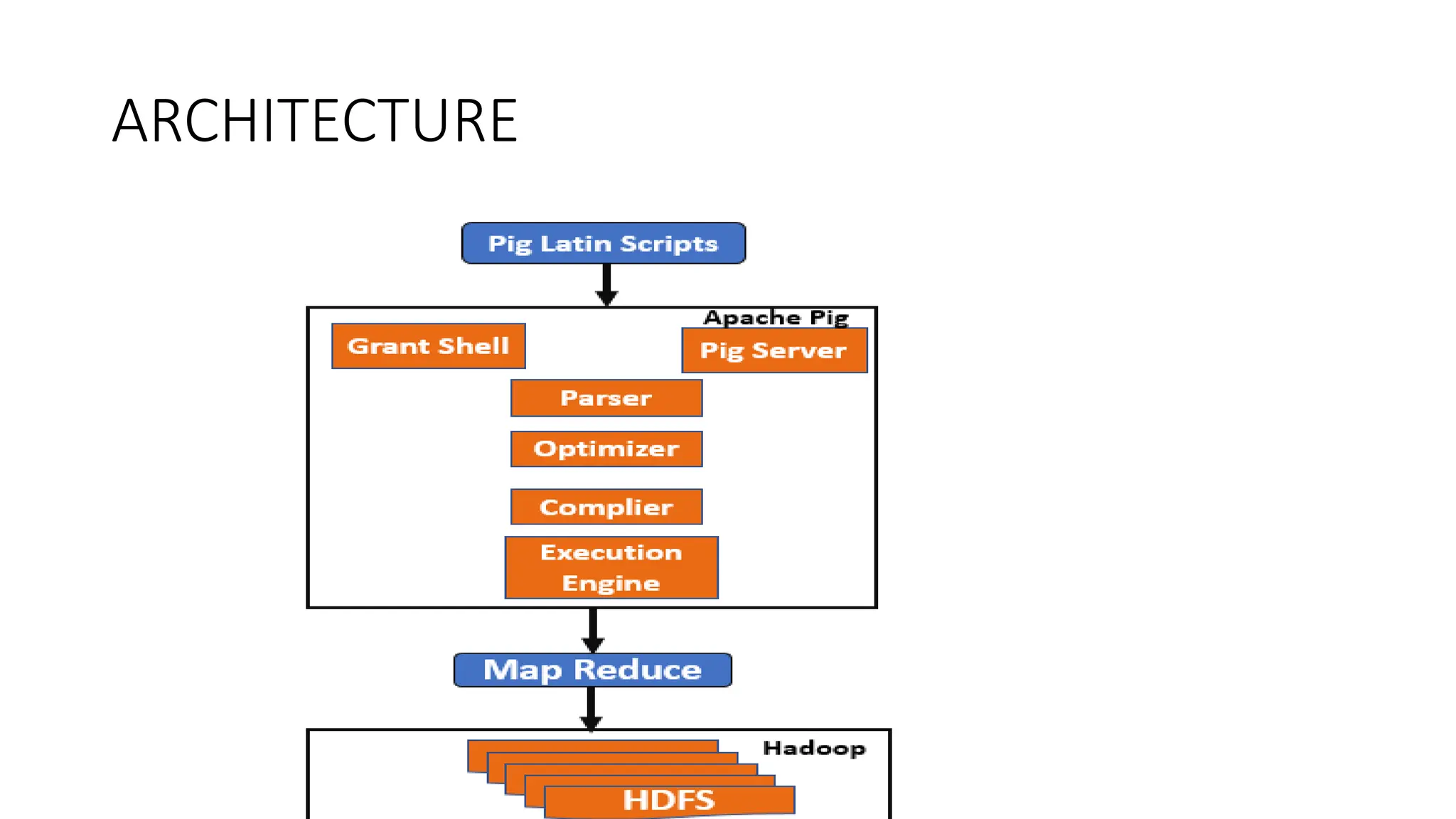
Apache Pig is a platform designed for analyzing large datasets, featuring a high-level language called Pig Latin for expressing data analysis programs, which are optimized for parallel execution via a compiler that generates MapReduce jobs for Hadoop. The architecture includes a parser, optimizer, compiler, and execution engine, enabling users to write and maintain data transformations easily while allowing for optimizations and extensibility. Pig operates in two modes: local mode for small datasets and MapReduce mode for larger datasets within HDFS, with an interactive shell called Grunt for executing commands.














![Piglatin operators
• Arithmetic operator
• Relational operations
-load,store,filter,distinct,join,group,order,limit etc
• Comparision operator
• Type construction operator
()- tuple constructor,[]-map constructor,{}-bag constructor
• Diagnostic operator
1. dump,
2.describe-to verify the schema of a relation,
3.Explain-to verify the logical plan,physical plan and mapreduce plan of a relation
4.Illustration-to review how the data are transformed](https://image.slidesharecdn.com/pig-240214070419-9f3056f1/75/A-slide-share-pig-in-CCS334-for-big-data-analytics-16-2048.jpg)






















![Unit-5 [Pig] working and architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit-5pig-240605082042-8125c633-thumbnail.jpg?width=640&height=640&fit=bounds)
































