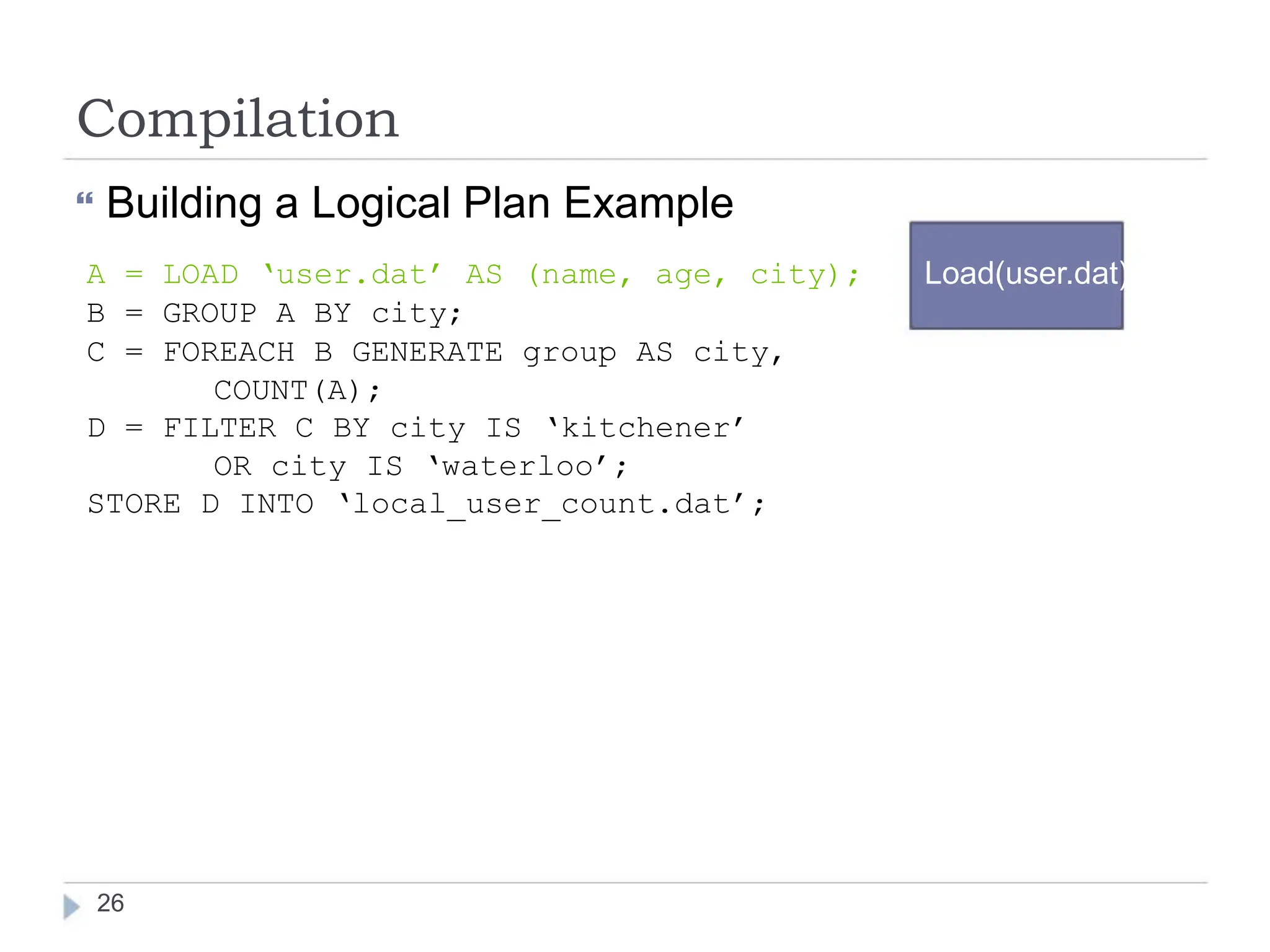
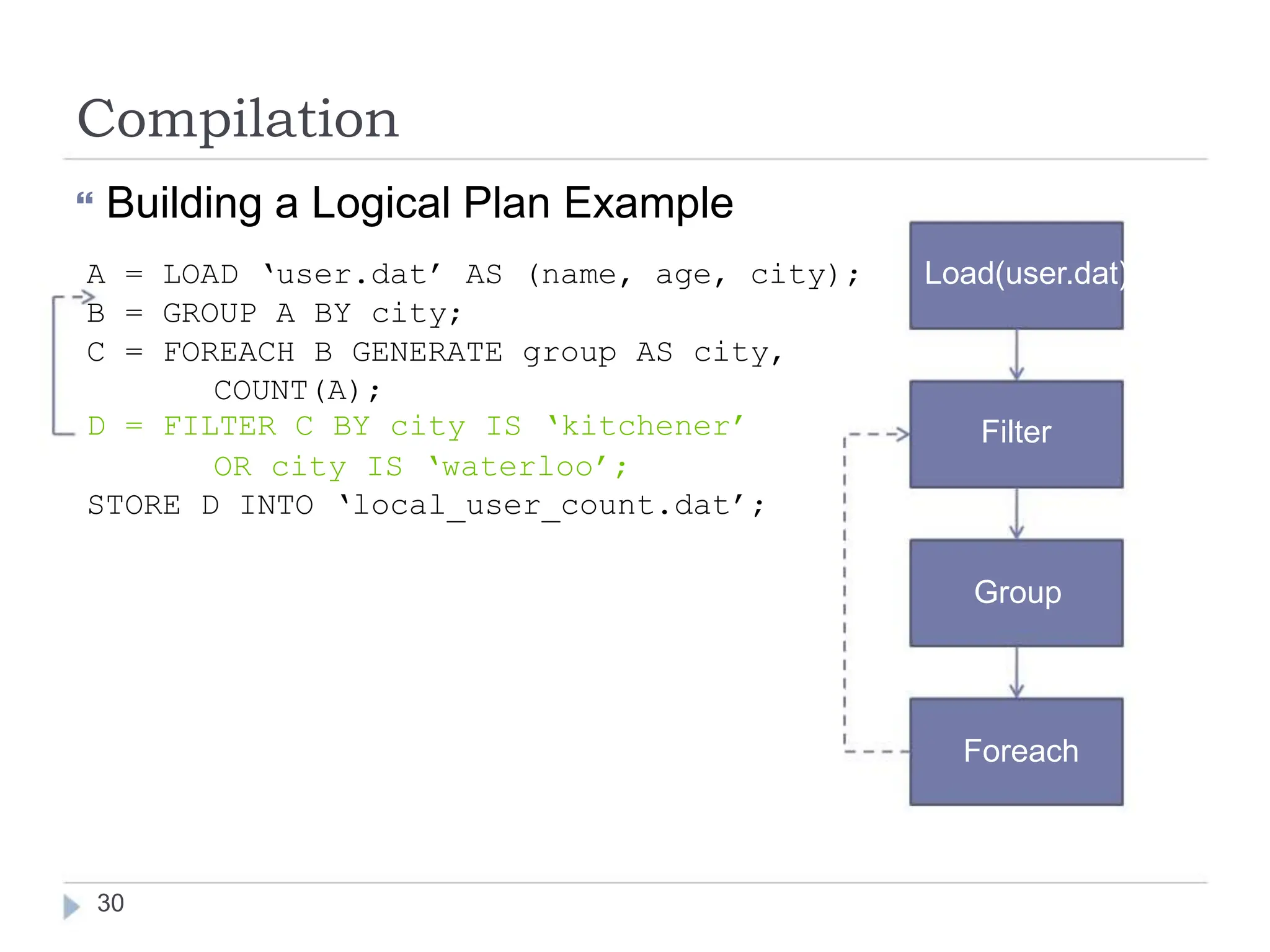
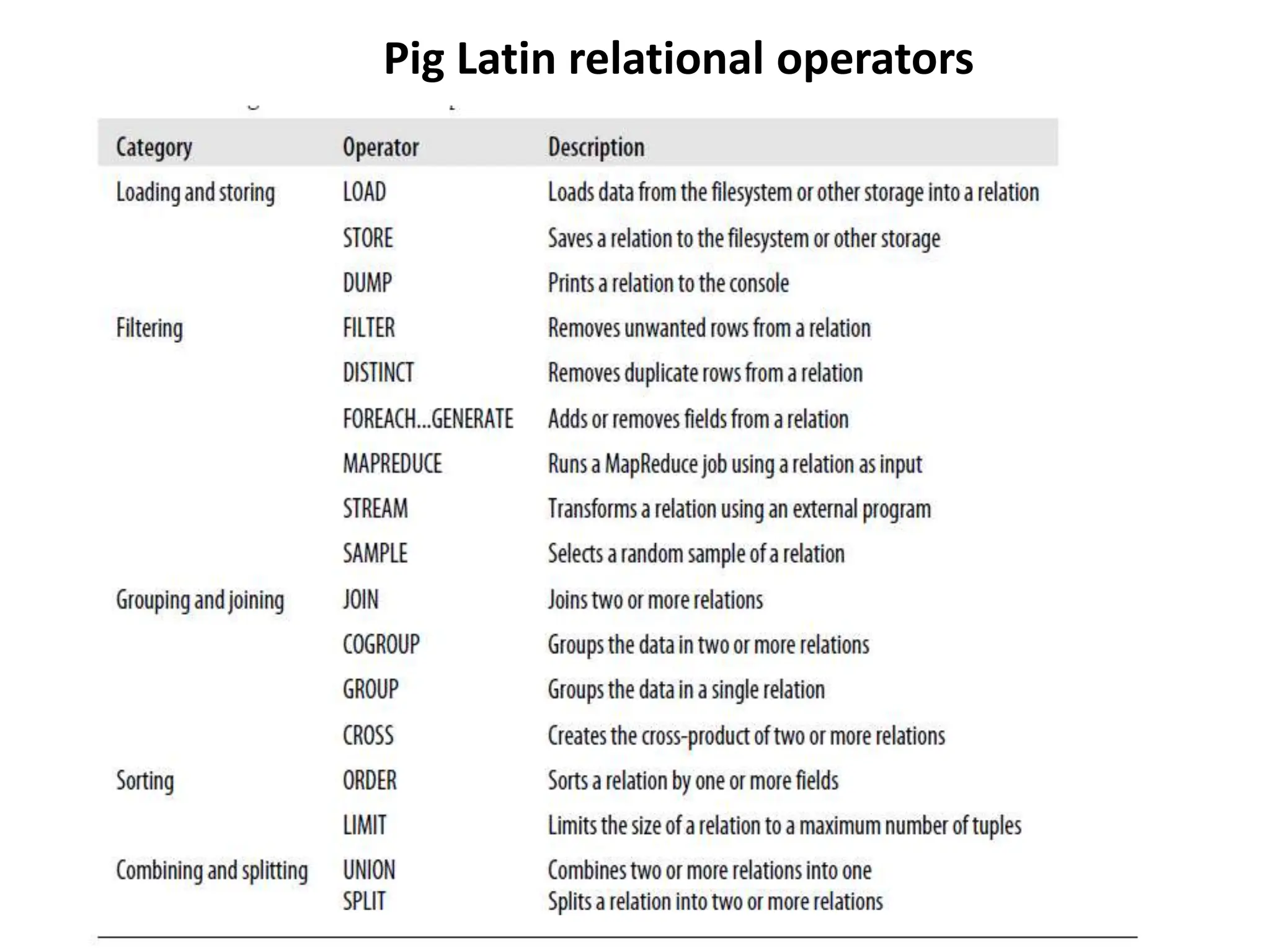
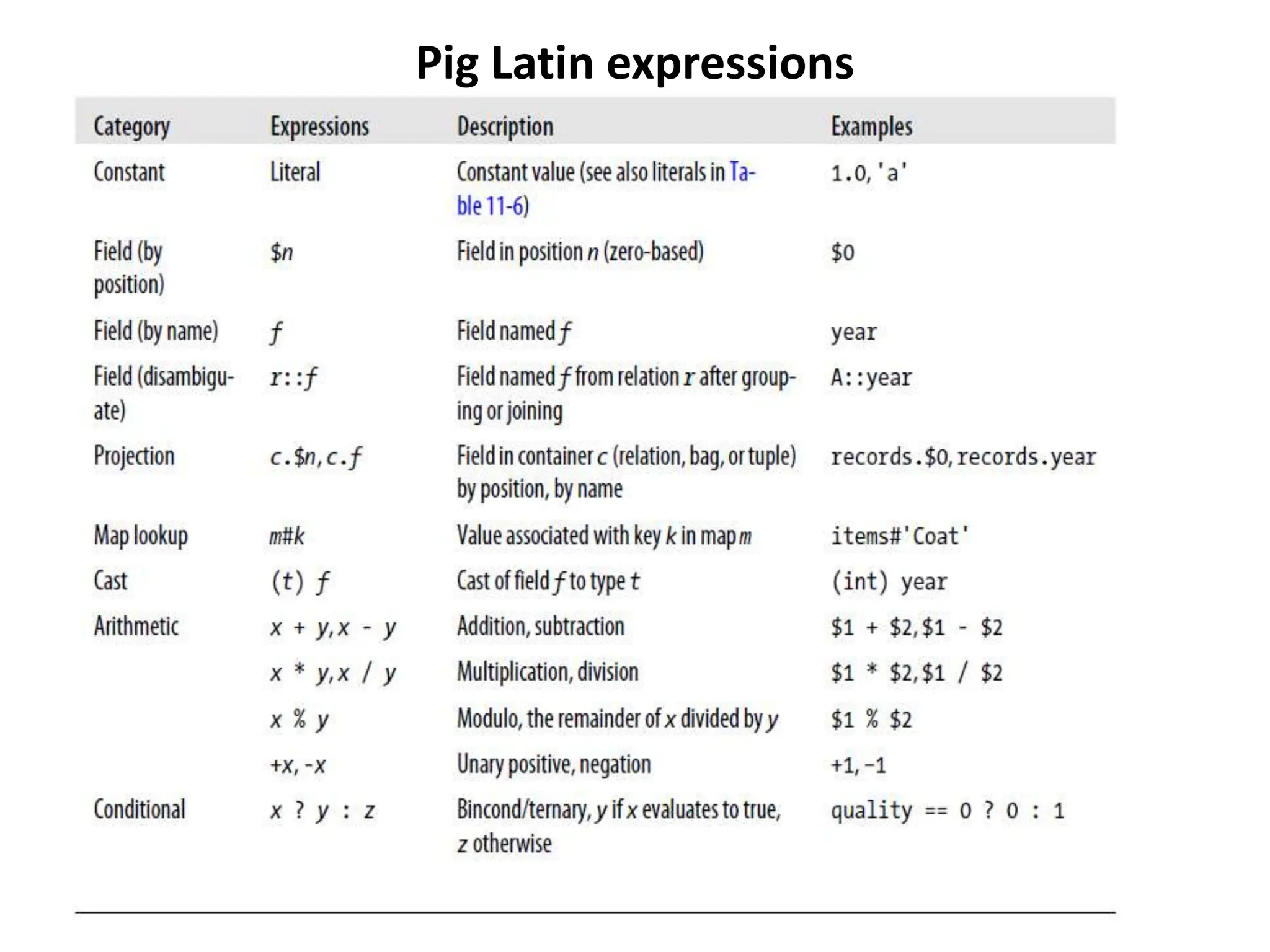
Pig is a data flow language and execution environment for exploring very large datasets. It runs on Hadoop and MapReduce clusters. Pig Latin is the language used to express data flows in Pig programs. It allows for both declarative querying using high-level constructs as well as procedural programming using low-level operations. Pig Latin programs are compiled into a logical plan and then optimized and executed as MapReduce jobs on a Hadoop cluster. Pig supports complex nested data structures and user-defined functions.