Downloaded 14 times






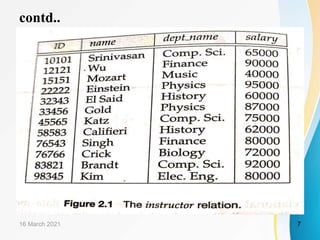








































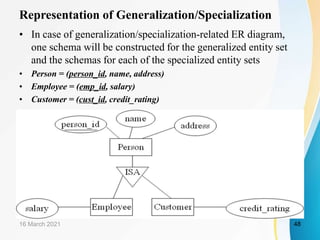



This document is a learning resource on database management systems, specifically focusing on the relational data model. It covers key concepts such as relational keys, constraints, and the characteristics of relational databases, along with an introduction to related database languages and the transformation of entity-relationship models into relational schemas. Ultimately, the chapter aims to provide students with a comprehensive understanding of essential relational model principles and practices in database management.






























































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)









