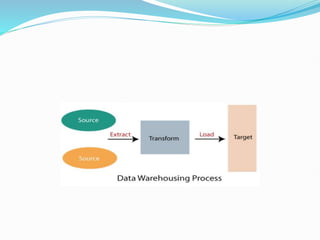
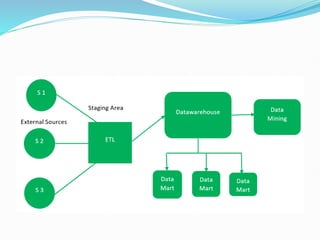
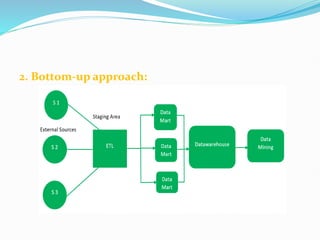
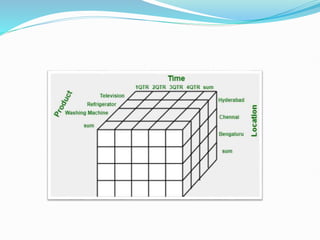
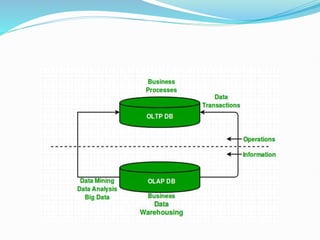
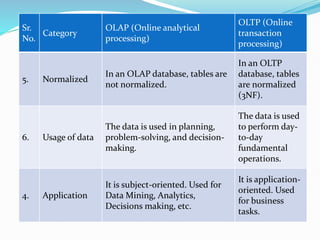
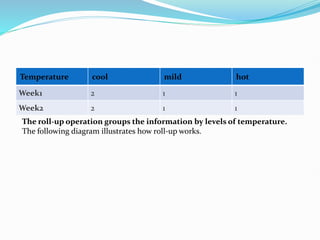
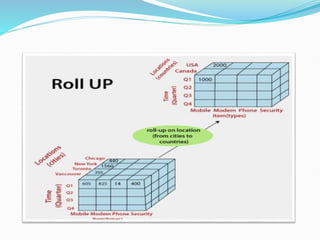
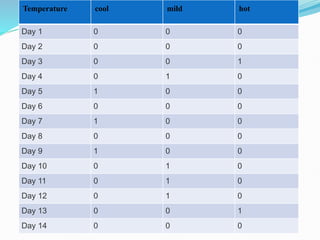
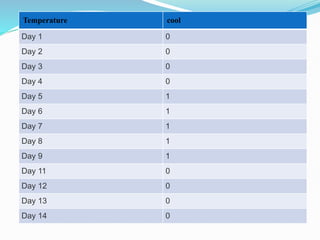
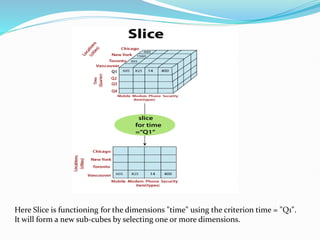
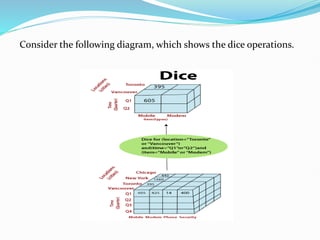
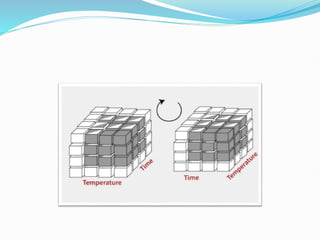
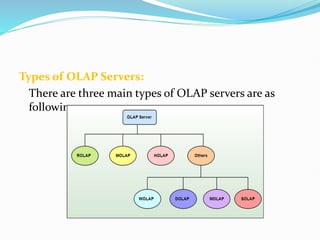
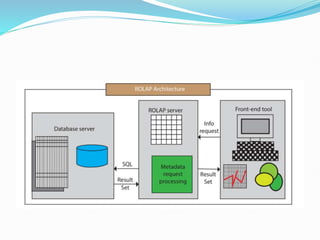
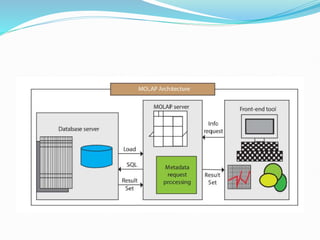
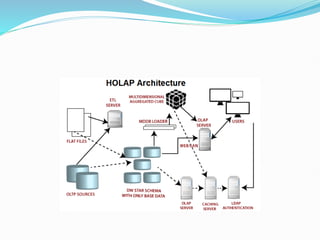
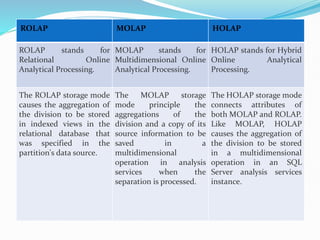
Data warehousing combines data from multiple sources to ensure data quality and accuracy. It separates analytics processing from transactional databases. A data warehouse stores historical data and allows fast querying of all data, using OLAP, while a database stores current transactions for online processing using OLTP. A multidimensional data model organizes data into cubes with dimensions and facts to allow analyzing data from different perspectives. Key components of a data warehouse architecture include external data sources, a staging area using ETL, the data warehouse, and data marts containing subsets of warehouse data.