Download as PDF, PPTX







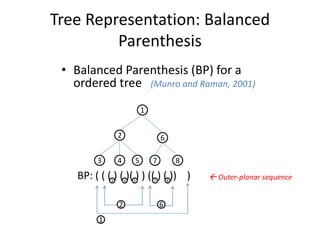



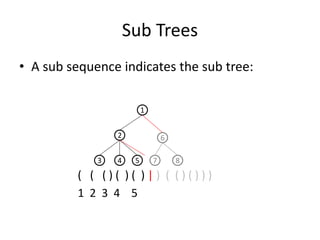
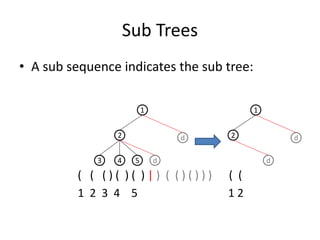
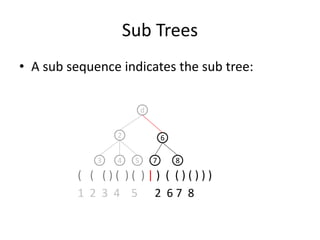
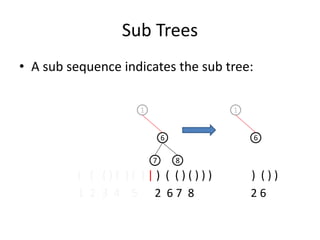
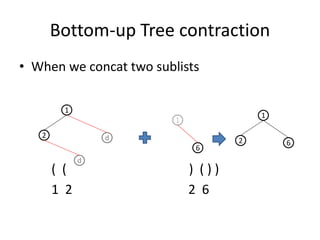



![Bottom-up Build a Tree
• A list a items as input
• Make a sparse list of “leaf”:
E.g.: [ ((0,100),False, 100, data1), ((0,101), True, 100,
null) , ( (0, 200), False, 200, data2), ( (0, 201), True, 200,
data2) .. ]
( 100) (200) (300) (400) ….
• Insert parents
( ( 100) (200) ) ( (300) (400) )….
50 250](https://image.slidesharecdn.com/treerepresentationinmapreduceworld-151114051226-lva1-app6892/85/Tree-representation-in-map-reduce-world-21-320.jpg)



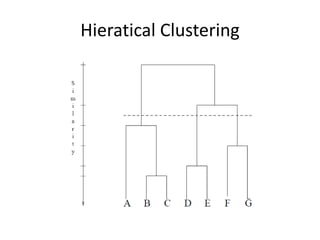






The document discusses the representation of tree structures within the MapReduce framework using a balanced parenthesis (bp) scheme. It outlines how files are divided, metadata management in a distributed file system, and methods for tree contraction and subtree representation. Additionally, it touches on practical applications such as XML transformation and hierarchical clustering algorithms within MapReduce.






















![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=640&height=640&fit=bounds)