Download as PDF, PPTX




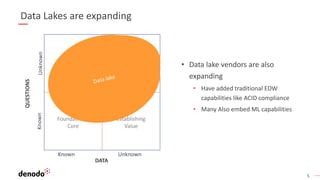












The document discusses the distinctions between data lakes and data virtualization, highlighting the evolution of data management systems and architectural paradigms over the past decade. It argues that while both data warehouses and lakes are vital to modern data strategies, merging them into a single system poses technical and operational challenges, including cost efficiency and complexity in managing diverse data types. A logical data infrastructure approach is proposed as a more effective solution than attempting to consolidate all analytical activities into one system.























































































