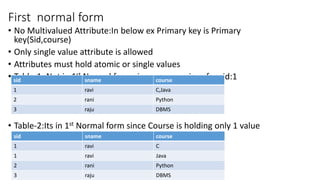
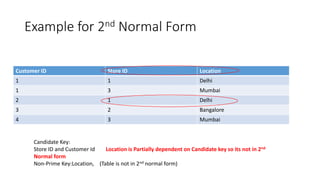
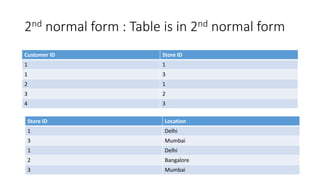
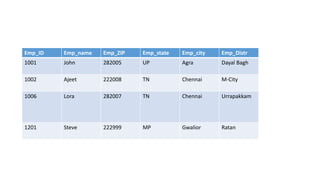
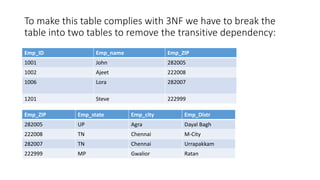
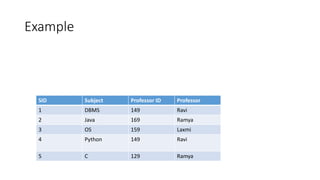
Normal forms are used to avoid data redundancy and anomalies during data modification. The 1st normal form requires attributes to hold atomic values. The 2nd normal form requires non-key attributes to depend on the whole candidate key. The 3rd normal form prohibits non-key attributes from depending on other non-key attributes. Normalization aims to decompose relations into smaller, more manageable tables while preserving dependencies and attributes to avoid redundancy and update anomalies.