Download to read offline





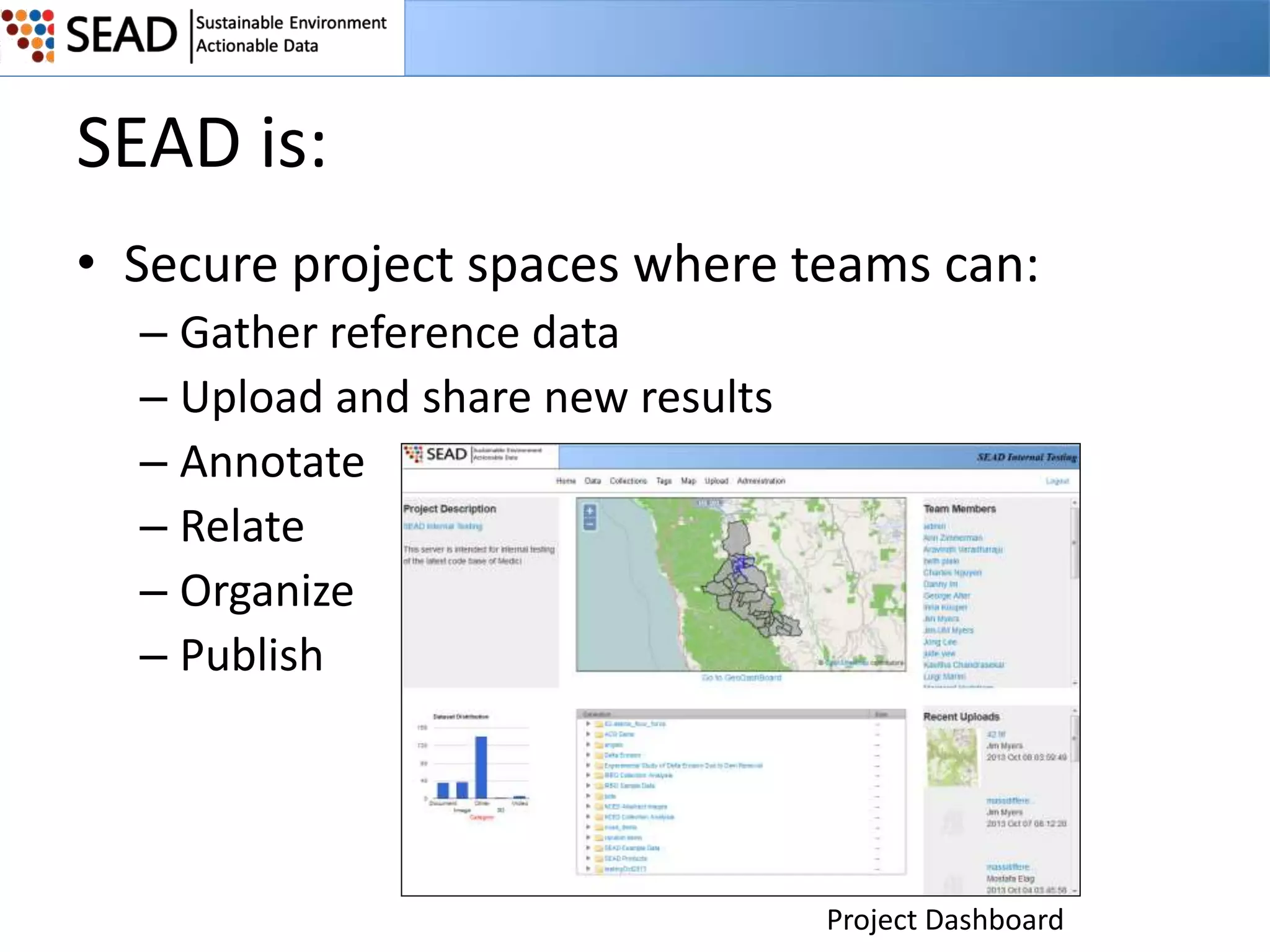
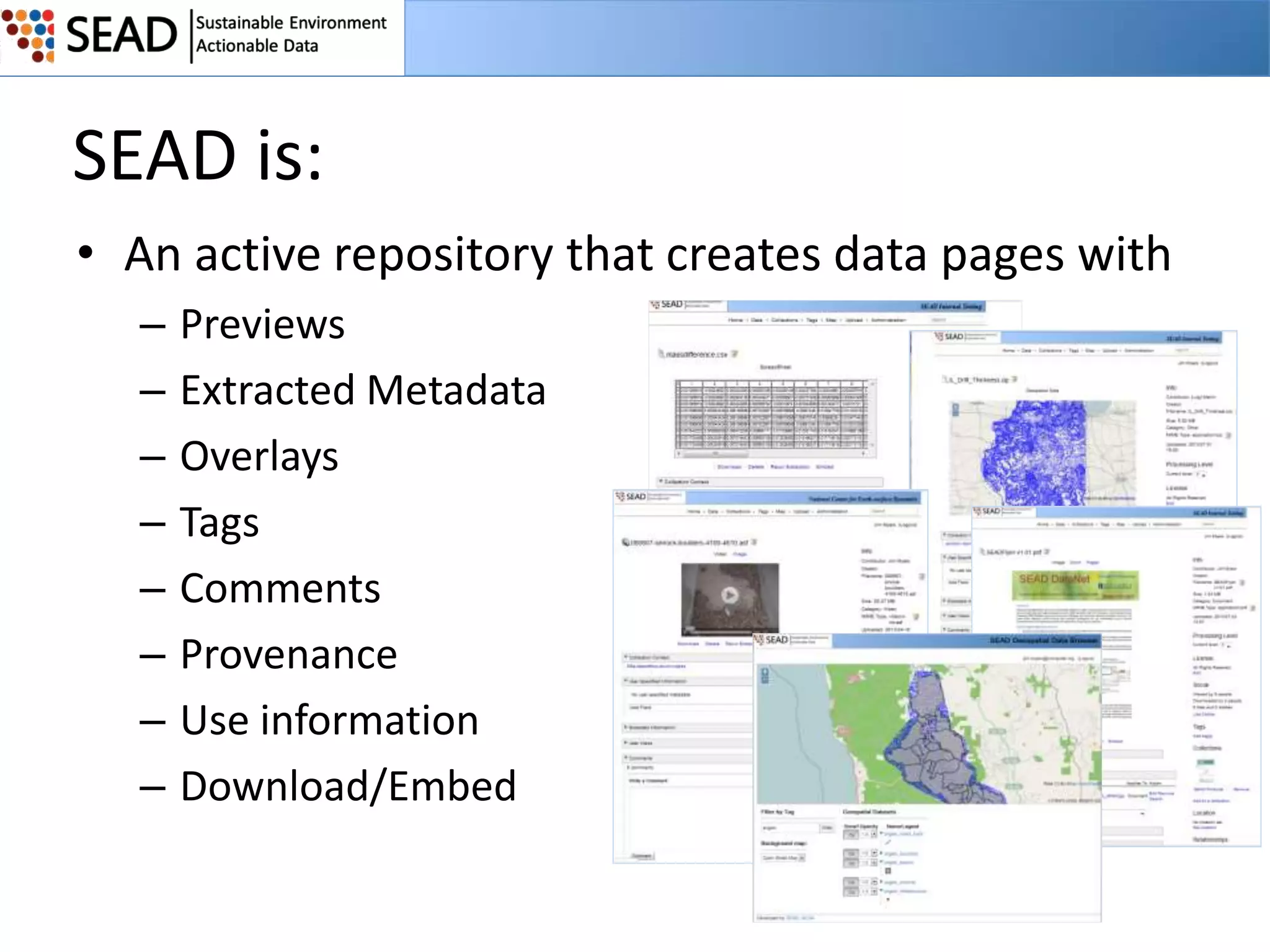
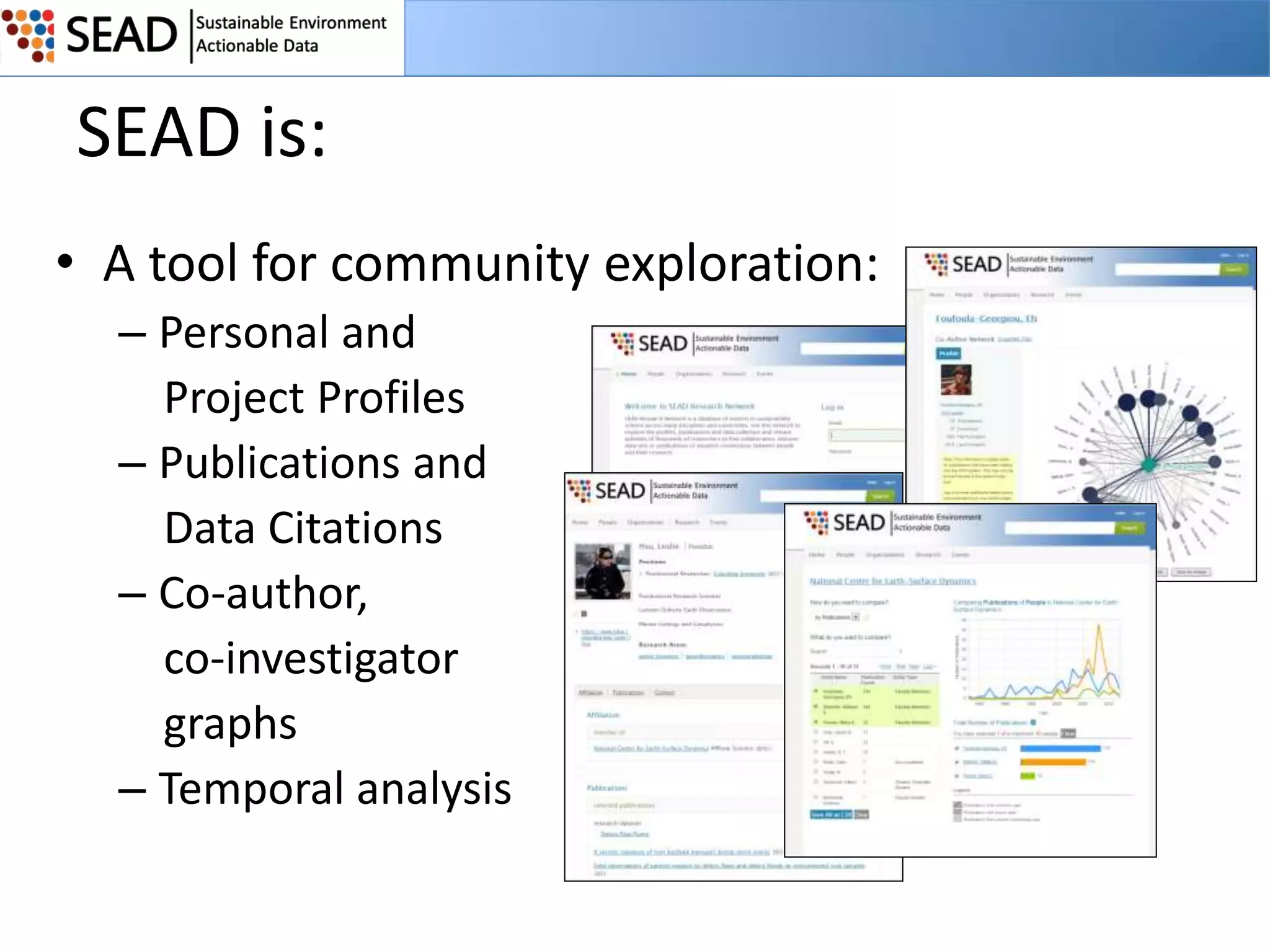
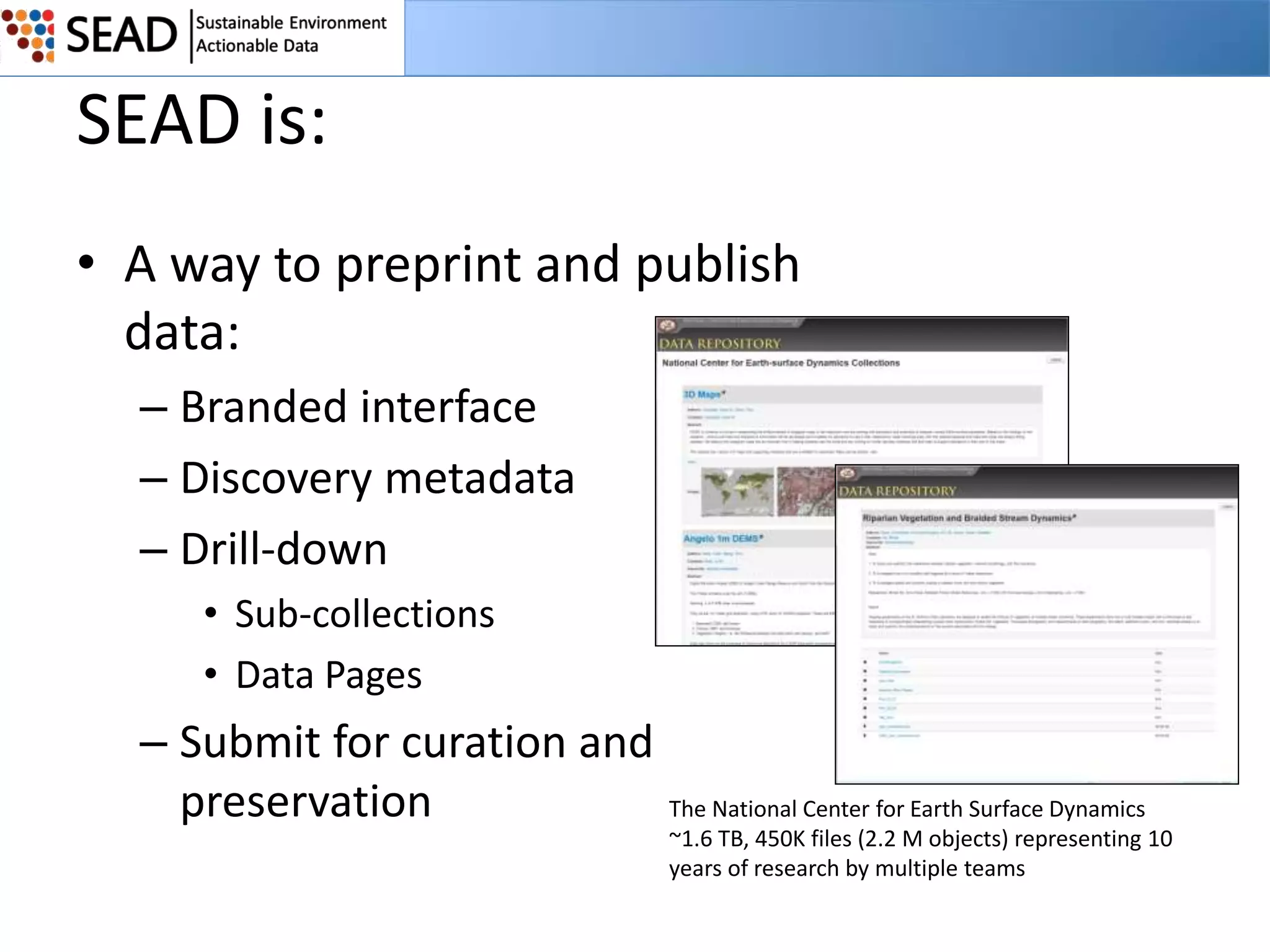

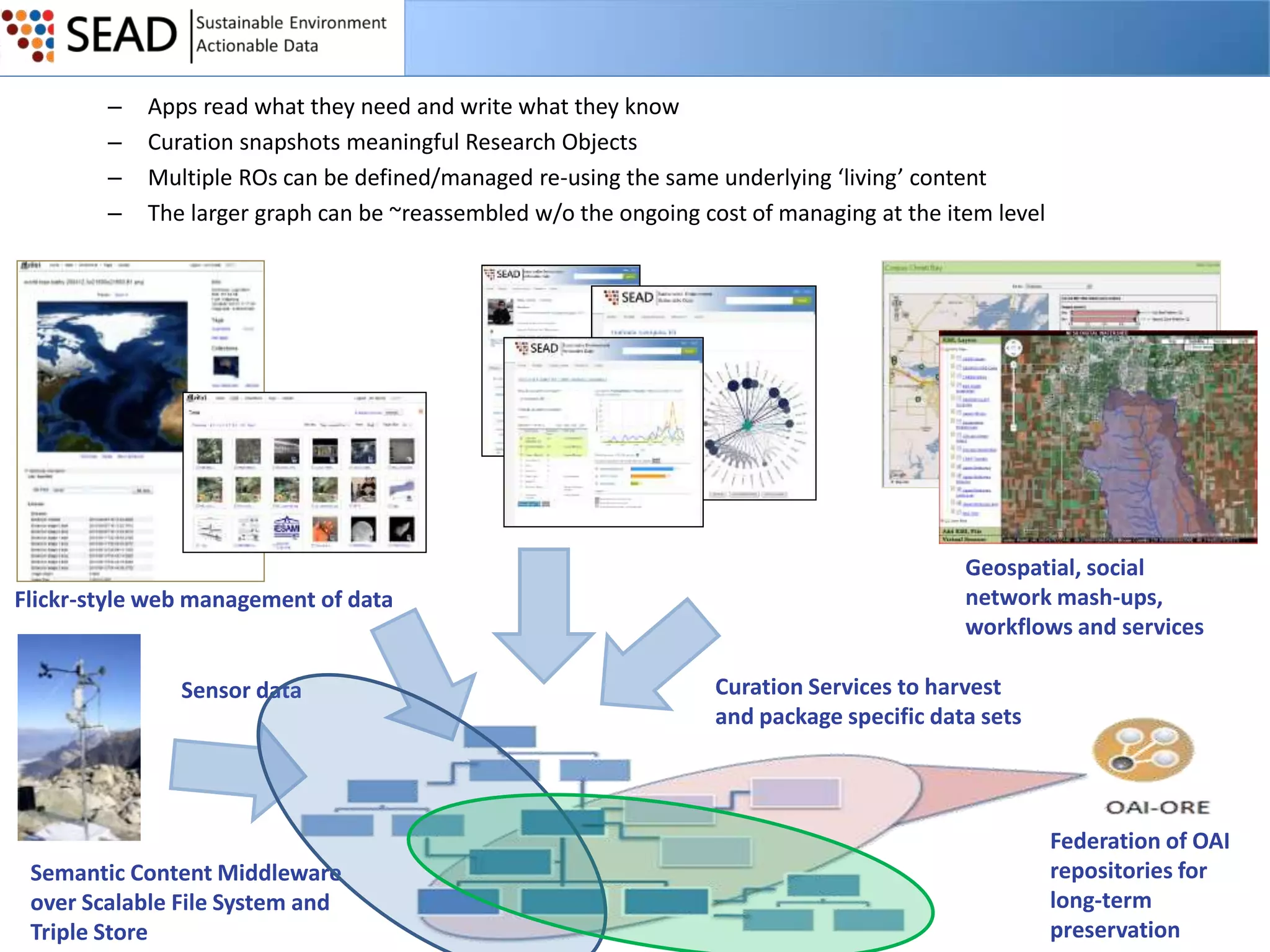






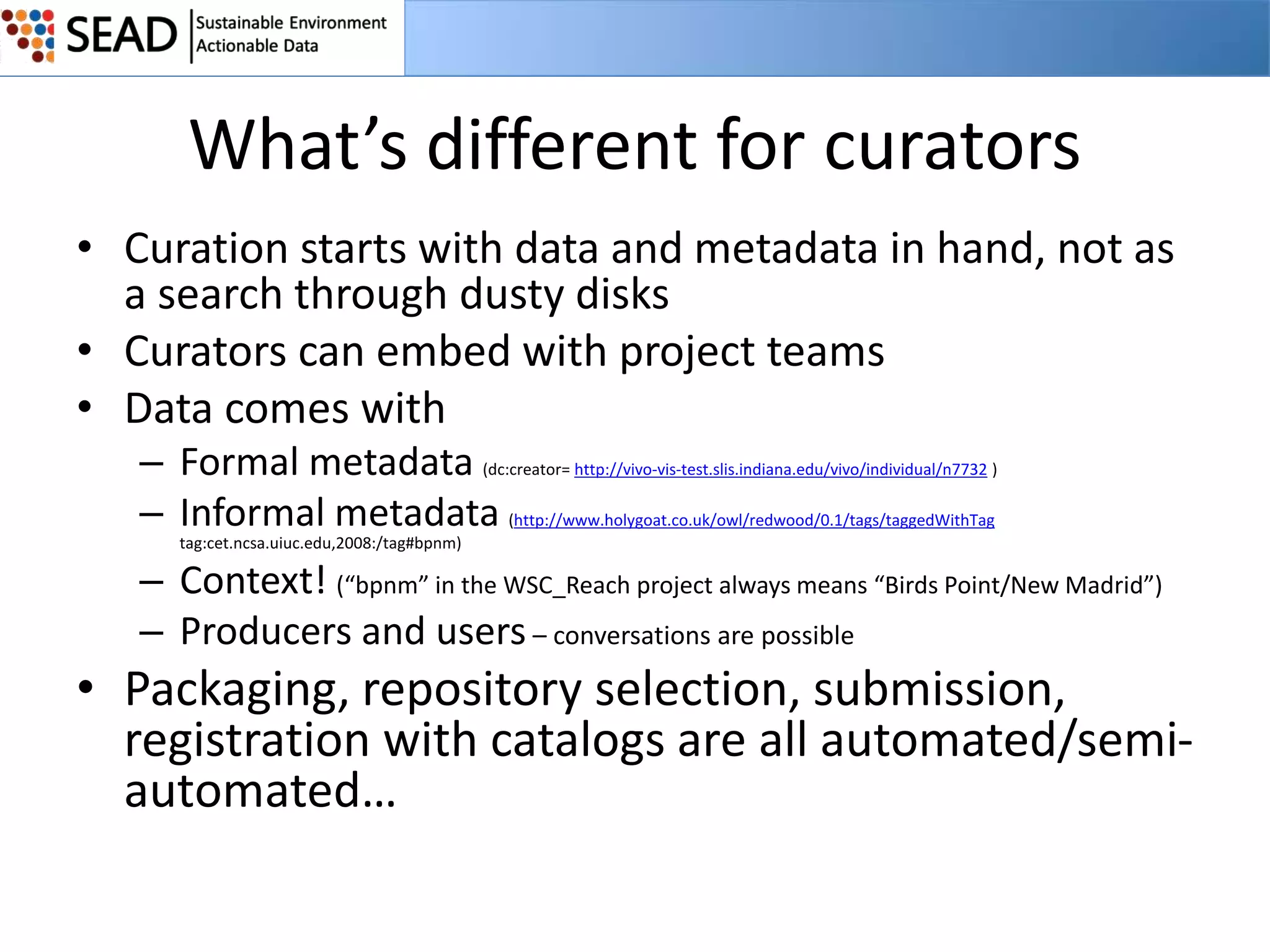






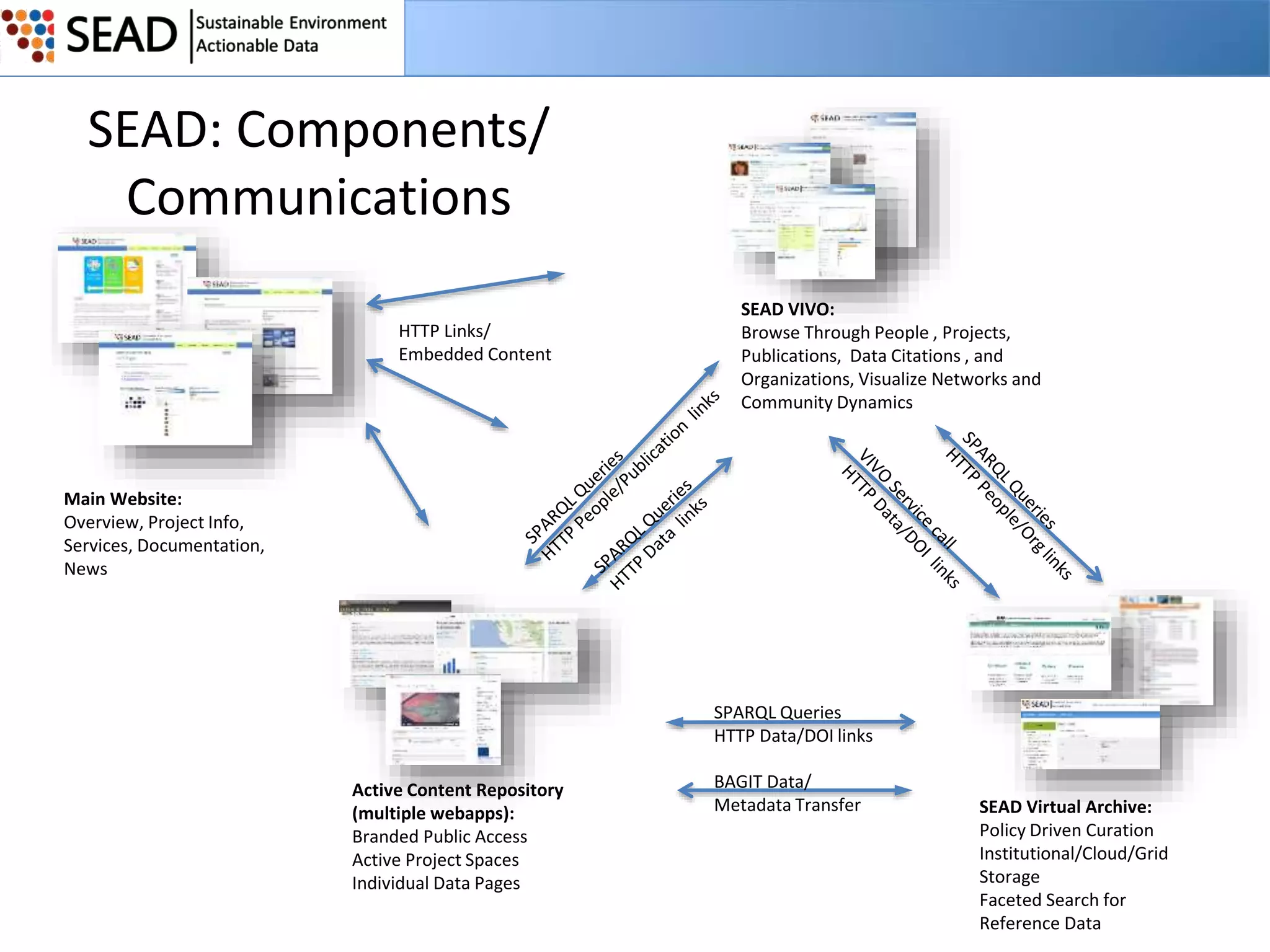

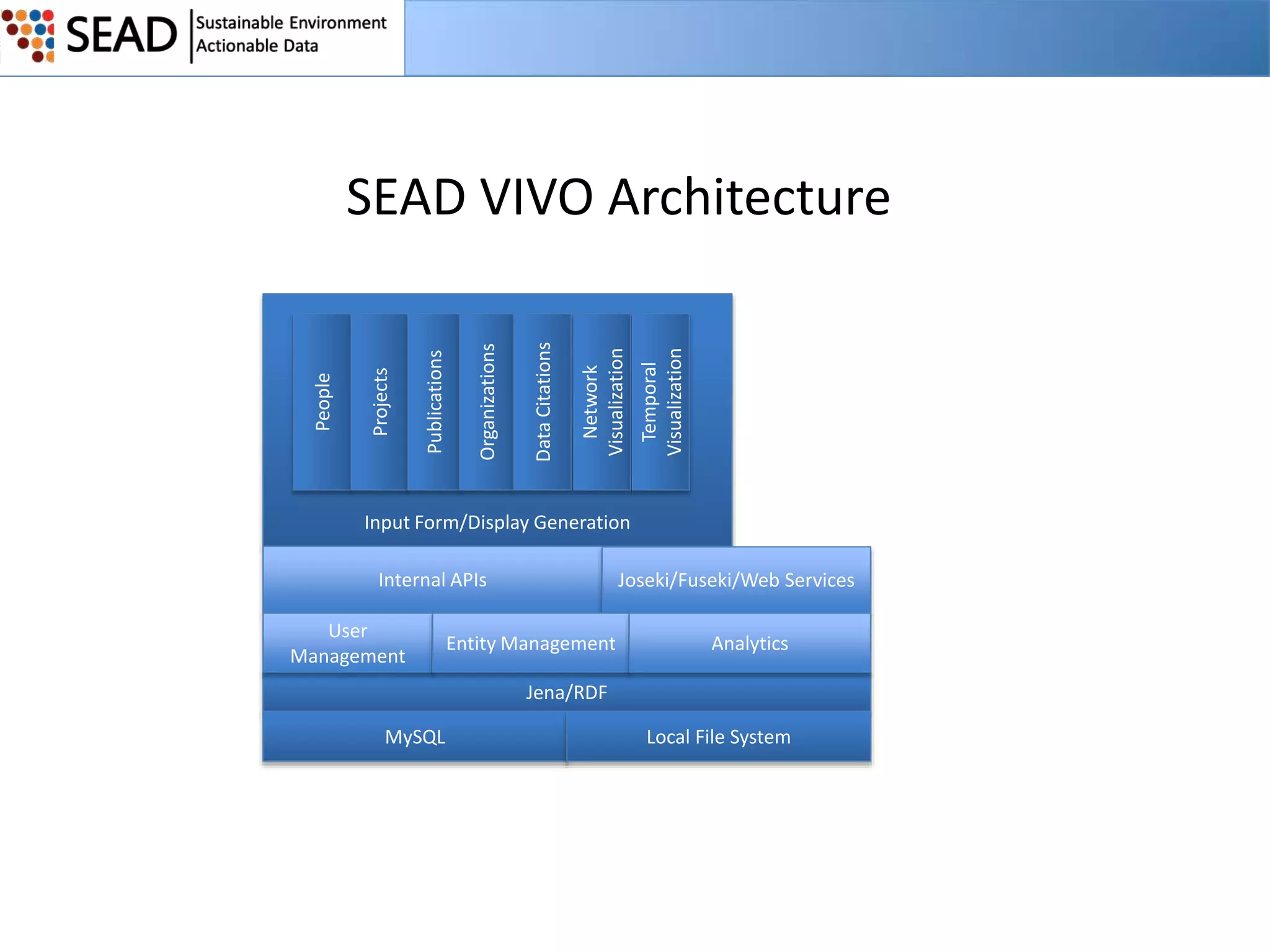
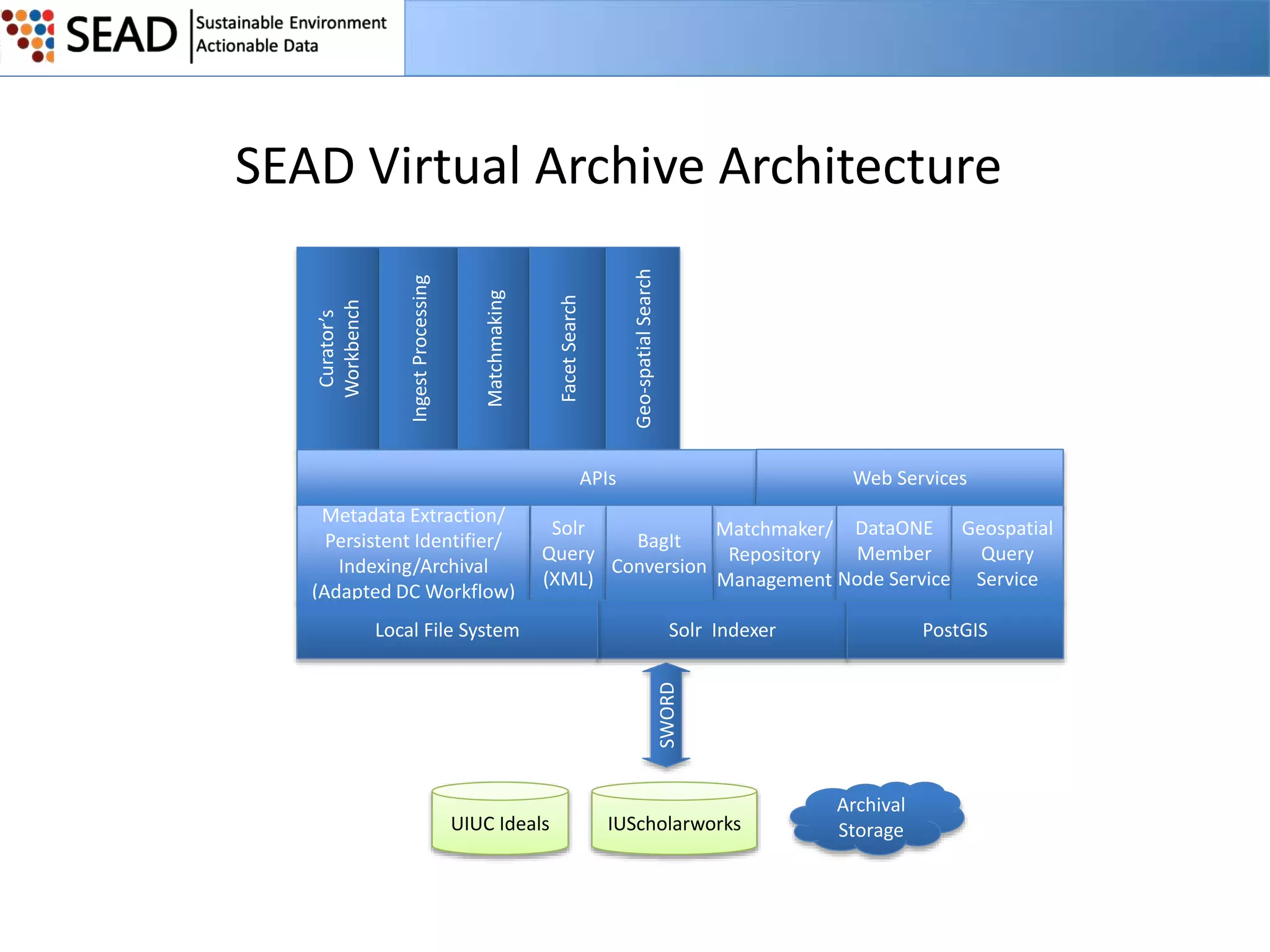
This document discusses the Sustainable Environment Actionable Data (SEAD) project, which aims to lower the costs and increase the value of data curation through a data lifecycle approach. SEAD provides lightweight data services to support sustainability research, including secure project workspaces, active and social curation tools, and integrated lifecycle support for data from ingest to long-term preservation. By leveraging technologies like Web 2.0 and standards, SEAD simplifies and automates curation processes using metadata captured from data producers and users. This allows curation activities to begin earlier in the data lifecycle and be distributed across researchers and curators.







































































