Download as PDF, PPTX

















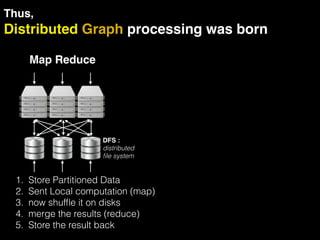
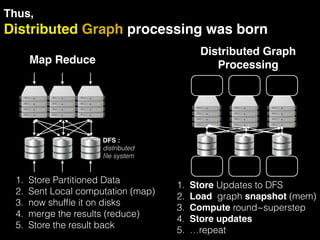
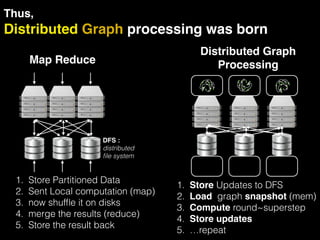
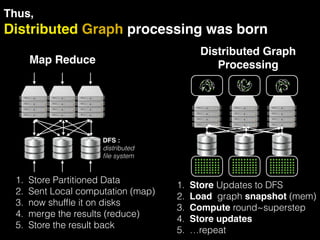
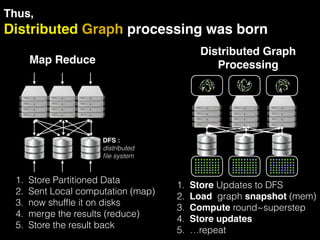
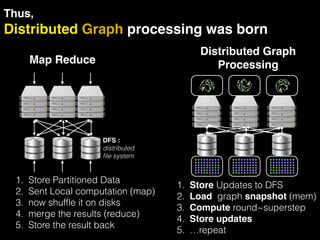
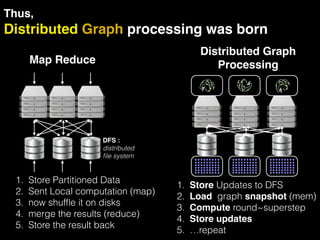


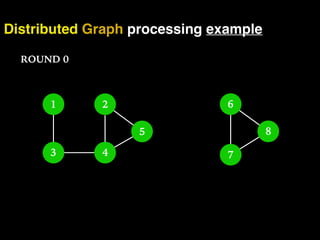
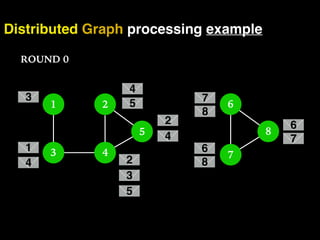
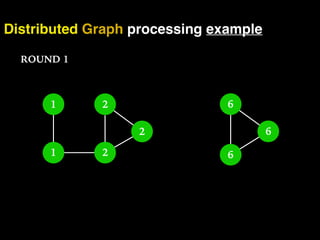
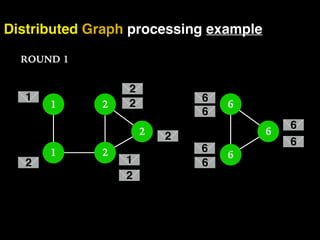
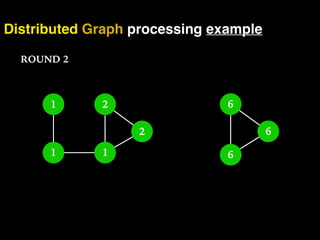
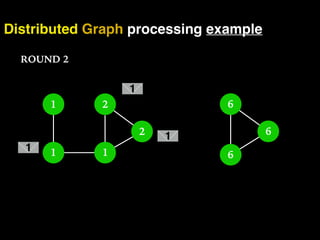
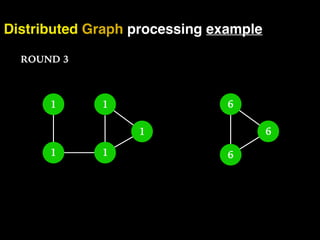
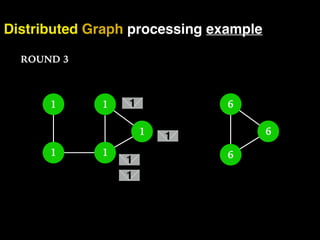
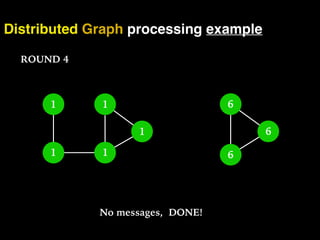




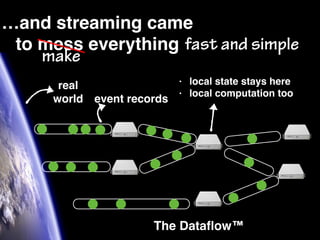






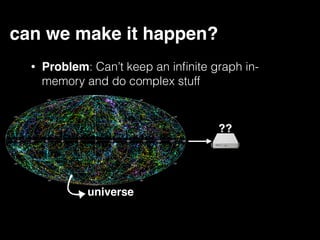

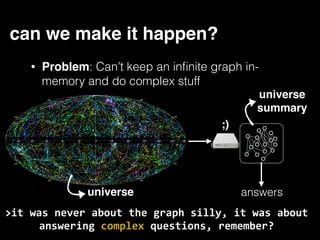
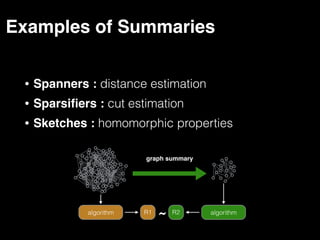


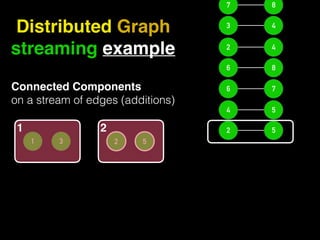
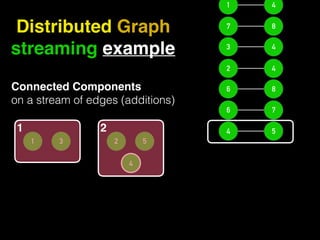
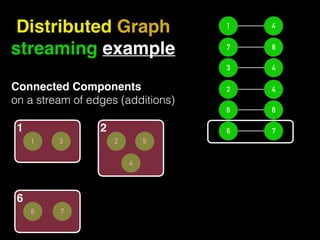
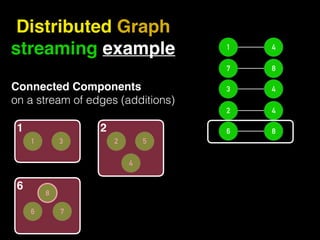
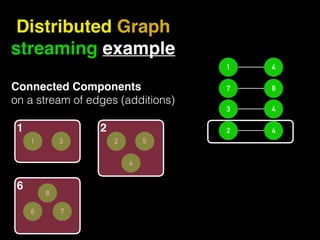
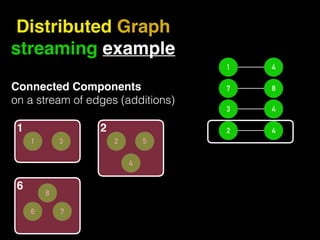
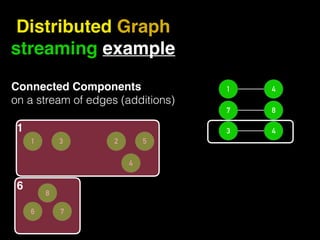
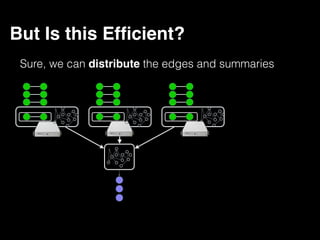
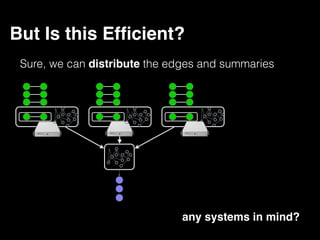

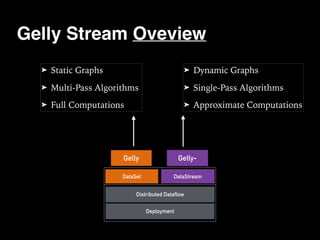




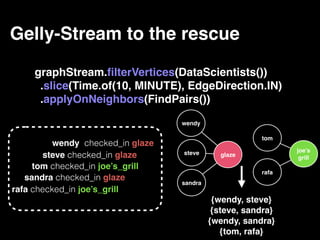



The document discusses the need for large-scale, complex, and fast data analysis to answer significant questions quickly, particularly in the context of graph stream processing. It details the evolution of distributed graph processing, the challenges of real-time analytics, and offers insights into solutions like Apache Flink and Gelly Stream. The emphasis is on addressing complex problems through efficient data analysis techniques and frameworks to support real-time decision-making.

























































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



