Download as PDF, PPTX















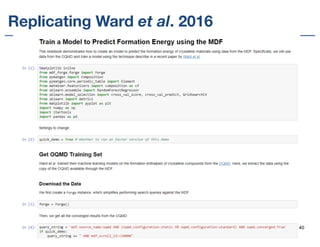
![Piping DFT data from MDF to Citrine
{ "category": "system.chemical",
"chemicalFormula": "MgO2",
"properties": {
"units": "eV", "name": "Band gap",
"scalars": [ { "value": 7.8 } ] } }
2. Bot requests open DFT data periodically
3. Bot accesses data, runs DFT parser to refine data
4. Push metadata to Citrine
1. User publishes DFT dataset
5. Ingest DFT data quality report
…
Our datasets are discoverable through many tools
19](https://image.slidesharecdn.com/20170815-uiuc-computational-materials-workshop-170822220336/85/The-Materials-Data-Facility-A-Distributed-Model-for-the-Materials-Data-Community-19-320.jpg)



















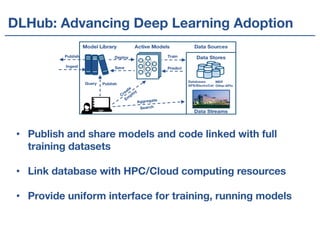










The Materials Data Facility (MDF) is a distributed model for the materials data community that aims to make materials data more shareable, open, accessible, computable, and valuable. The MDF indexes over 100 terabytes of materials data from various repositories and facilities. It provides services for data discovery, publication with DOIs, and integrates data with computing resources. The goal is to simplify critical tasks in materials science like finding relevant data, training machine learning models across multiple datasets, and reproducing results.


![[DSC Europe 23] Spela Poklukar & Tea Brasanac - Retrieval Augmented Generation](https://cdn.slidesharecdn.com/ss_thumbnails/spelapoklukarteabrasanacprez-231129000106-d6582d1b-thumbnail.jpg?width=640&height=640&fit=bounds)
































































