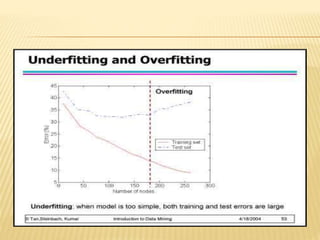
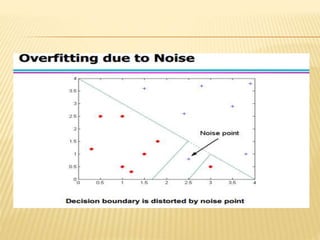
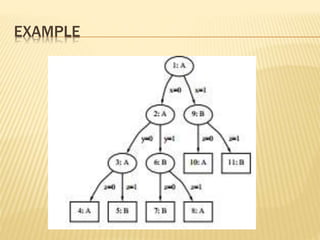
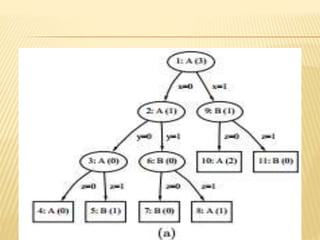
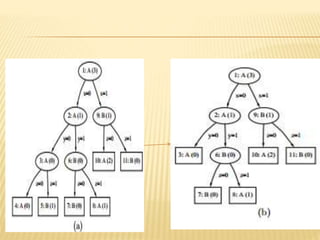
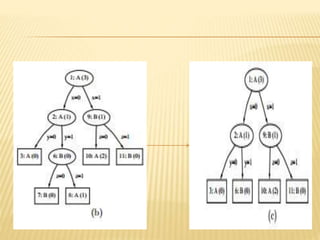
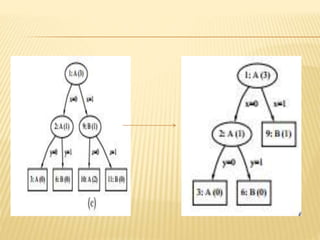
The document discusses tree pruning in decision trees, emphasizing the issues of underfitting and overfitting that can occur during classification. It outlines two primary methods for pruning: prepruning, which halts tree growth based on specific criteria, and postpruning, which involves trimming a fully grown tree to minimize misclassification error. The advantages and disadvantages of both approaches are compared, with postpruning generally favored for better handling of interaction effects between attributes.