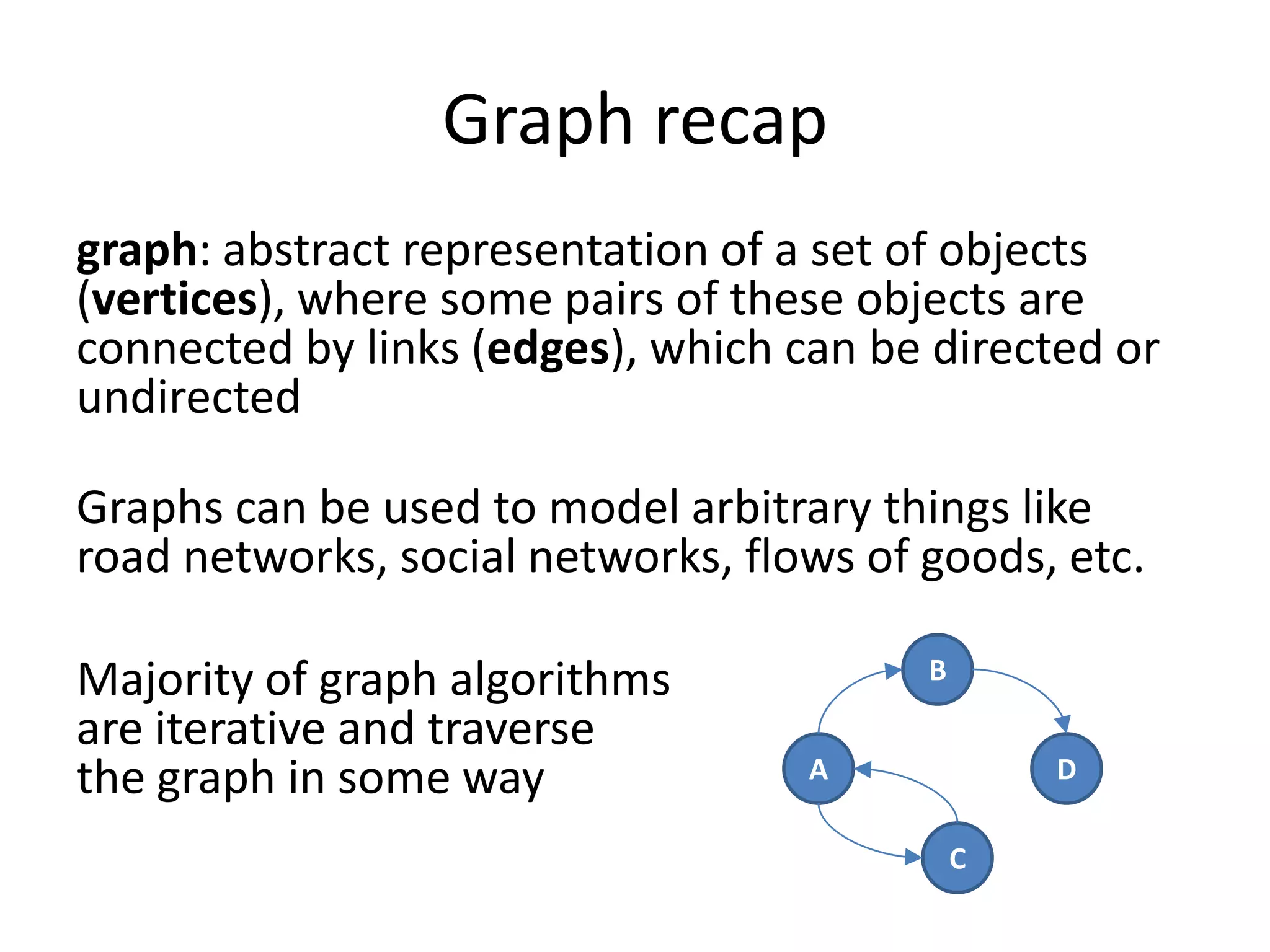
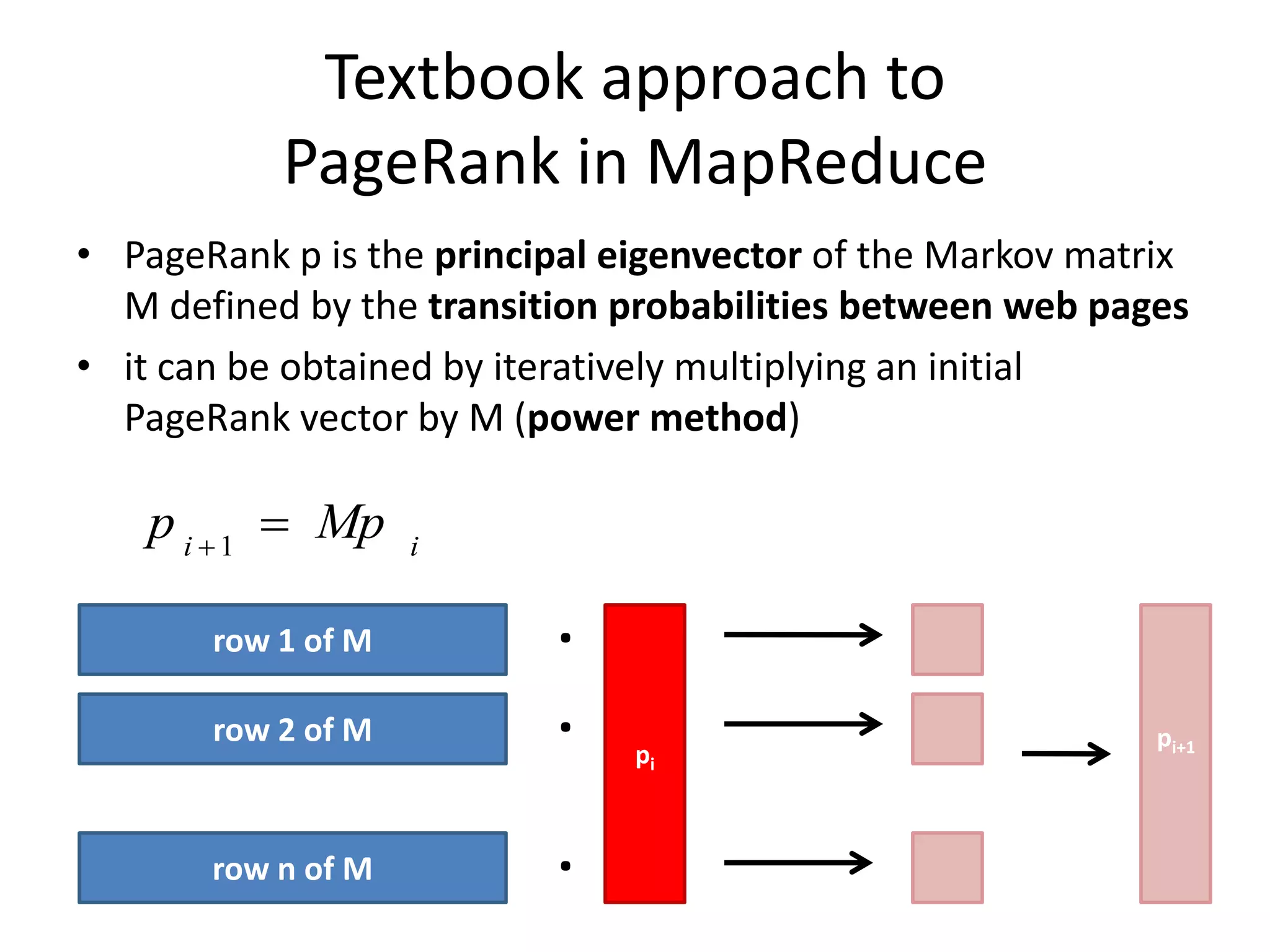
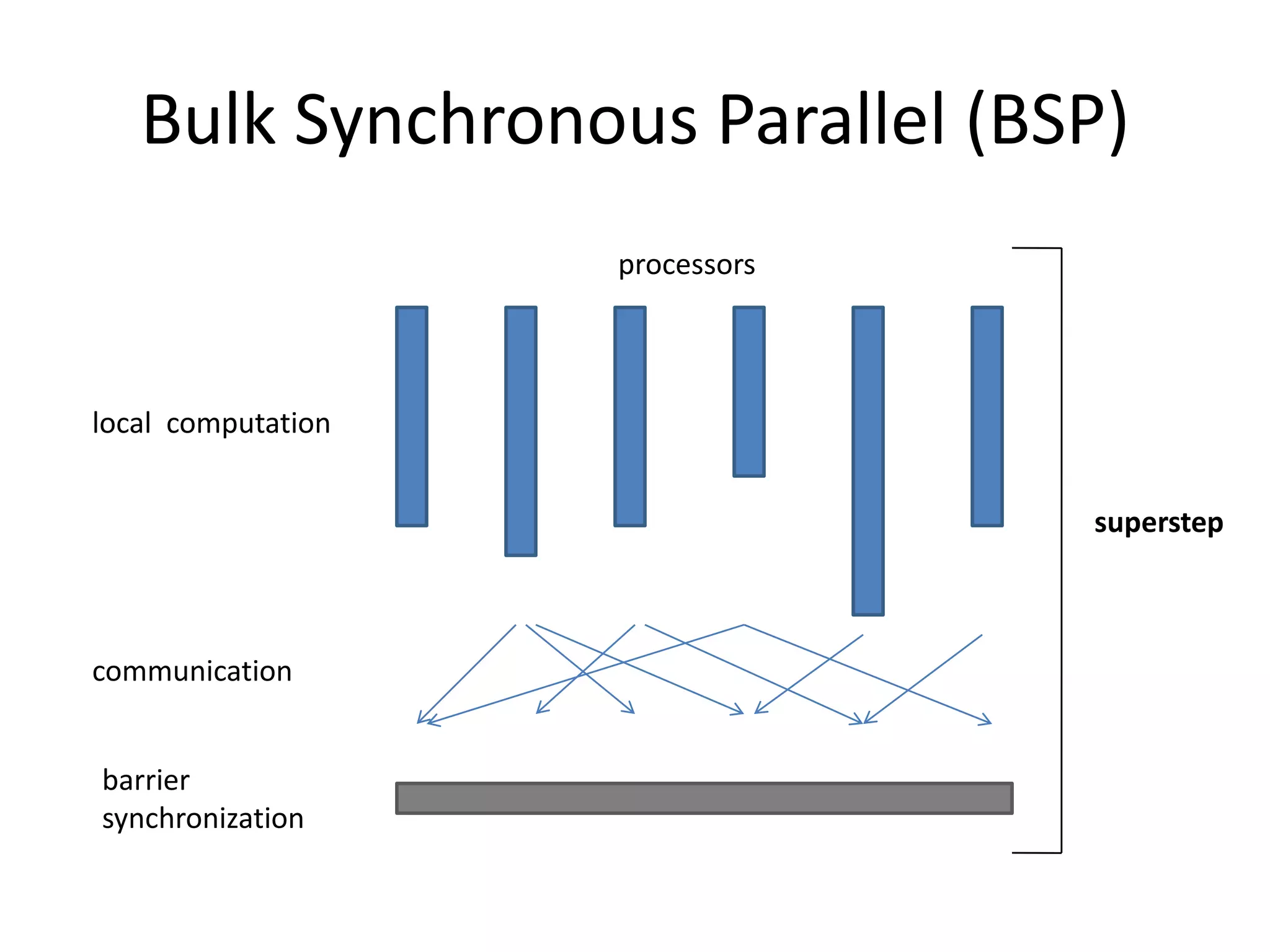
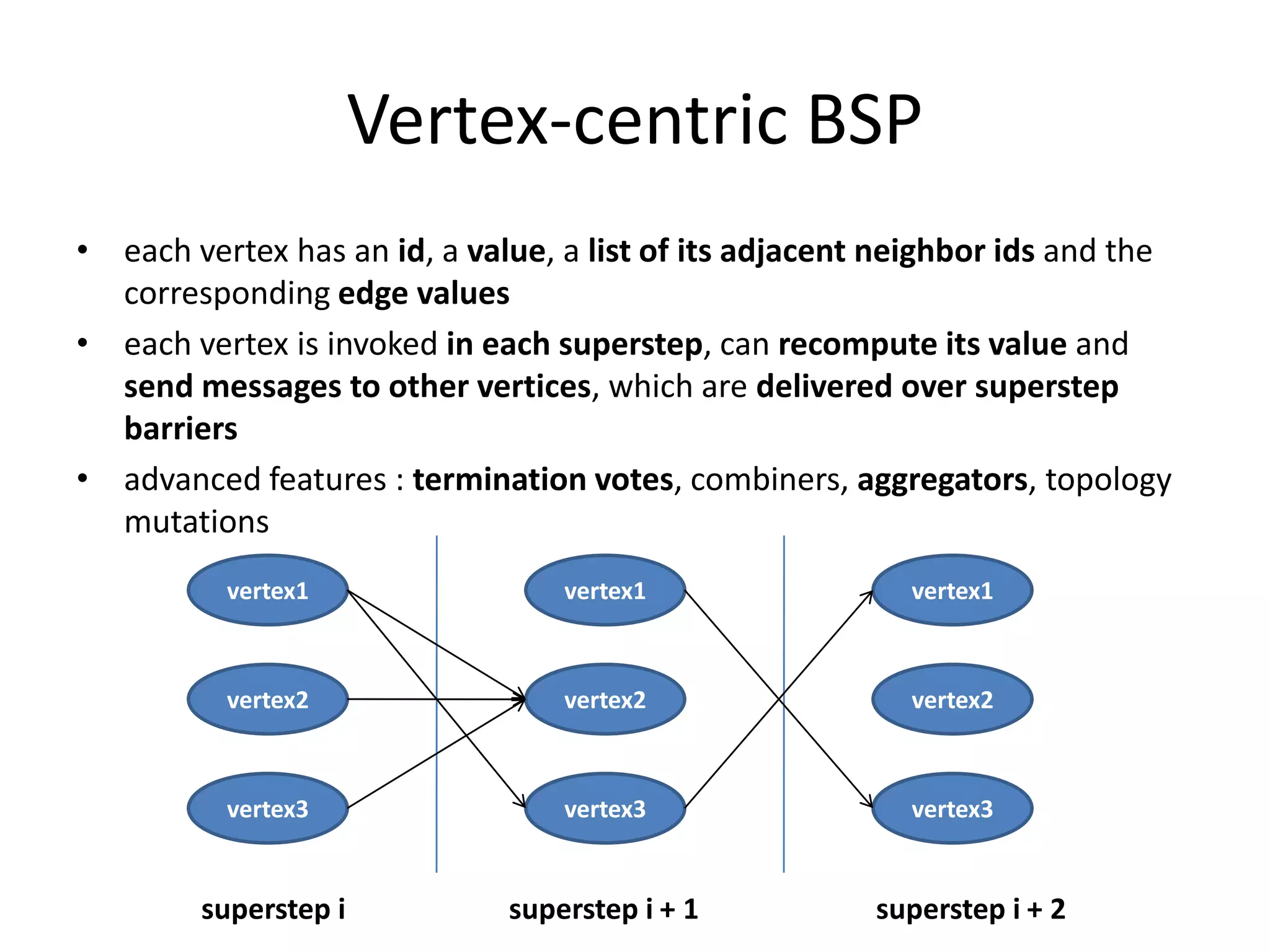
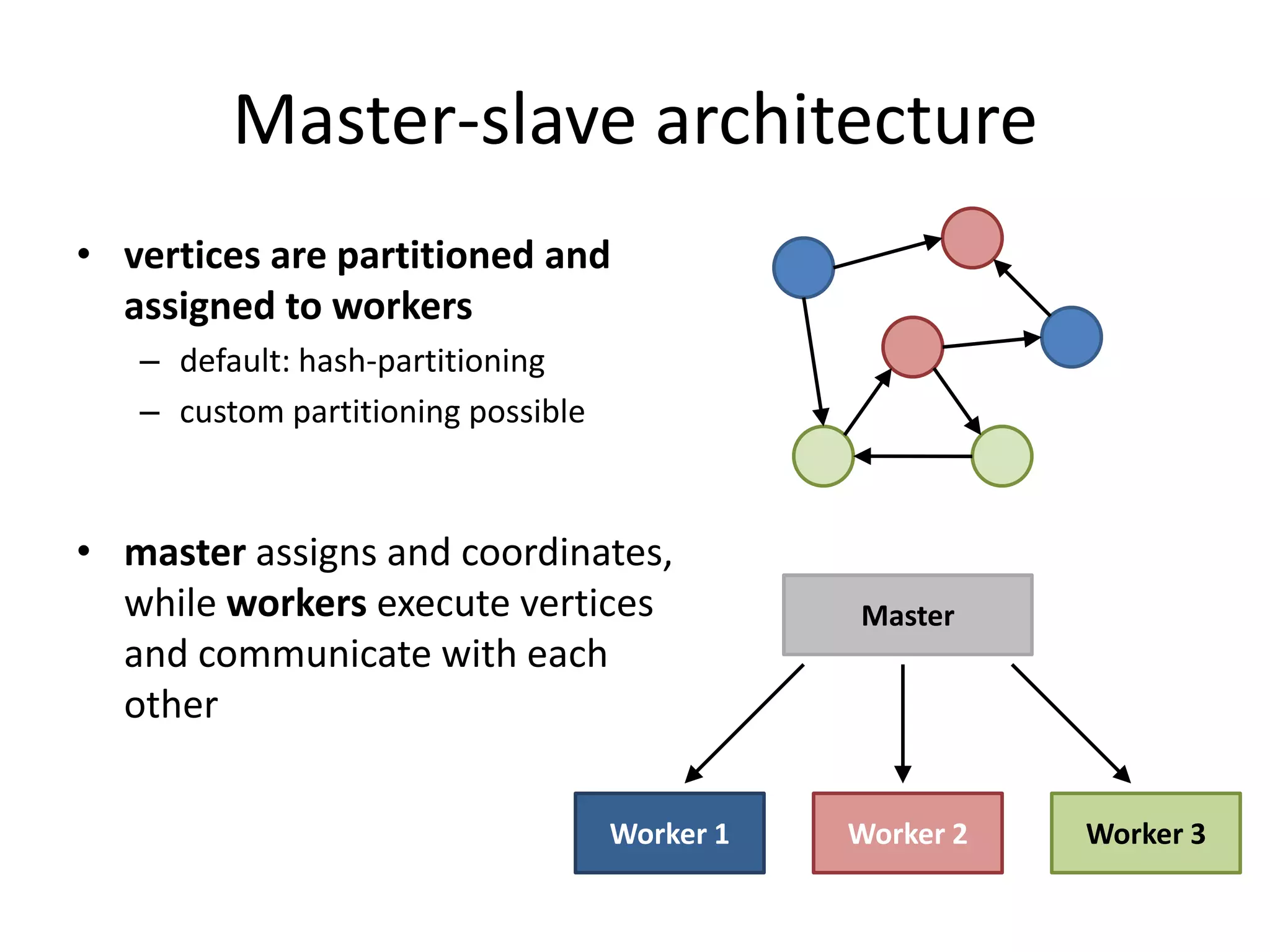
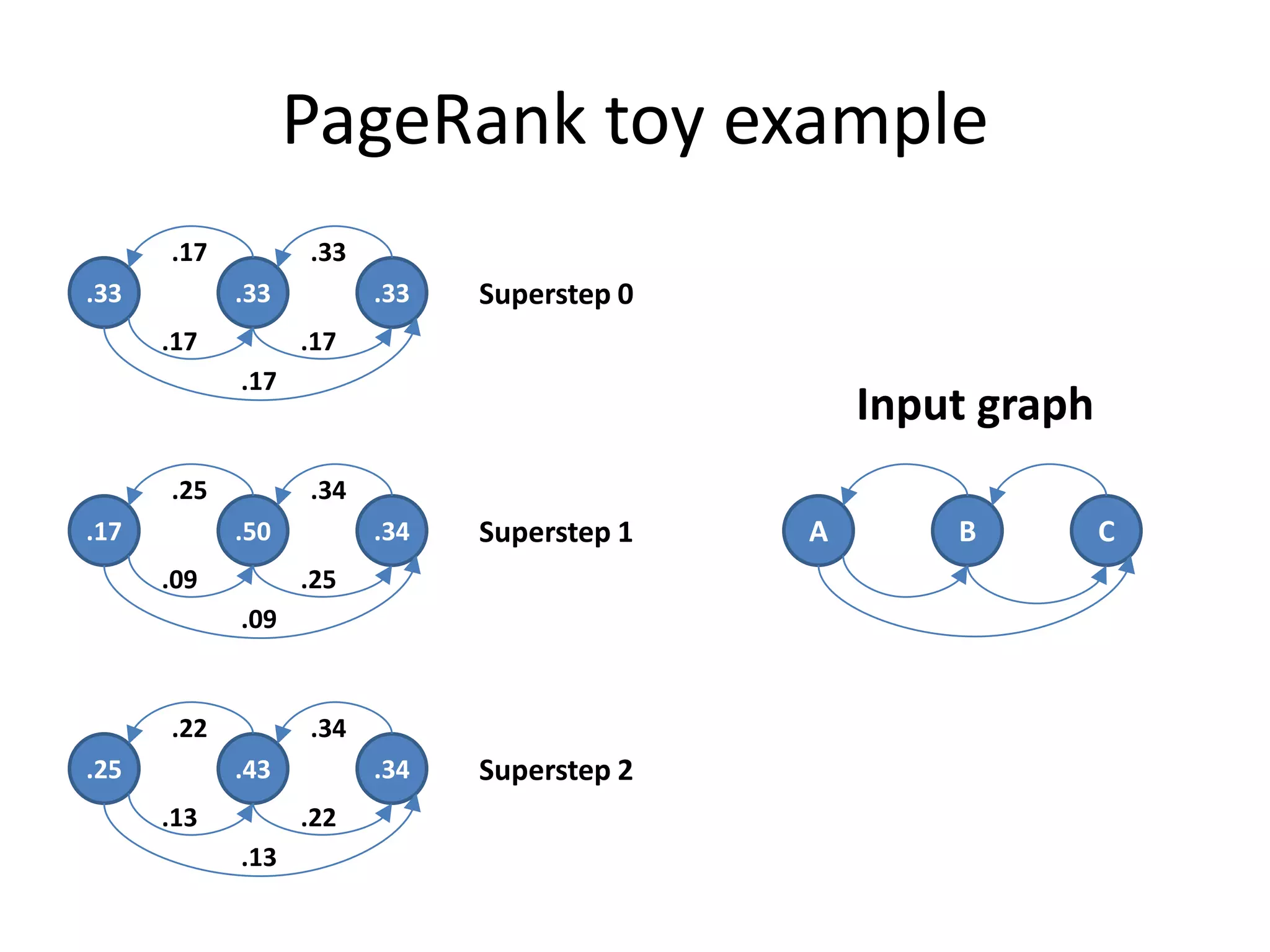
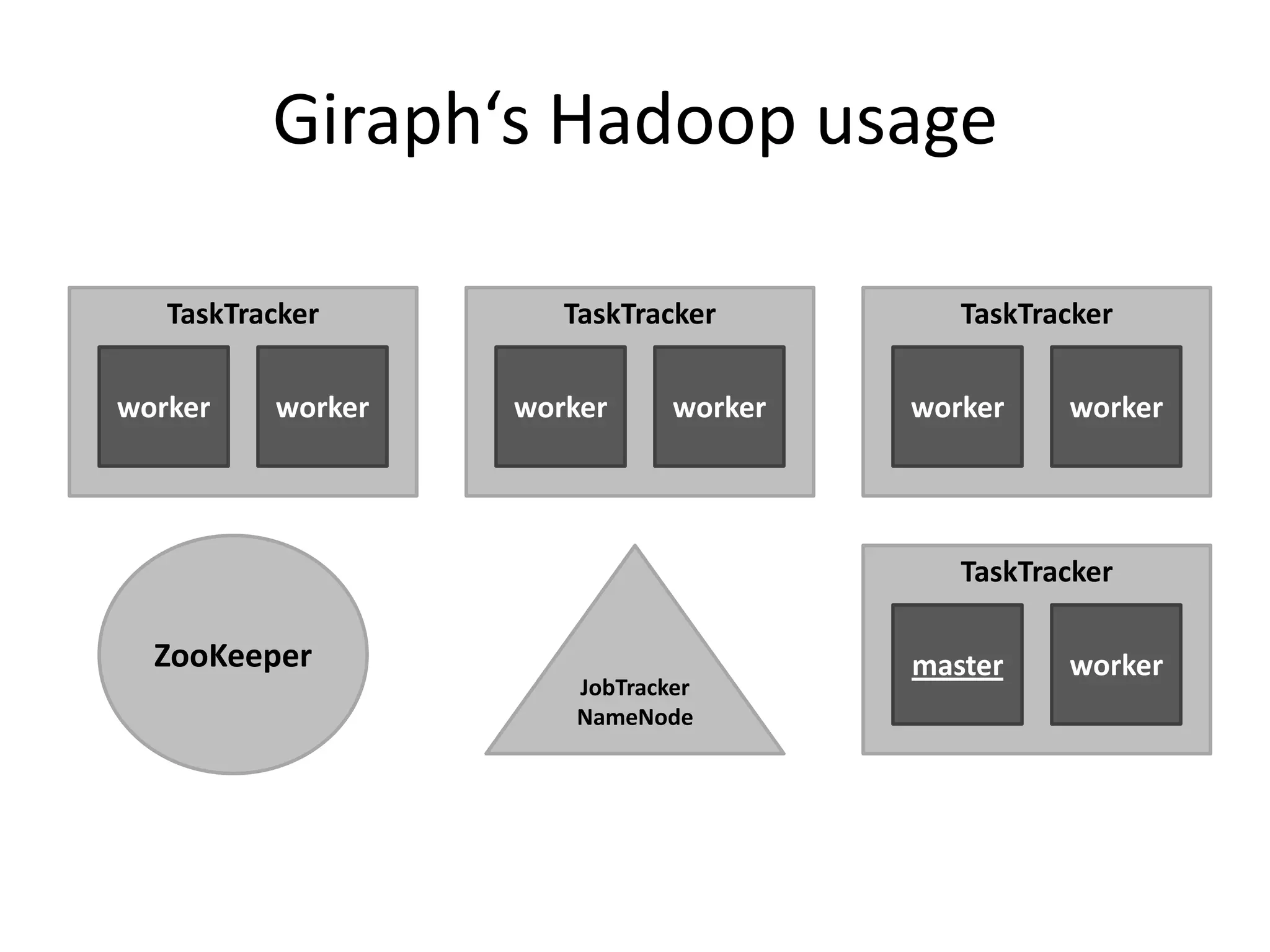
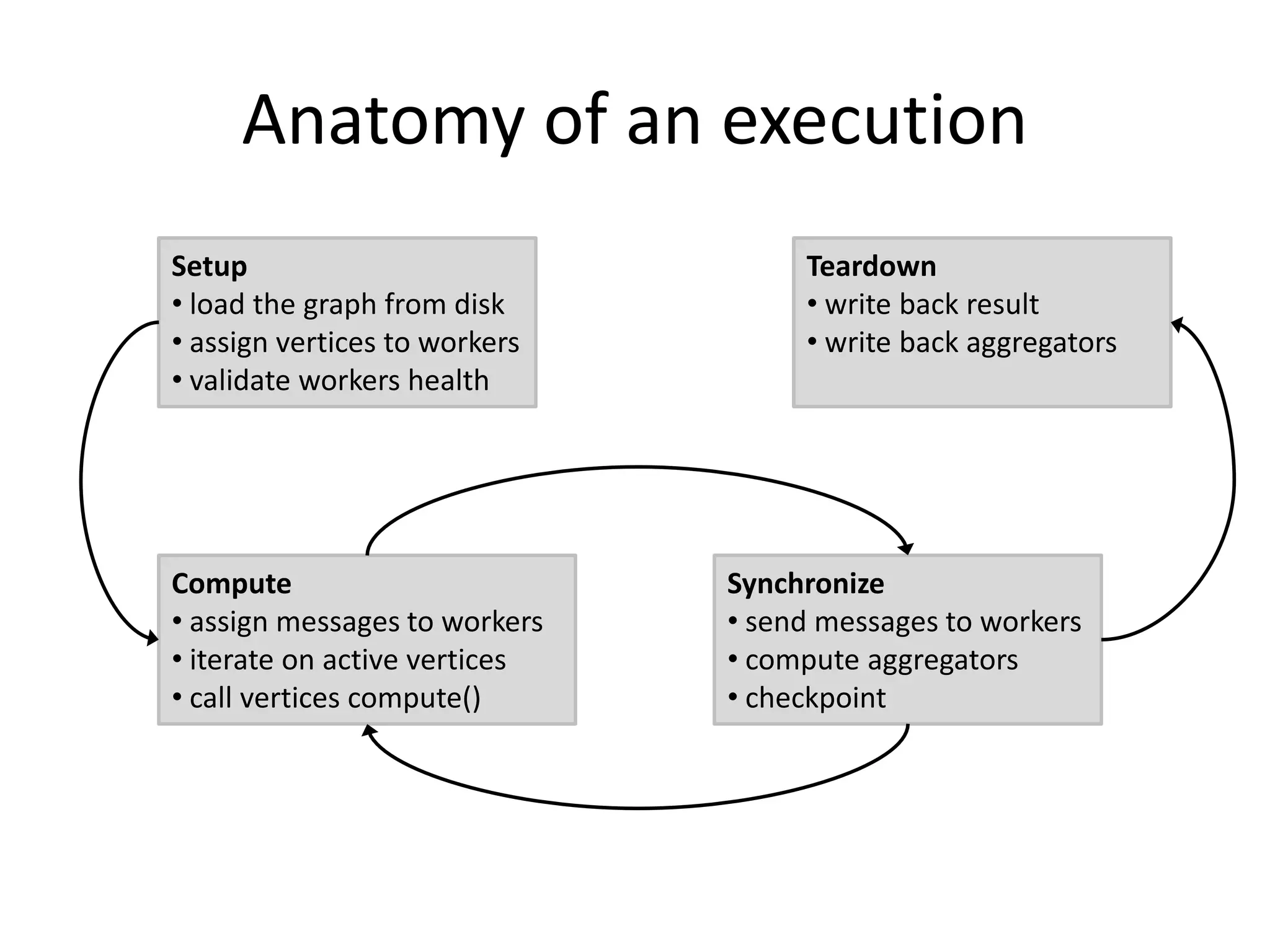
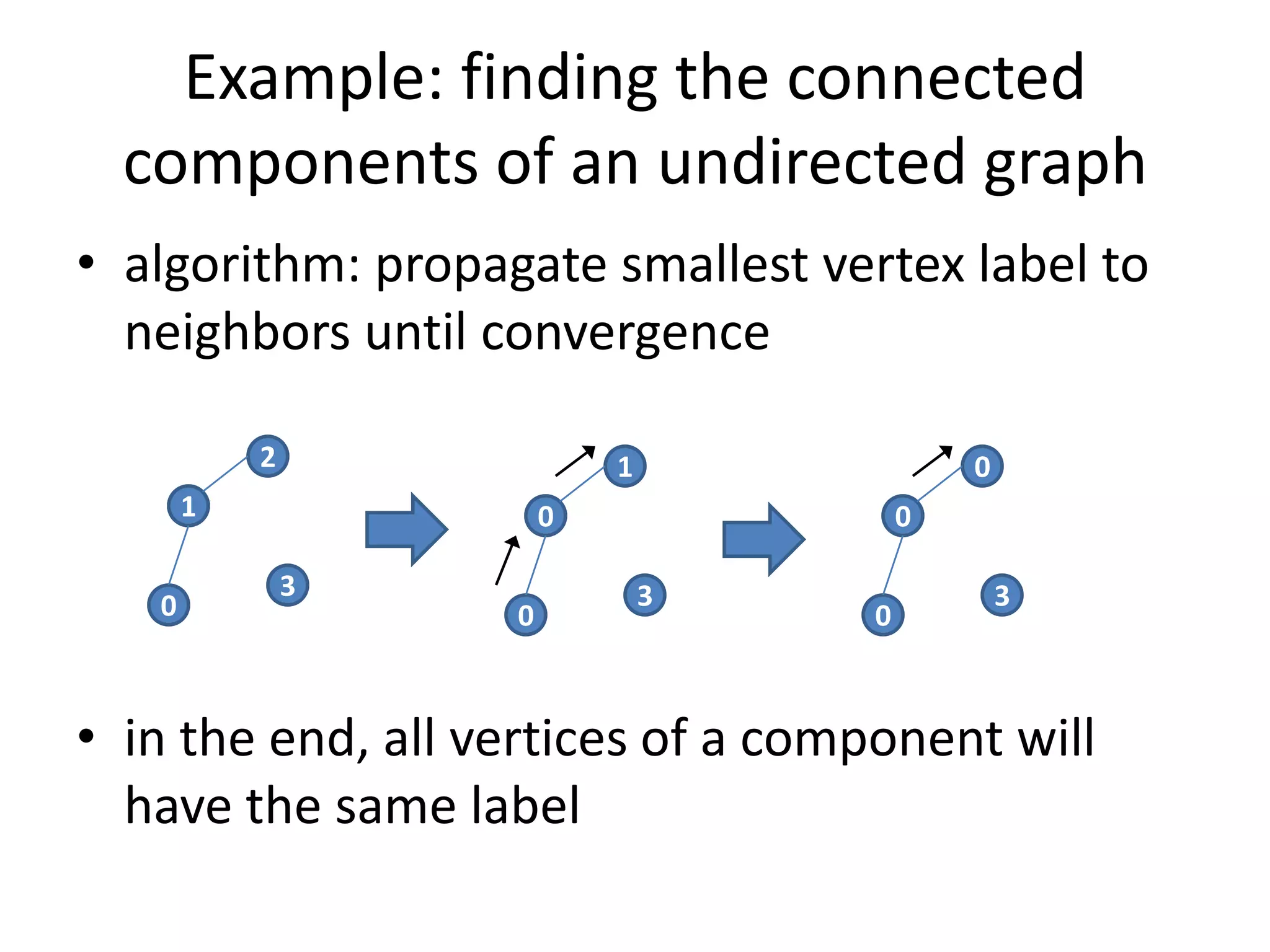
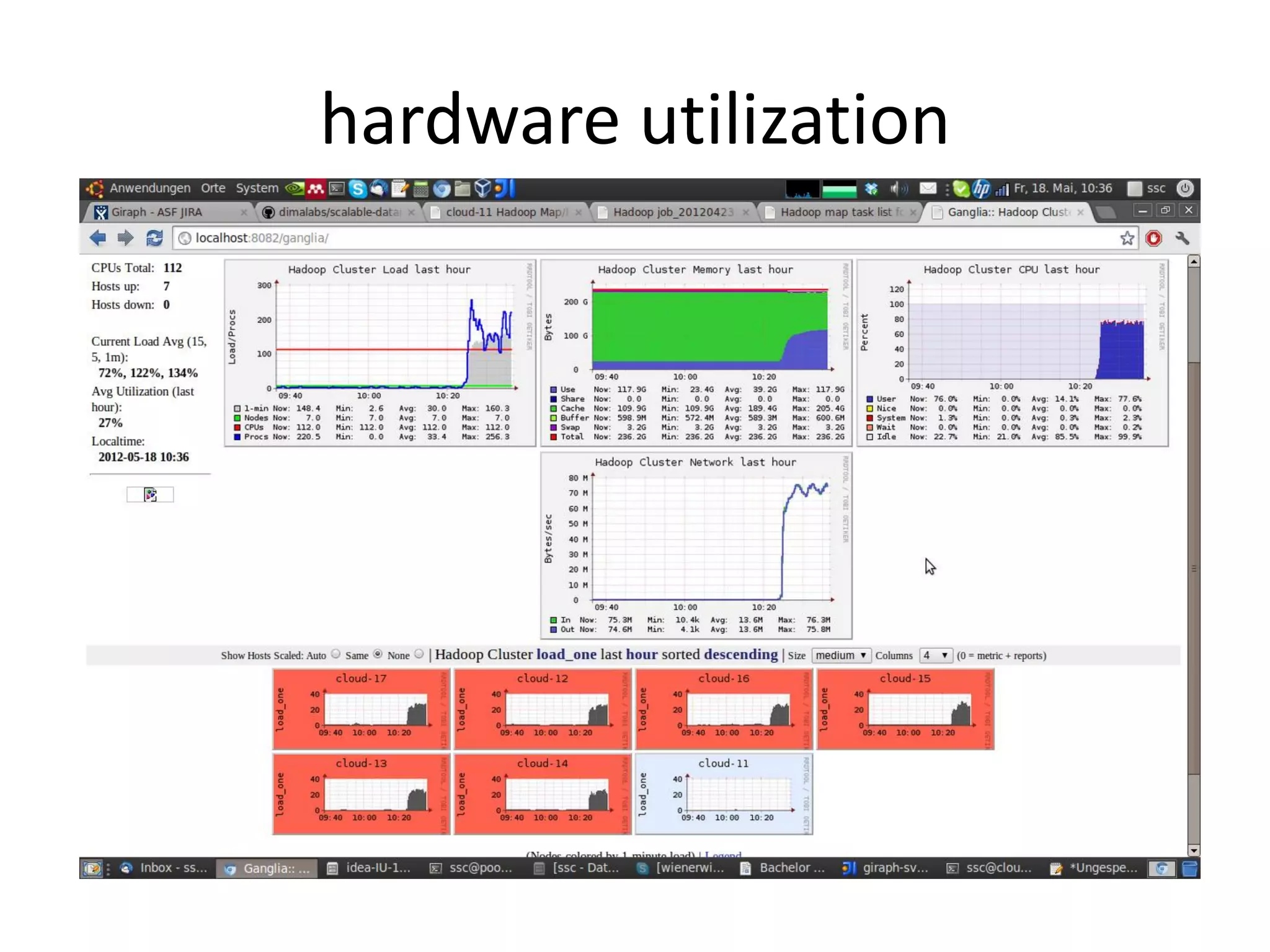
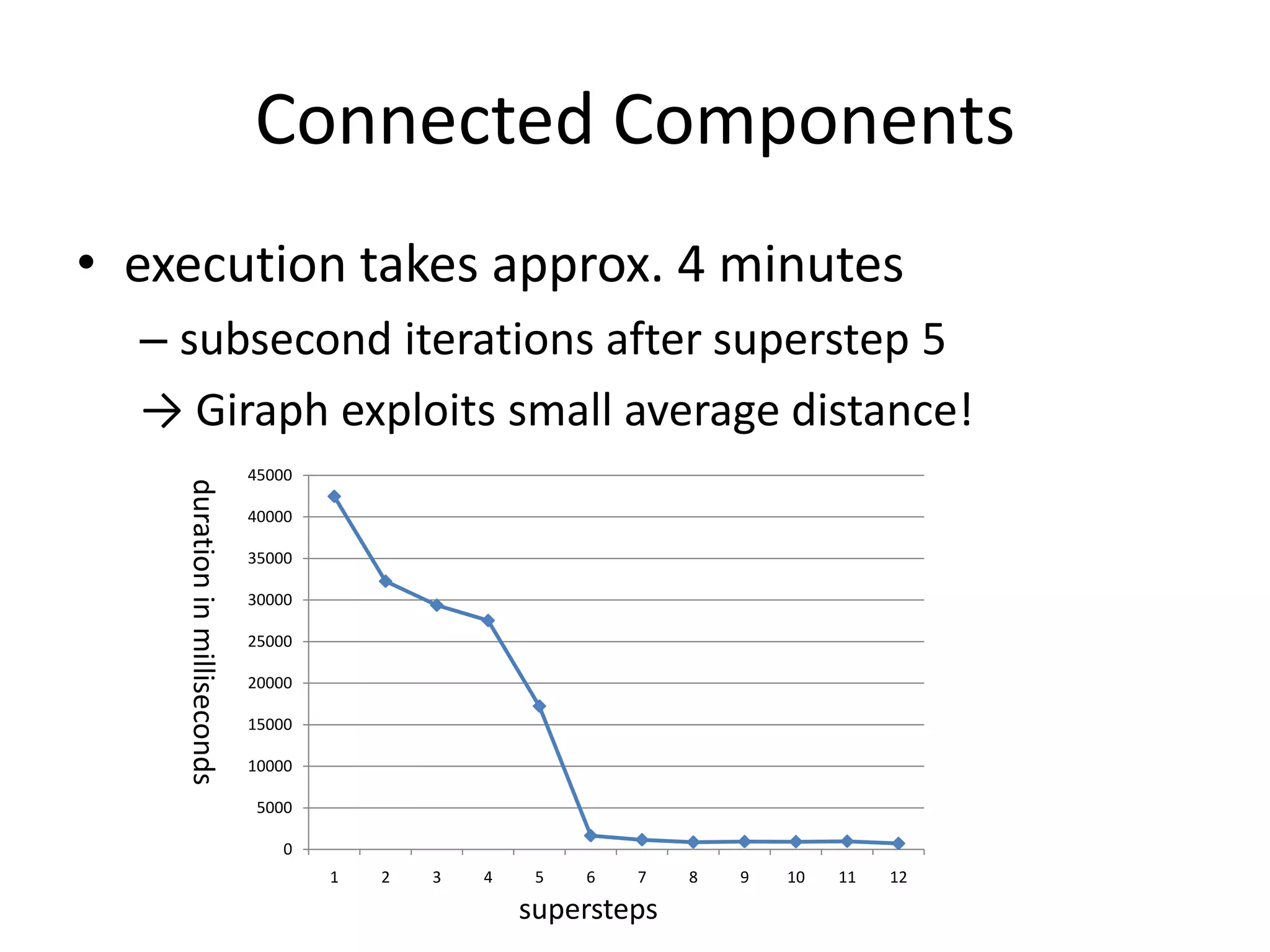
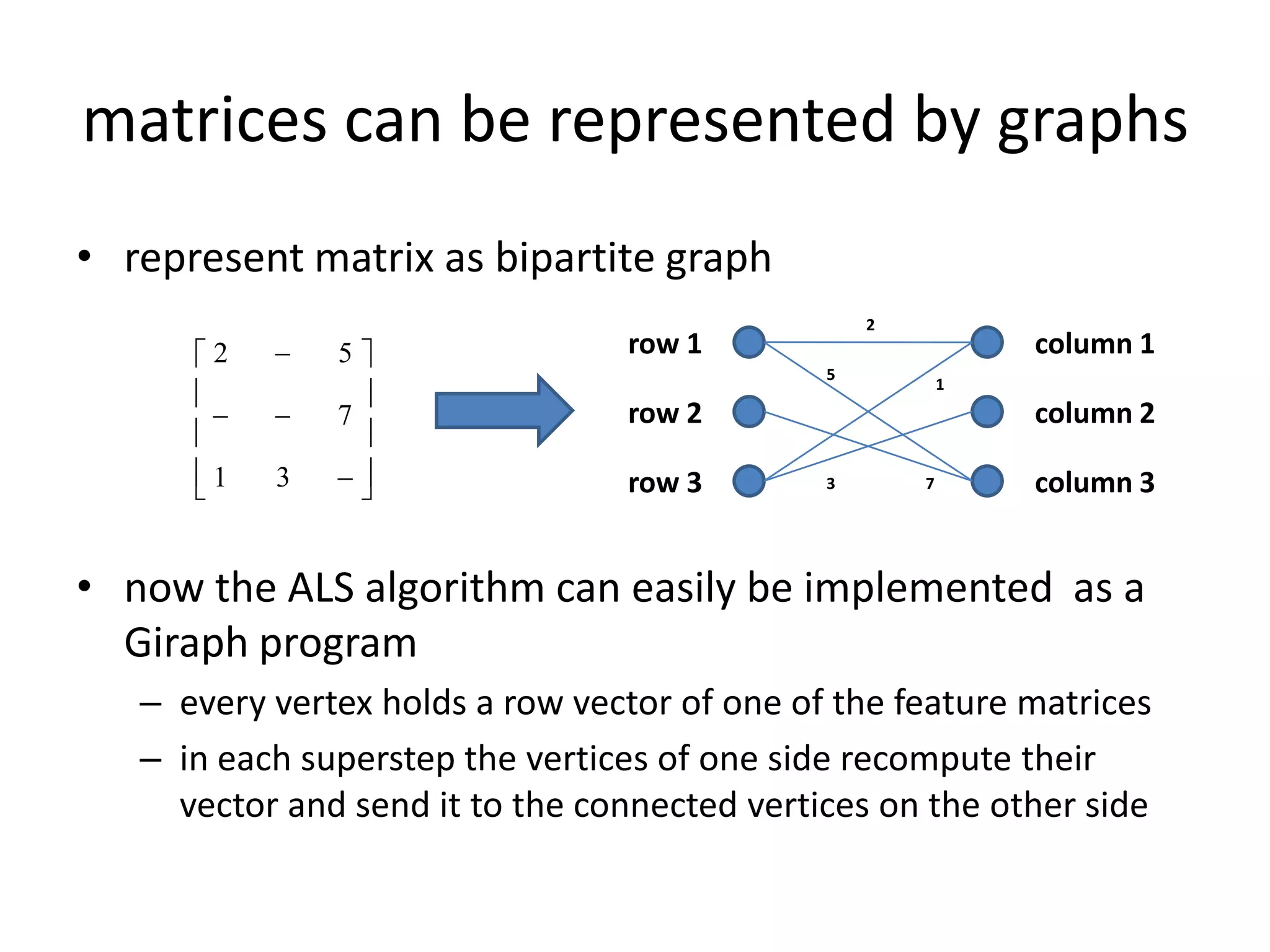
This document summarizes a talk on large scale graph processing using Apache Giraph. It begins with an introduction of the speaker and their research interests. It then provides an overview of graphs and challenges with graph processing using Hadoop/MapReduce. It describes Google's Pregel framework for graph processing and how Apache Giraph is an open source implementation of Pregel. Example graph algorithms like PageRank and connected components are demonstrated in Giraph. Experimental results show Giraph providing a 10x performance improvement over Hadoop for PageRank. The talk concludes that many problems can be modeled as networks and solved using graph processing frameworks like Giraph.