Downloaded 151 times
![Università degli Studi di Milano Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione Lezione 16 TROVARE L’INFORMAZIONE Corso Web 2.0 2 Roberto Polillo [email_address] www.rpolillo.it R.Polillo – Corso Web 2.0 (dic 2008)](https://image.slidesharecdn.com/web20lez16-1228147041308288-9/85/Corso-Web-2-0-Trovare-l-informazione-1-320.jpg)
![Università degli Studi di Milano Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione Lezione 16 TROVARE L’INFORMAZIONE Corso Web 2.0 2 Roberto Polillo [email_address] www.rpolillo.it R.Polillo – Corso Web 2.0 (dic 2008)](https://image.slidesharecdn.com/web20lez16-1228147041308288-9/75/Corso-Web-2-0-Trovare-l-informazione-1-2048.jpg)









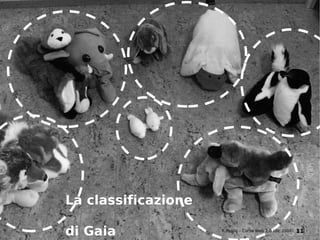

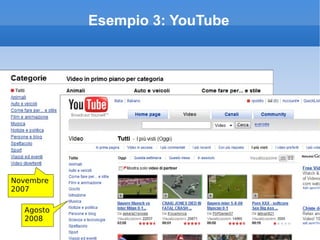











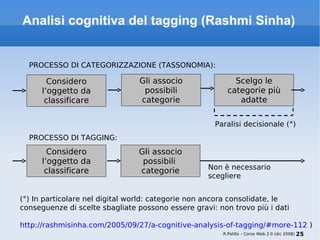

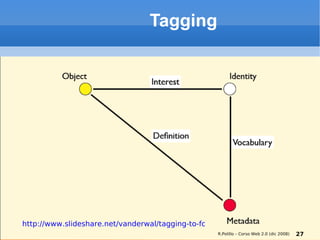
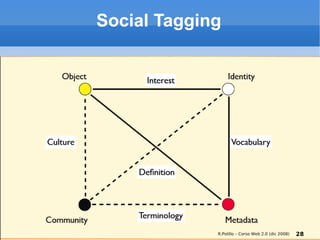


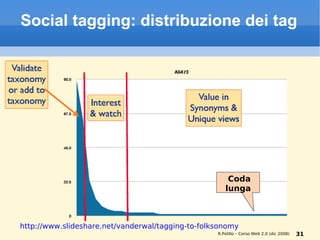








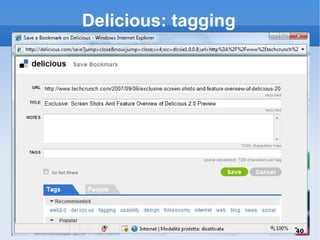























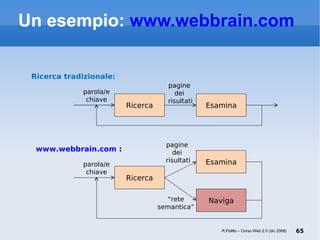
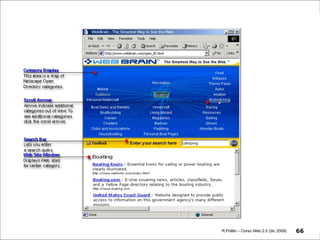









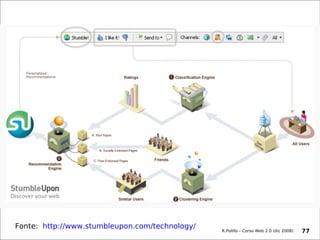

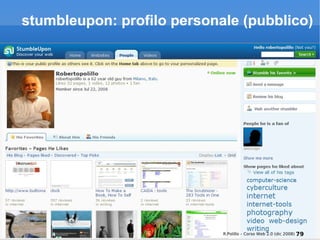





Il documento fornisce una panoramica su come trovare informazioni nel web 2.0, evidenziando quattro modalità principali: servizi di directory, strumenti di ricerca, servizi di feed e esplorazione. Vengono discussi anche i concetti di tassonomia e folksonomy, evidenziando le difficoltà di classificazione e l'importanza del tagging sociale. Inoltre, viene trattata l'architettura dell'informazione e come essa influenzi la ricerca e l'organizzazione dei contenuti online.


































































