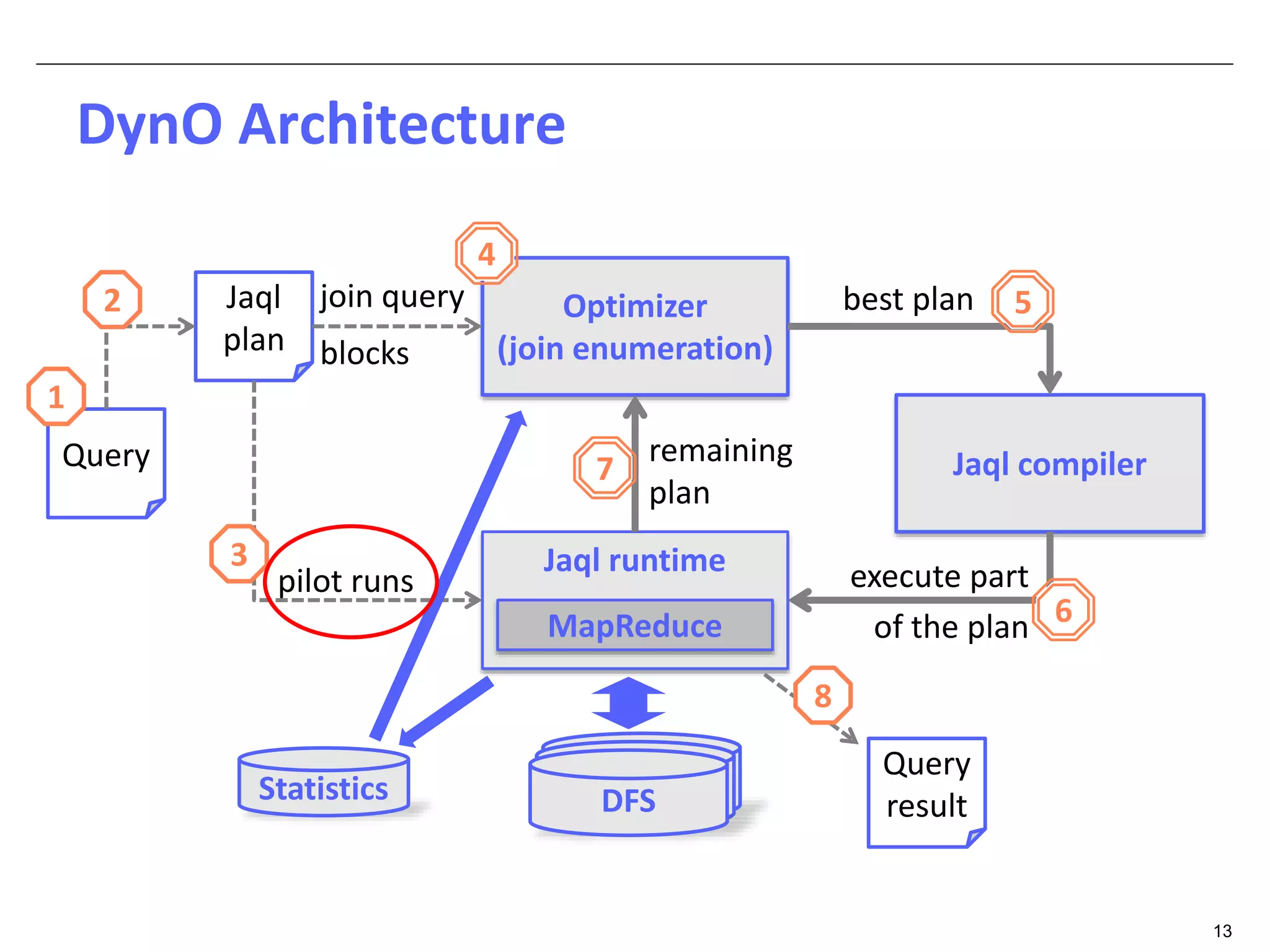
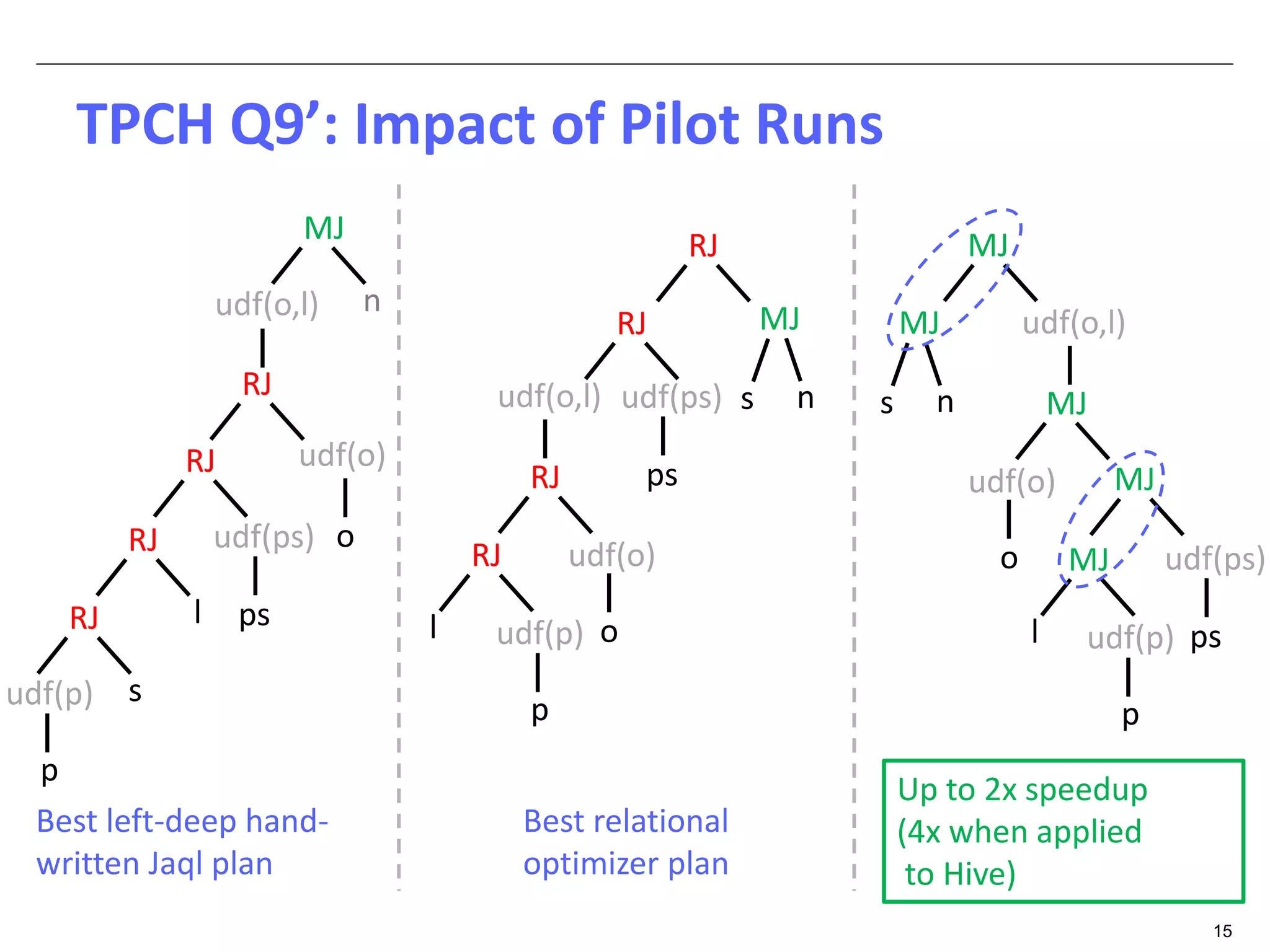
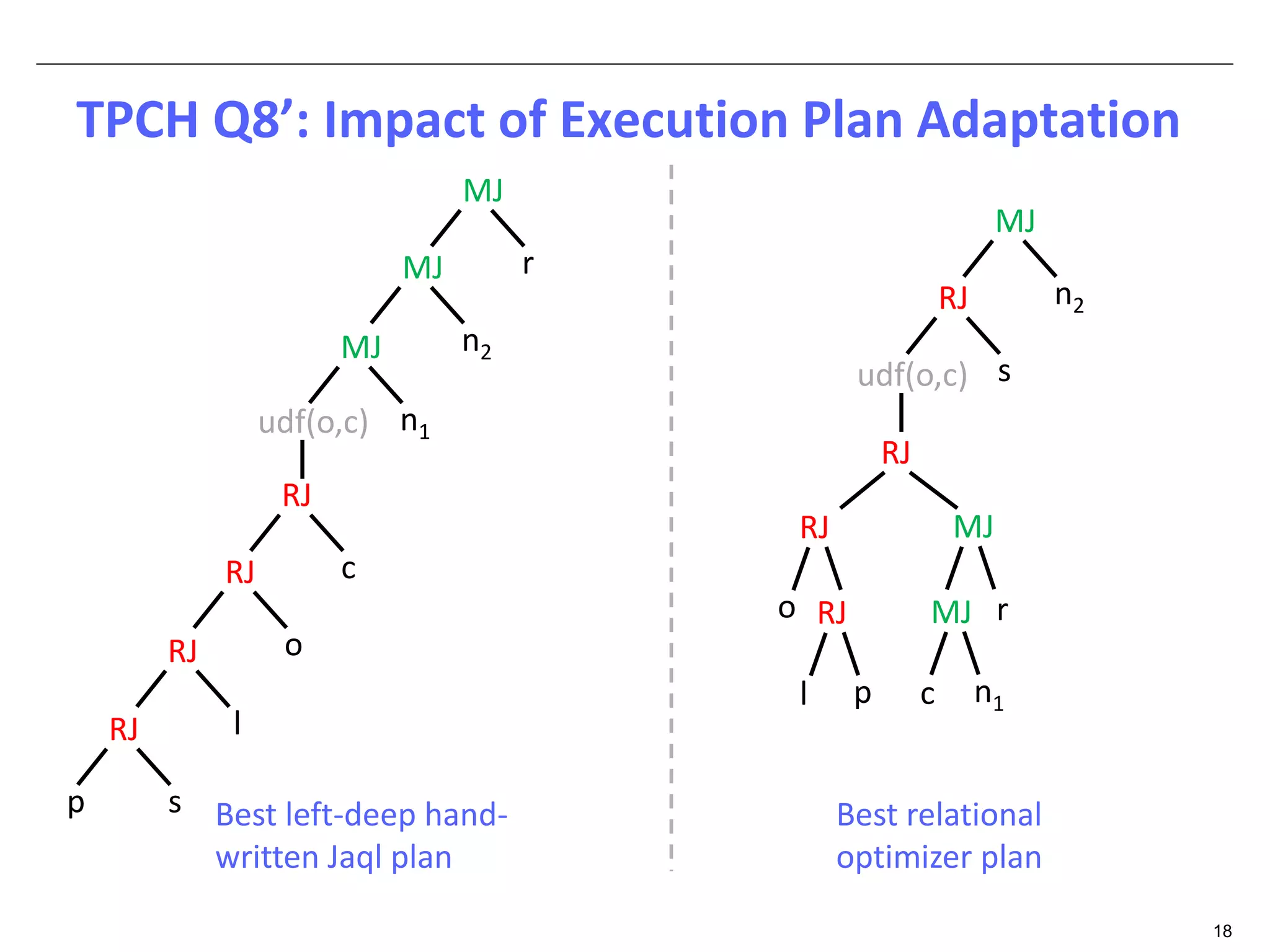
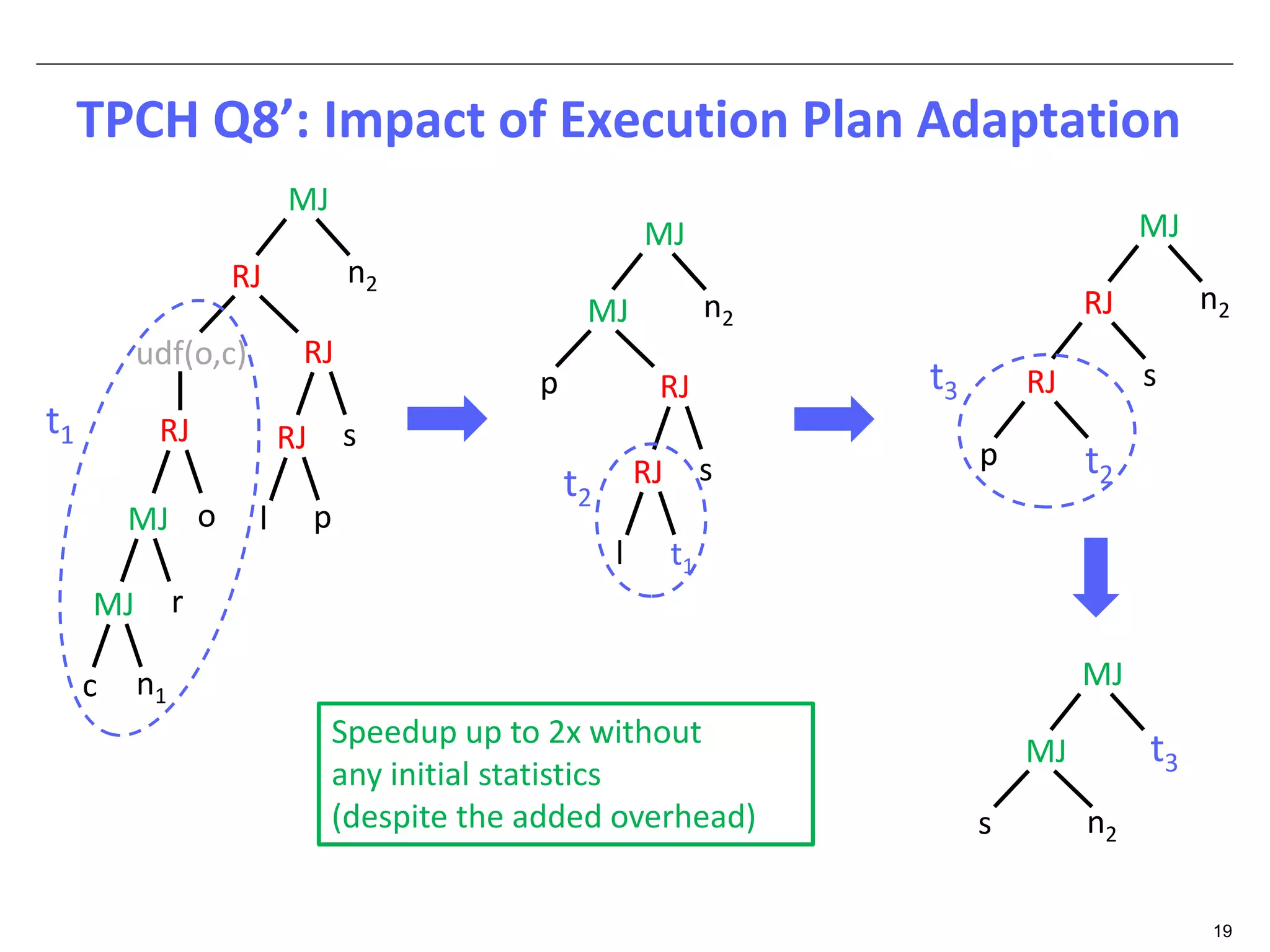
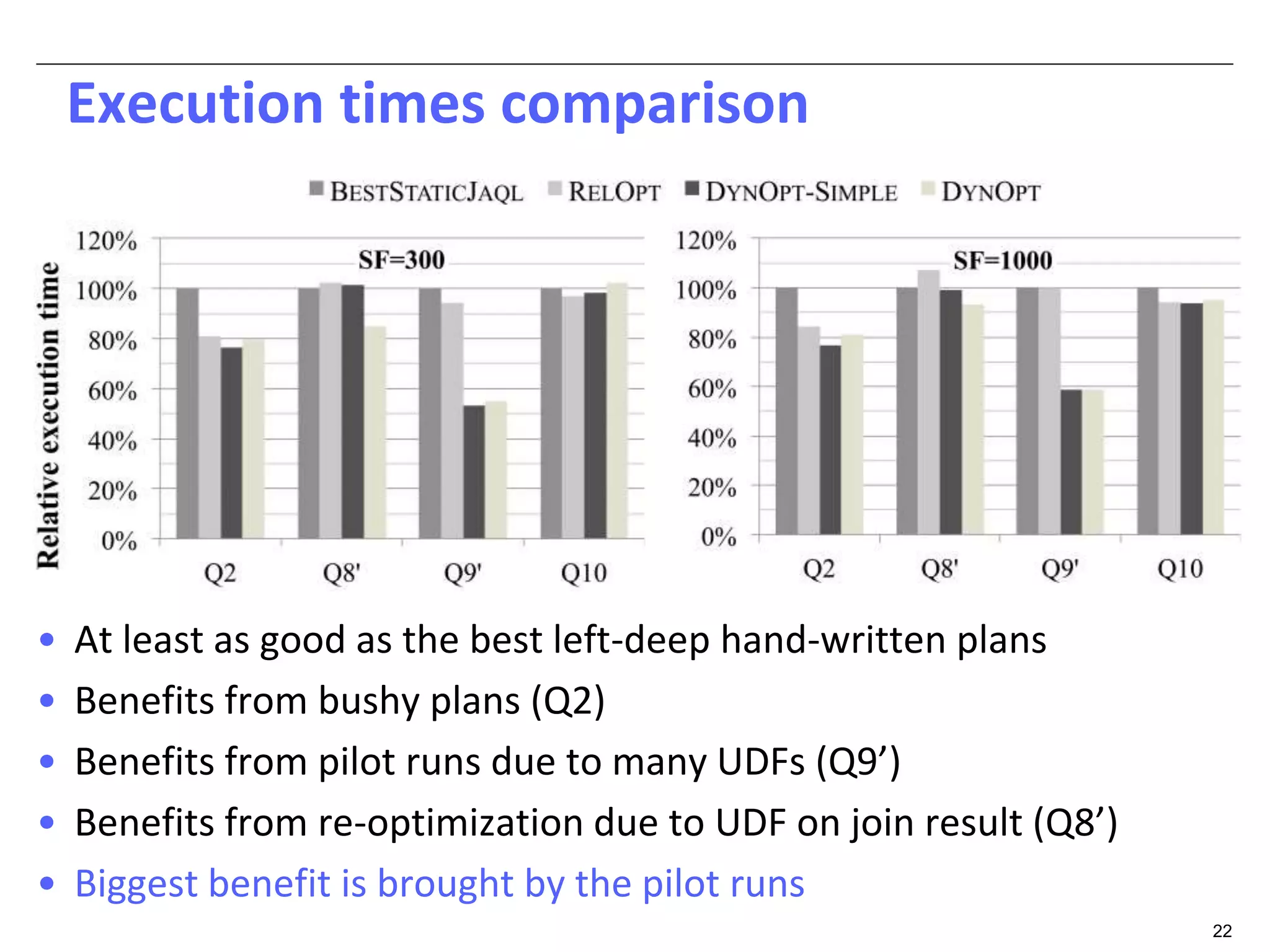
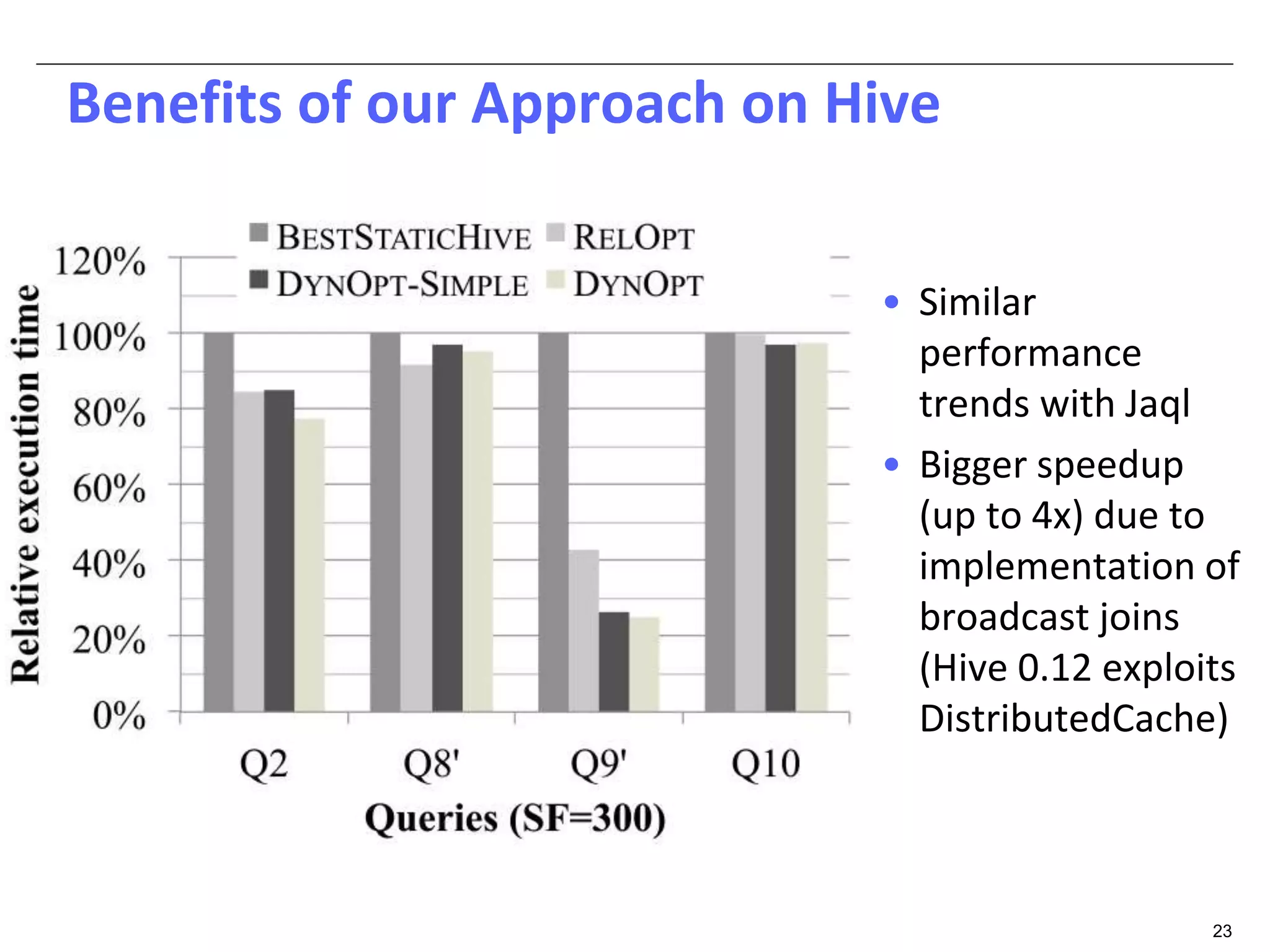
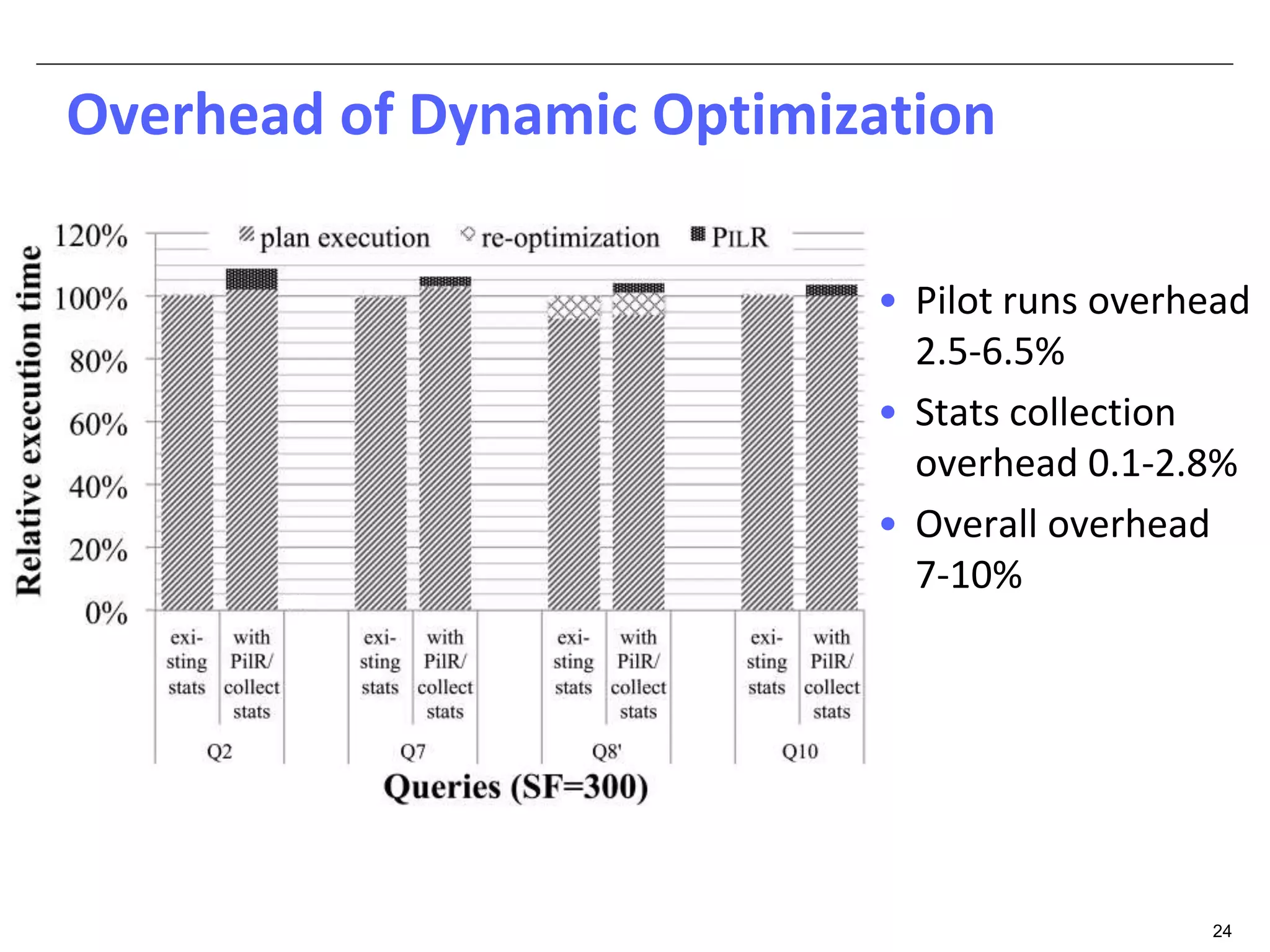
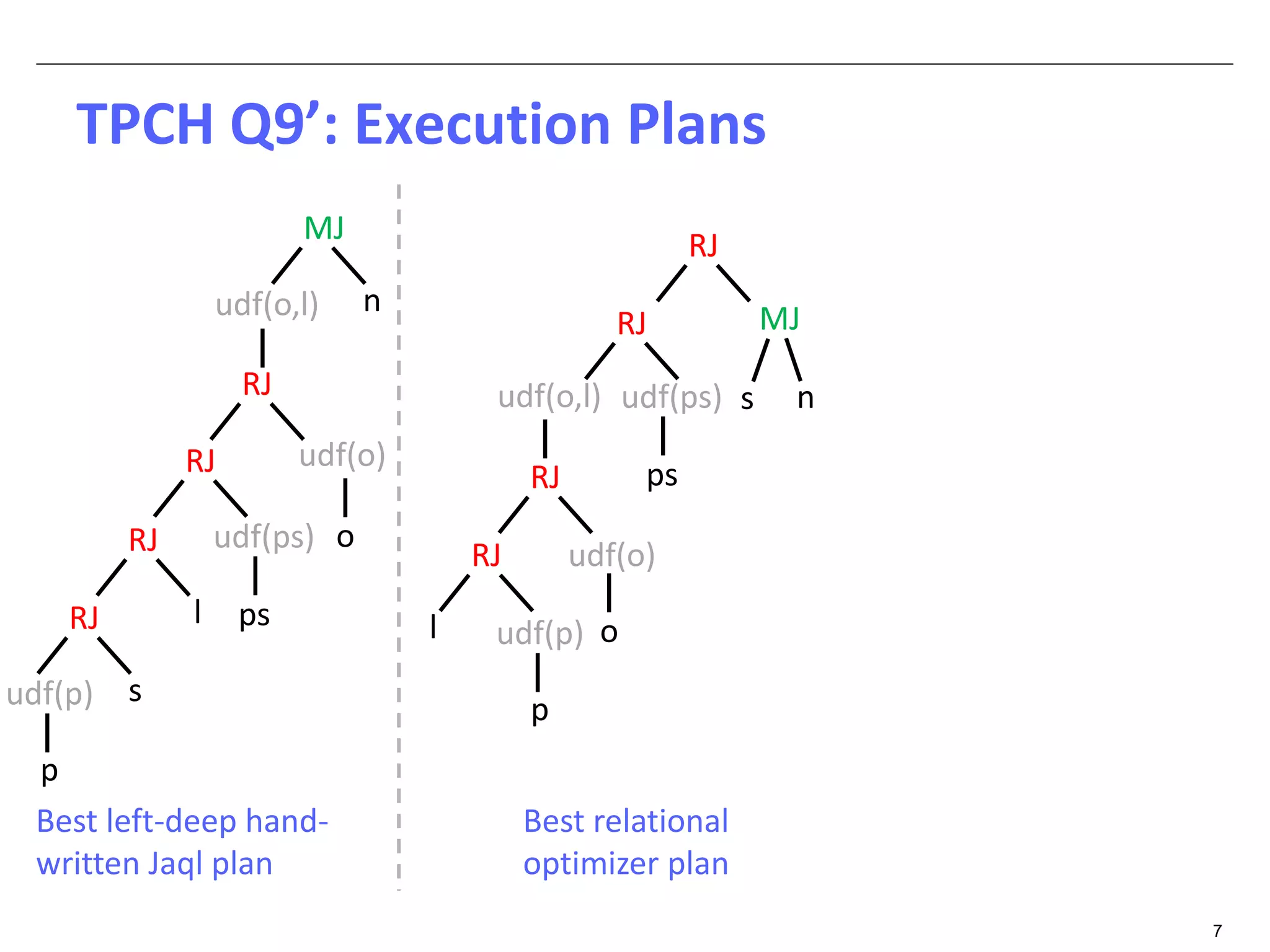
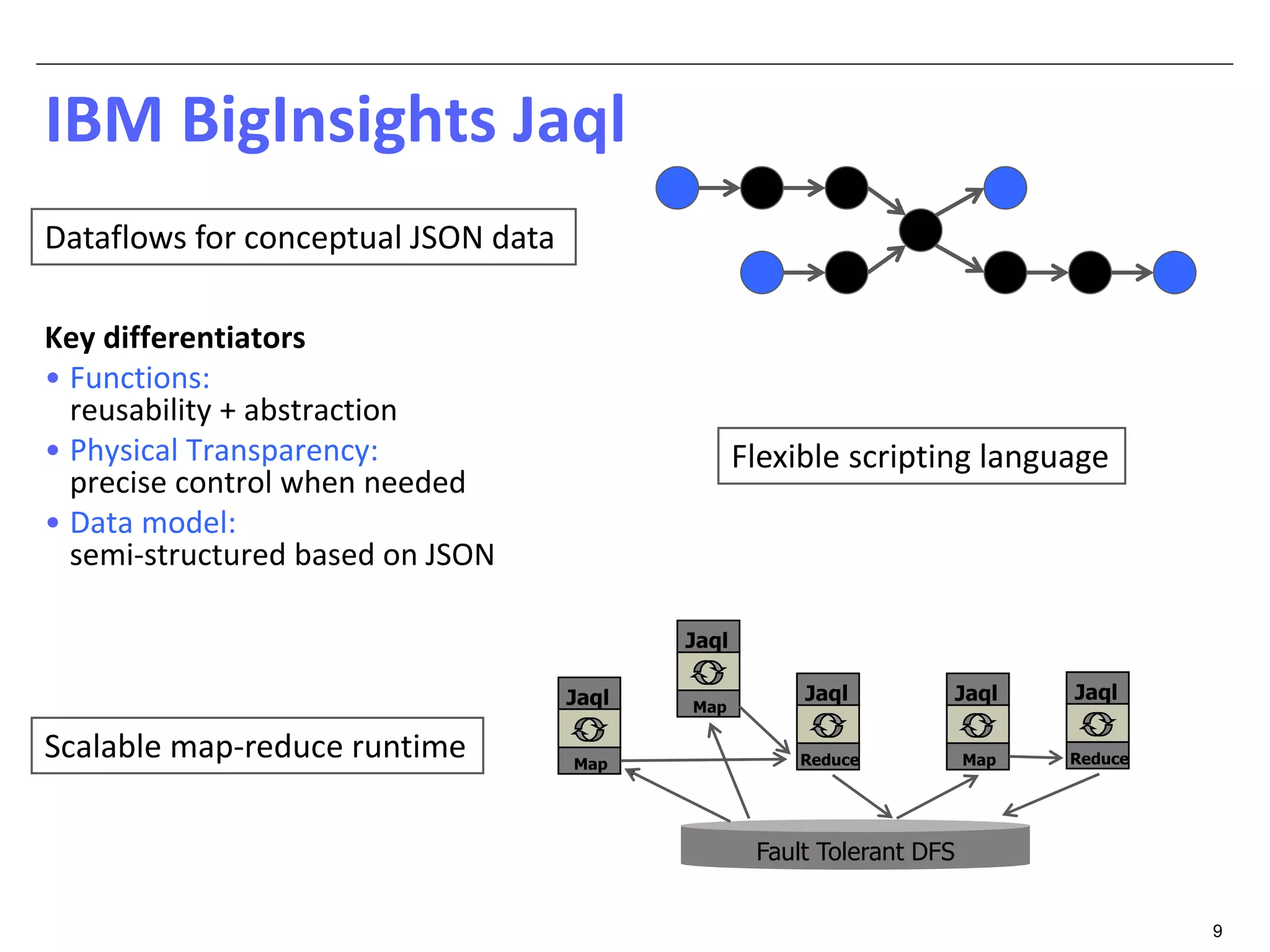
The document discusses dynamic optimization techniques for query processing over large-scale data platforms, primarily focusing on challenges such as exponential error propagation and the need for efficient management of big data. It outlines the use of pilot runs for accurate statistics collection and the adaptation of execution plans to improve performance, demonstrating significant speedup in query execution times. The proposed methods aim to enhance existing static optimization techniques, achieving performance gains of up to 4x, particularly in systems like Hive.
![Dynamically Optimizing Queries over
Large Scale Data Platforms
[Work done at IBM Almaden Research Center]
Konstantinos Karanasos♯, Andrey Balmin§, Marcel Kutsch♣,
Fatma Özcan*, Vuk Ercegovac◊, Chunyang Xia♦, Jesse Jackson♦
♯Microsoft *IBM Research §Platfora ♣Apple ◊Google ♦IBM
Inria Saclay
November 26, 2014](https://image.slidesharecdn.com/2014-11-26karanasosdynoinria-141127061442-conversion-gate01/75/Dynamically-Optimizing-Queries-over-Large-Scale-Data-Platforms-1-2048.jpg)





![10
Jaql Script: Example
read transform group by write
Query Data
read(hdfs("reviews"))
-> transform { pid: $.placeid, rev: sentAn($.review) }
-> group by p = ($.pid) as r into { pid: p, revs: r.rev }
-> write(hdfs("group-reviews"))
[
{ pid: 12, revs: [ 3*, 4*, … ] },
{ pid: 19, revs: [ 2*, 1*, … ] }
]
Group user reviews by place](https://image.slidesharecdn.com/2014-11-26karanasosdynoinria-141127061442-conversion-gate01/75/Dynamically-Optimizing-Queries-over-Large-Scale-Data-Platforms-10-2048.jpg)
![11
Jaql to MapReduce
mapReduce(
input: { type: hdfs, location: "reviews" },
output: { type: hdfs, location: "group-reviews" },
map: fn($mapIn) (
$mapIn -> transform { pid: $.placeid, rev: sentAn($.review) }
-> transform [ $.placeid, $.rev ] ),
reduce: fn($p, $r) ( [ pid: $p, revs: $r ] ) )
• Functions as parameters
• Rewritten script is valid
Jaql!
read(hdfs("reviews"))
-> transform { pid: $.placeid, rev: sentAn($.review) }
-> group by p = ($.pid) as r into { pid: p, revs: r.rev }
-> write(hdfs("group-reviews"))
Rewrite Engine](https://image.slidesharecdn.com/2014-11-26karanasosdynoinria-141127061442-conversion-gate01/75/Dynamically-Optimizing-Queries-over-Large-Scale-Data-Platforms-11-2048.jpg)