Downloaded 45 times












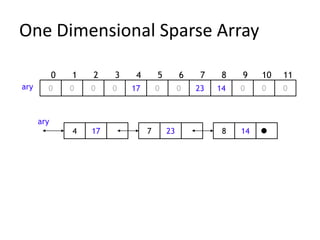
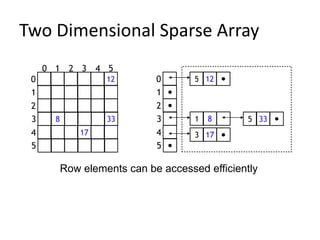
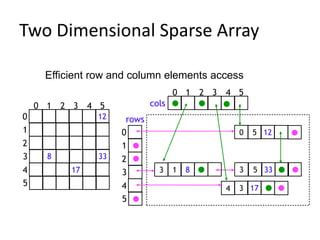
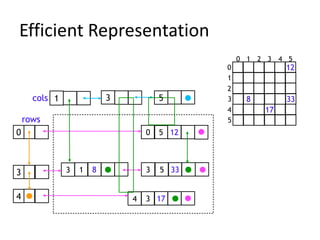




























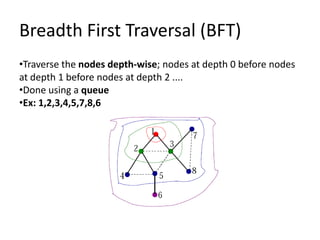
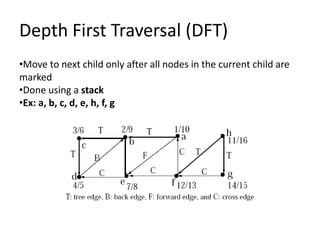


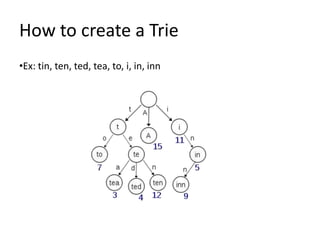

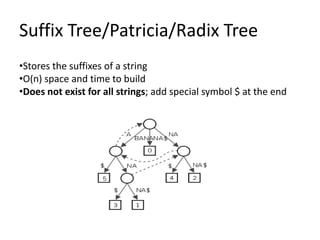



Data structures allow for efficient representation of data and solutions to real-world problems like insertion, deletion, search, and sort. Common data structures include arrays, linked lists, stacks, queues, trees, and hashes. Arrays use contiguous memory allocation while linked lists connect elements using pointers. Trees and hashes are useful for modeling hierarchical and associative data respectively. Recursion and traversal algorithms like breadth-first and depth-first are used to process tree and graph structures.


























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








