Downloaded 13 times








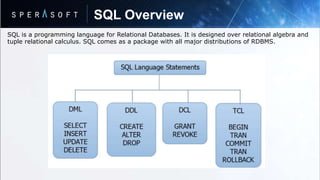
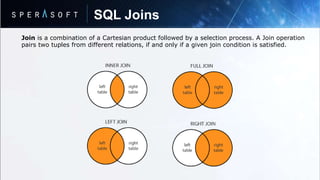
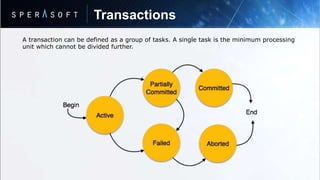

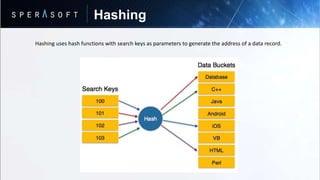


The document discusses key concepts in relational database models including: - Data is stored in tables called relations with rows and columns where rows represent records and columns represent attributes. - Relations can be normalized to eliminate redundant data and optimize storage. - Database normalization involves organizing data into tables through a multi-step process to remove anomalies. - SQL is a programming language used to interact with relational databases through operations like joins, transactions, and indexing/hashing techniques.
























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















