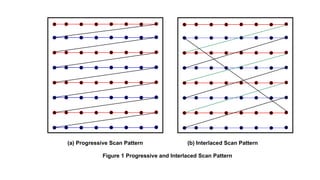
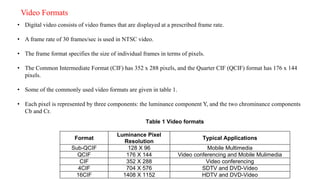
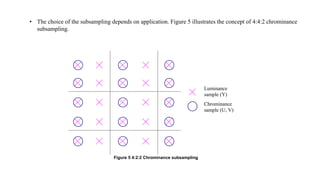
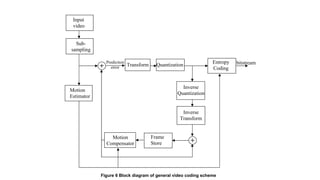
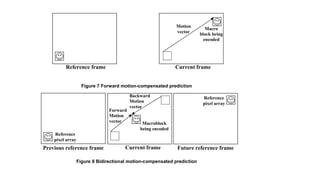
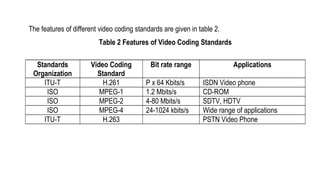
The document provides an introduction to video processing, explaining the nature of video signals, including analogue and digital formats, frame rates, and scanning patterns. It highlights video compression techniques and the significance of various frame types (I-frames, P-frames, B-frames) for efficient video encoding, along with methods such as motion estimation and subsampling. The content also discusses the applications of digital video, including teleconferencing and multimedia, while emphasizing the importance of reducing spatial and temporal redundancies for practical video transmission.