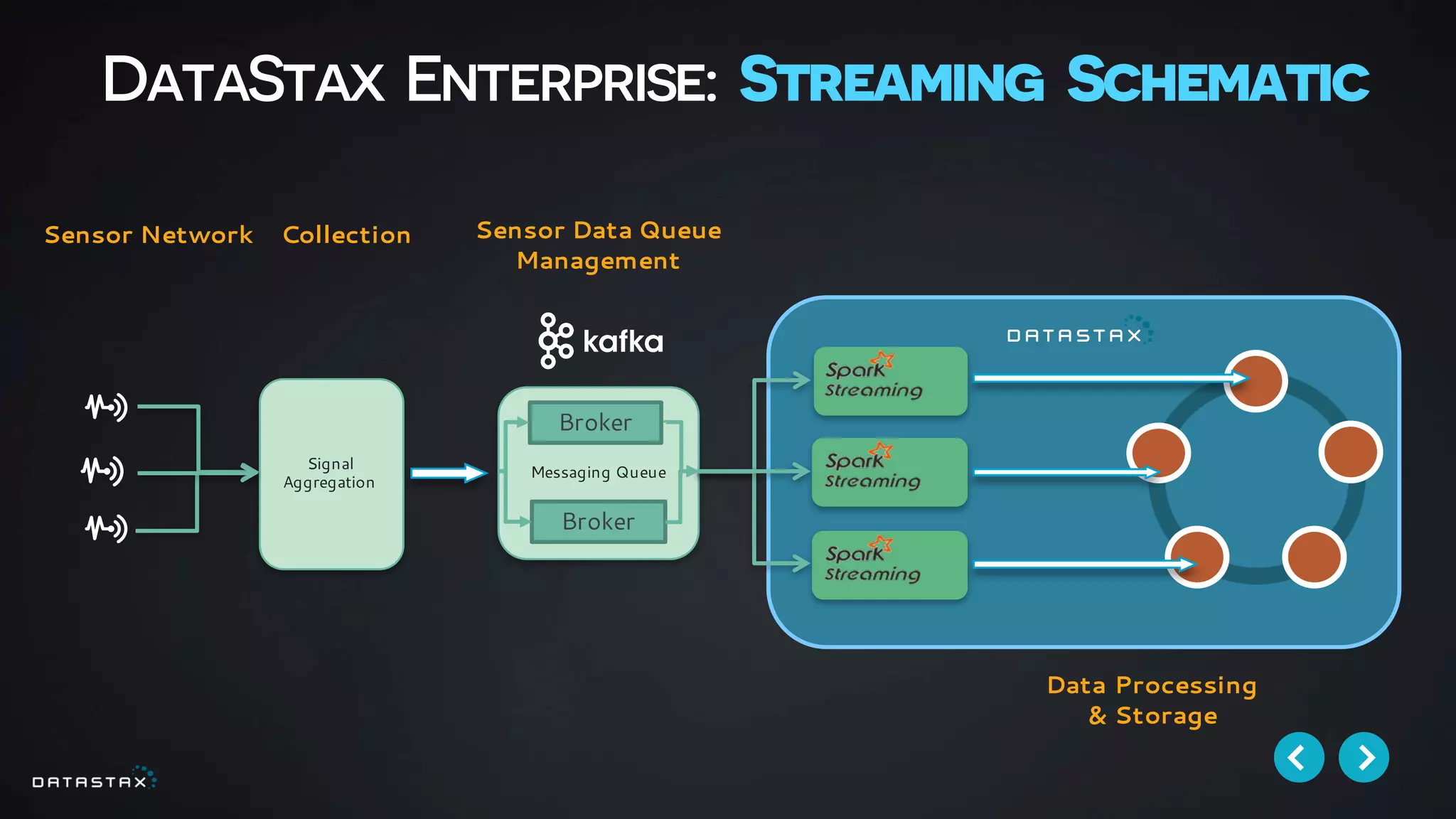
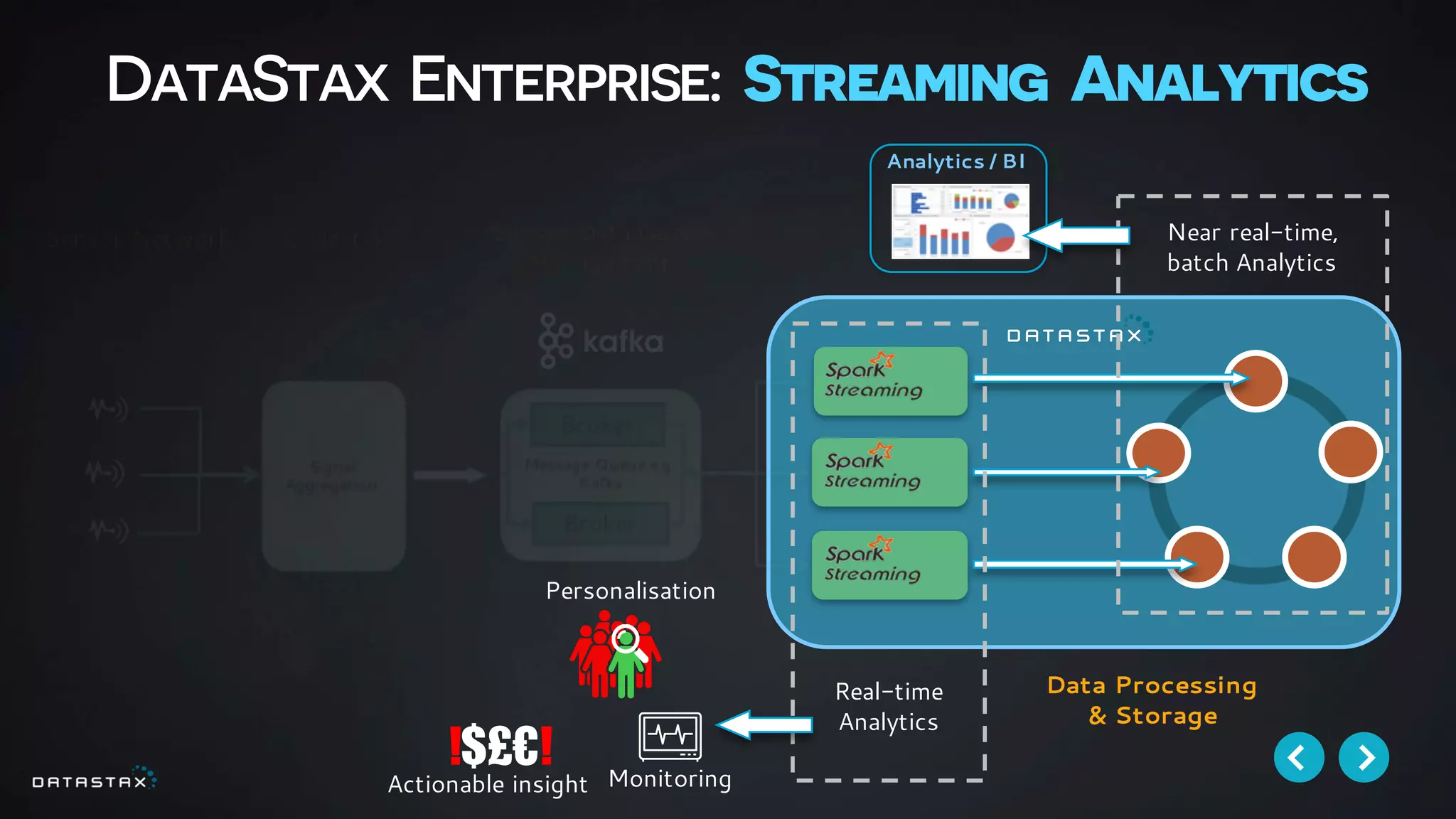
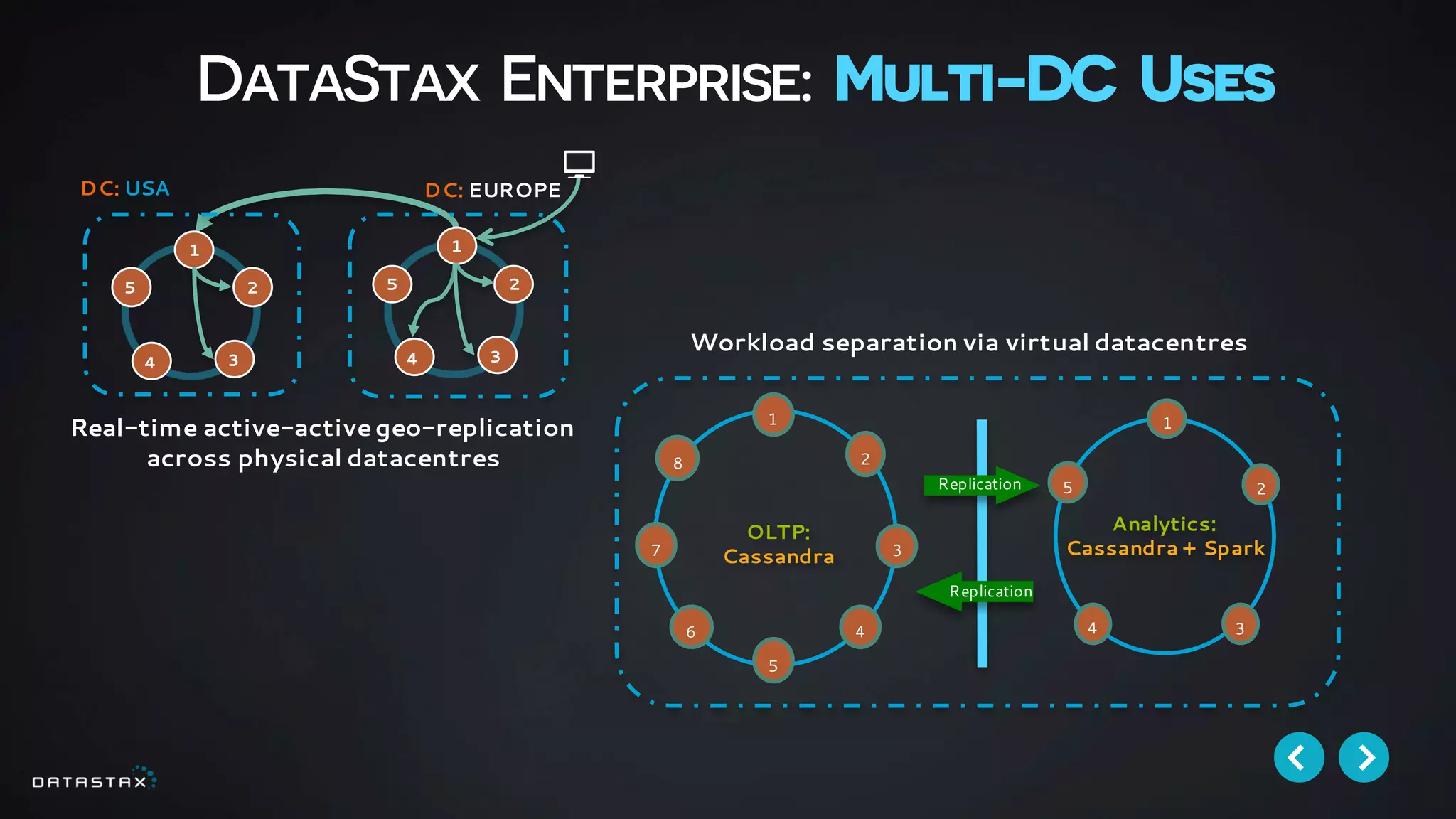
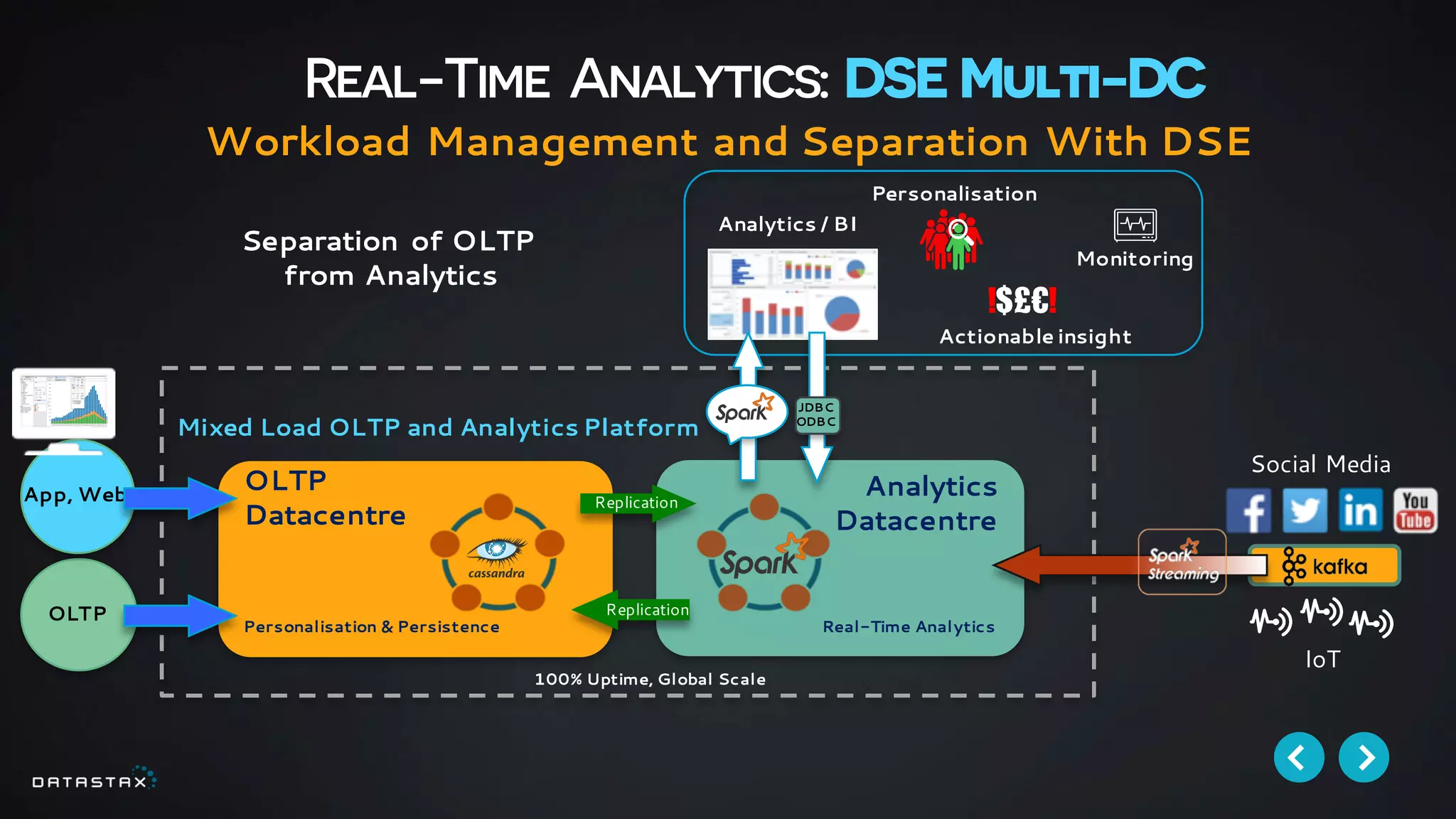
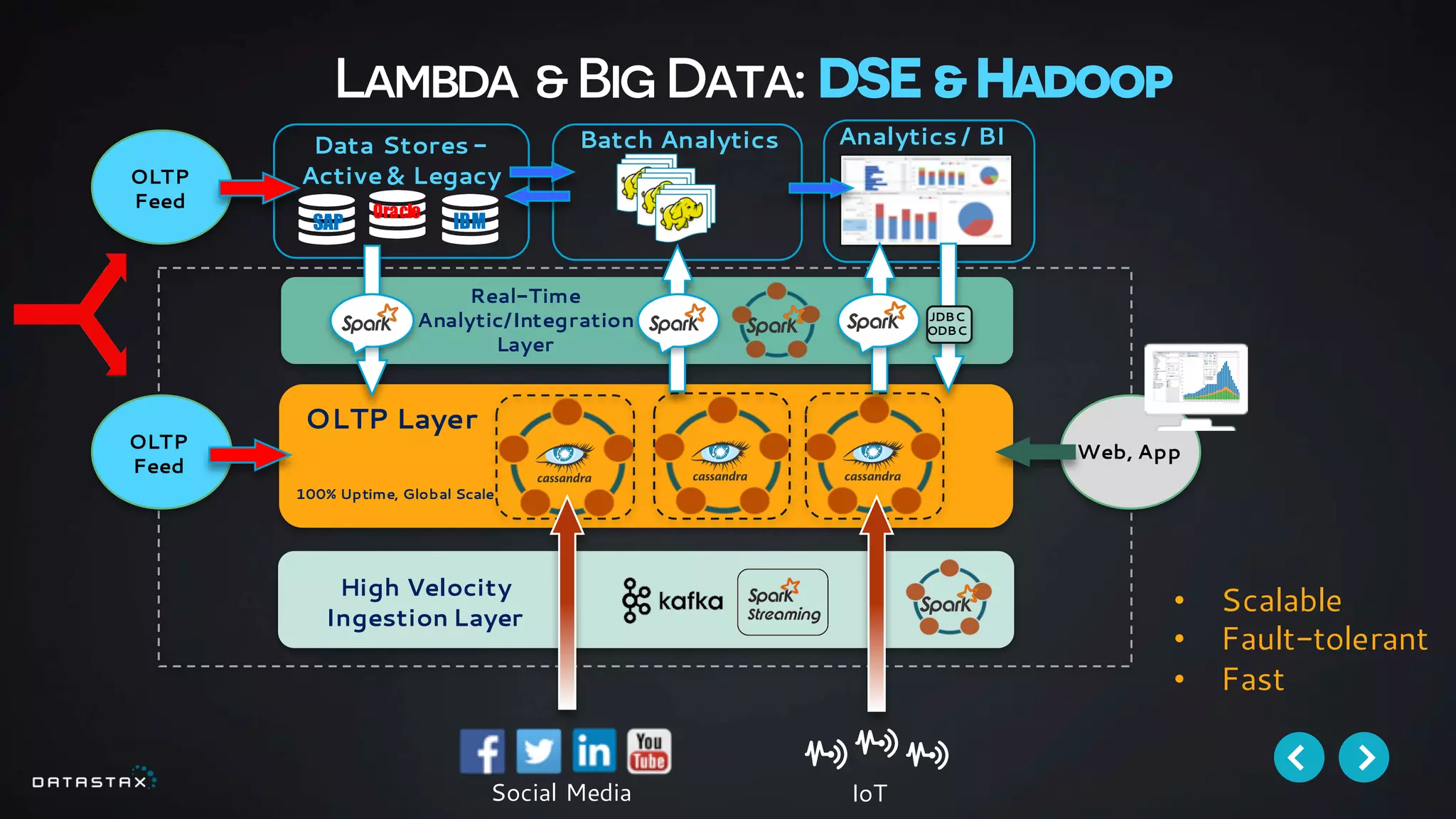
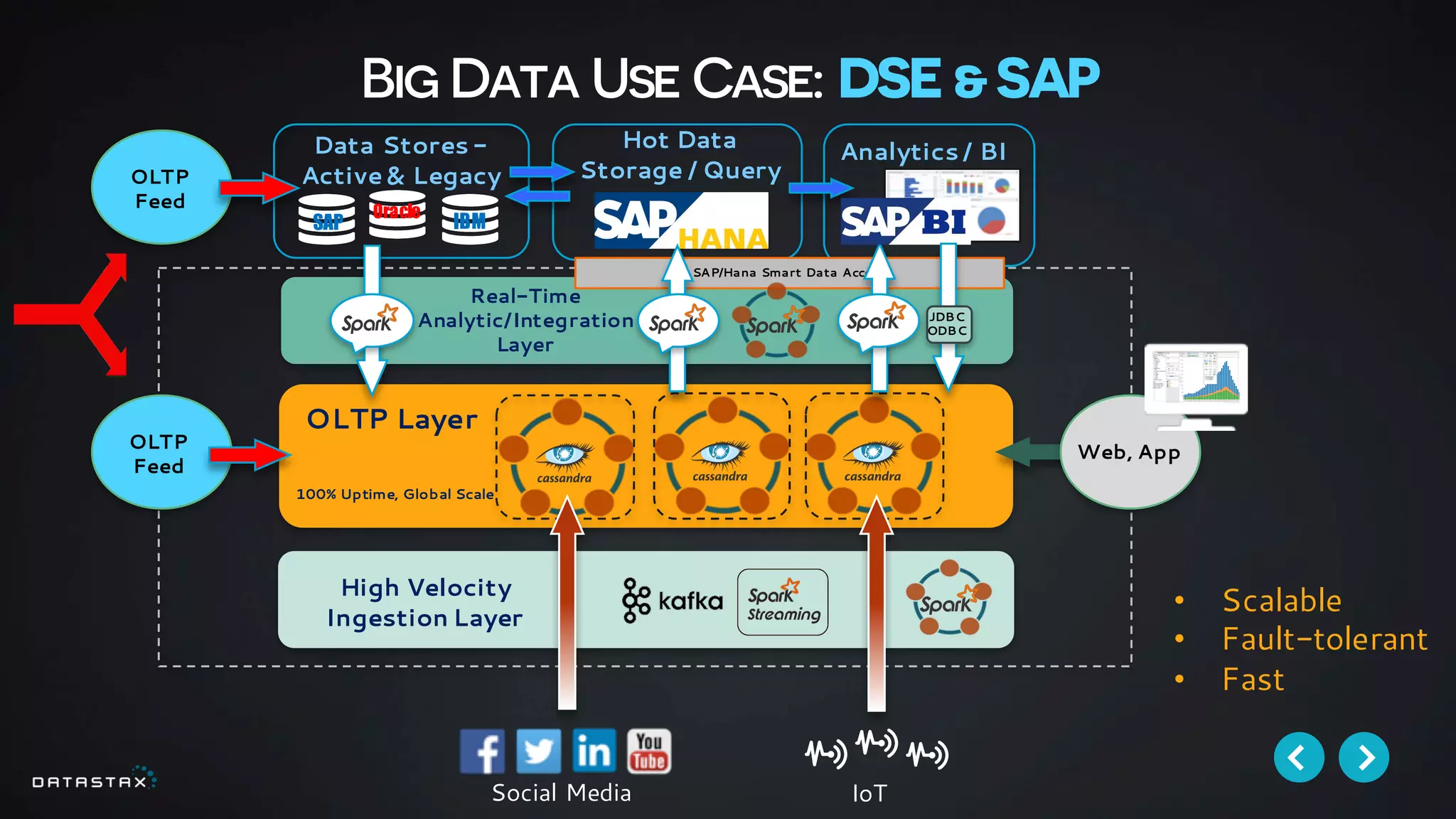



This document discusses building data pipelines with Apache Spark and DataStax Enterprise (DSE) for both static and real-time data. It describes how DSE provides a scalable, fault-tolerant platform for distributed data storage with Cassandra and real-time analytics with Spark. It also discusses using Kafka as a messaging queue for streaming data and processing it with Spark. The document provides examples of using notebooks, Parquet, and Akka for building pipelines to handle both large static datasets and fast, real-time streaming data sources.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





