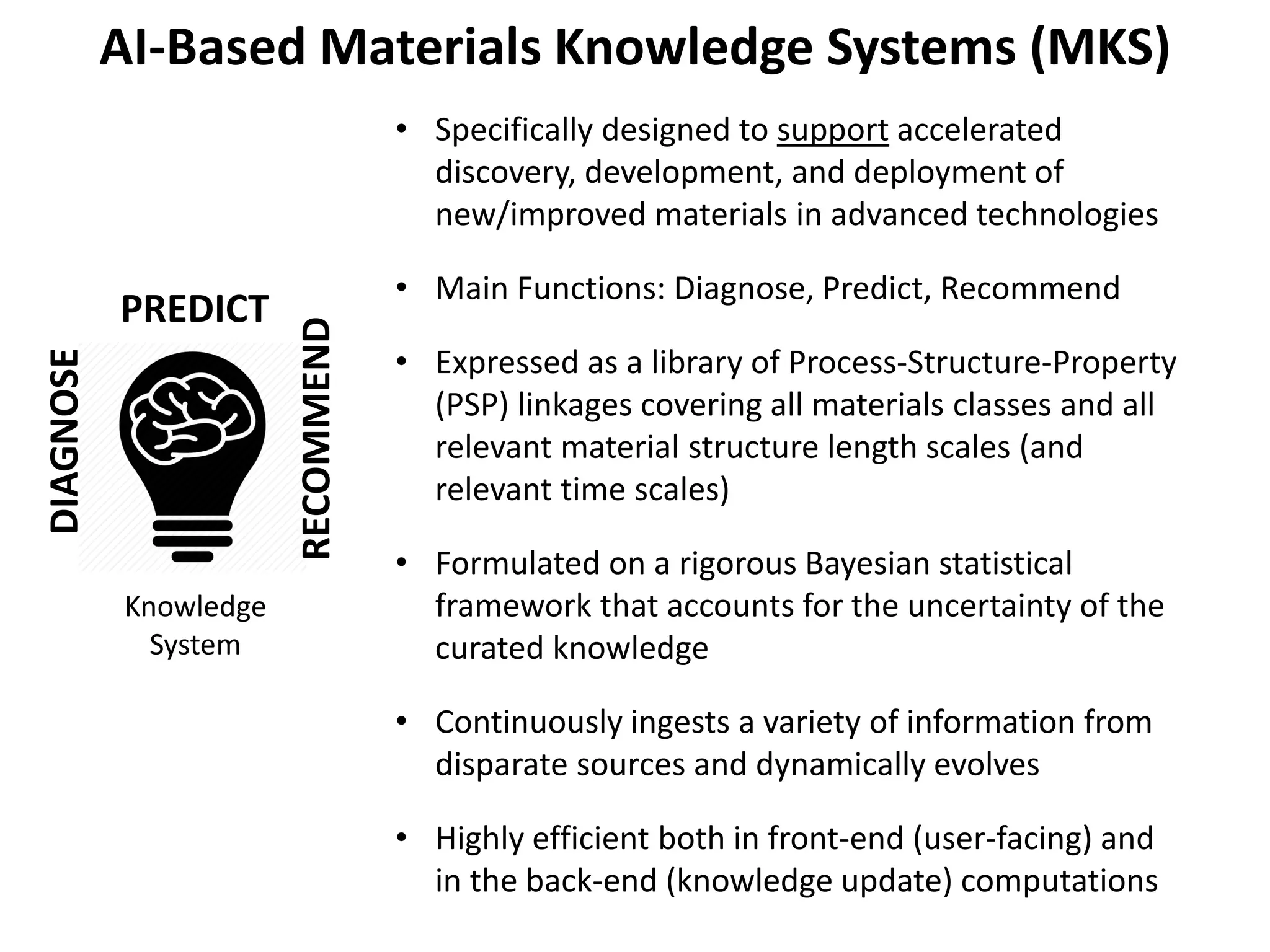
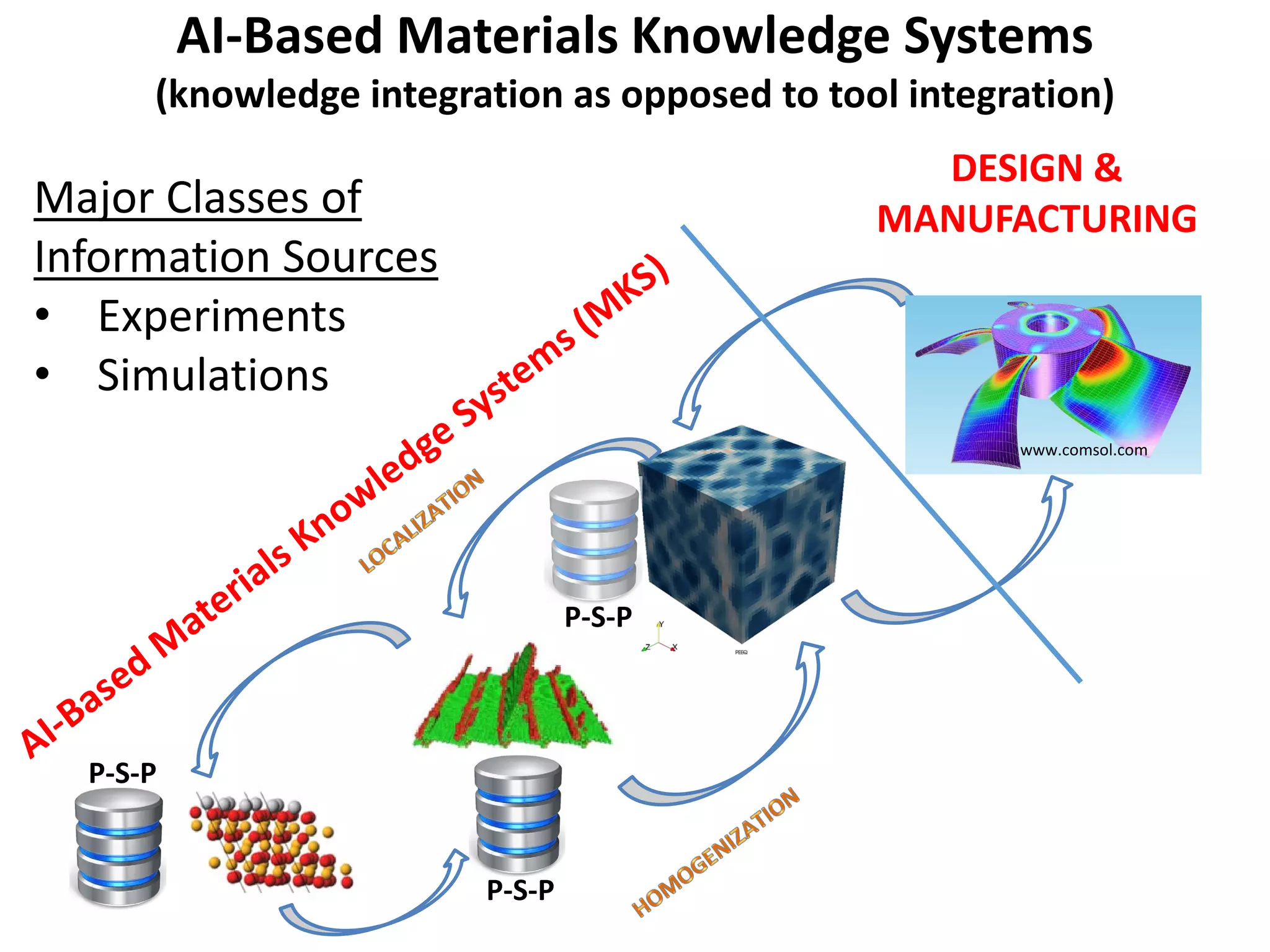
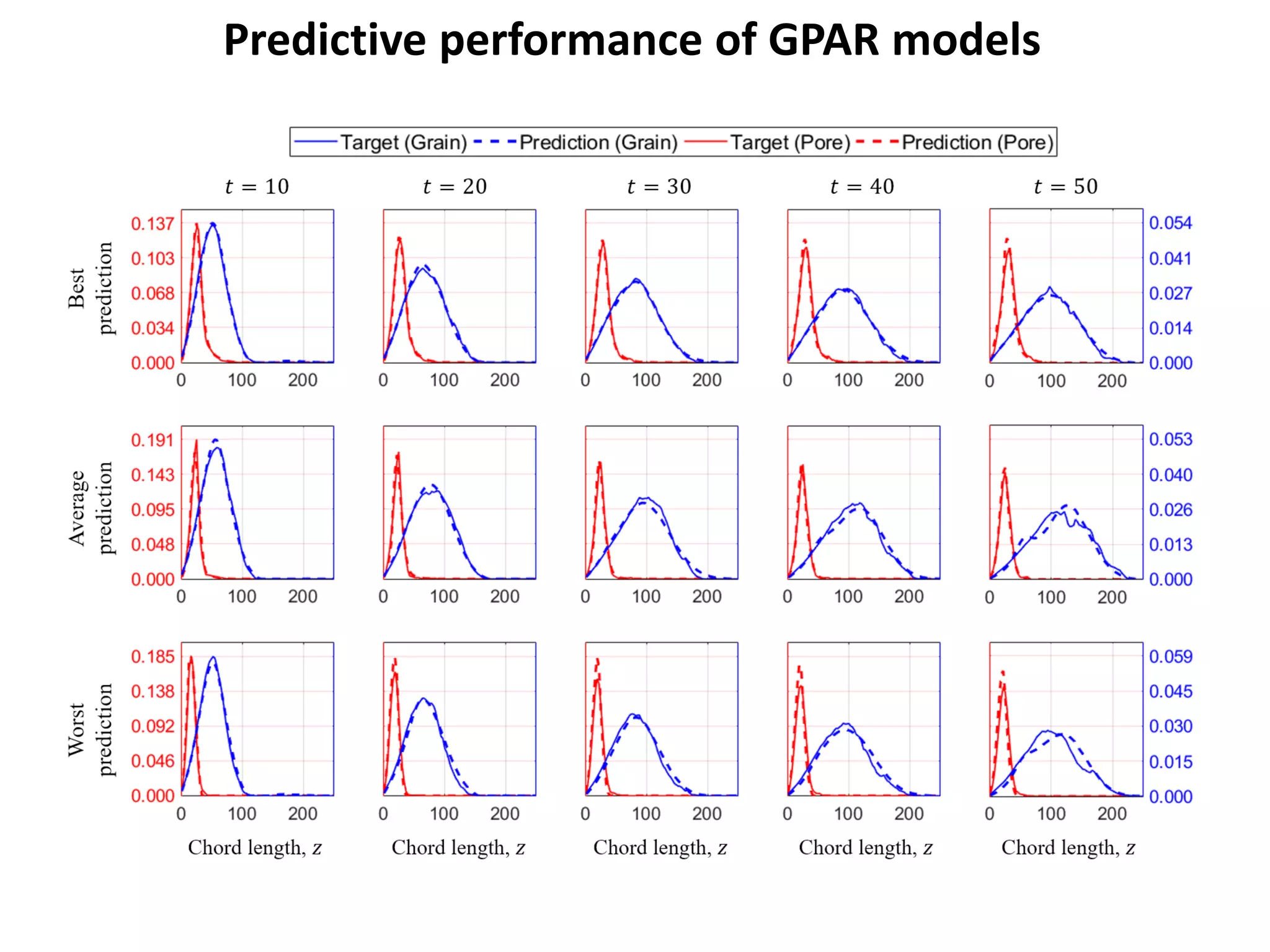
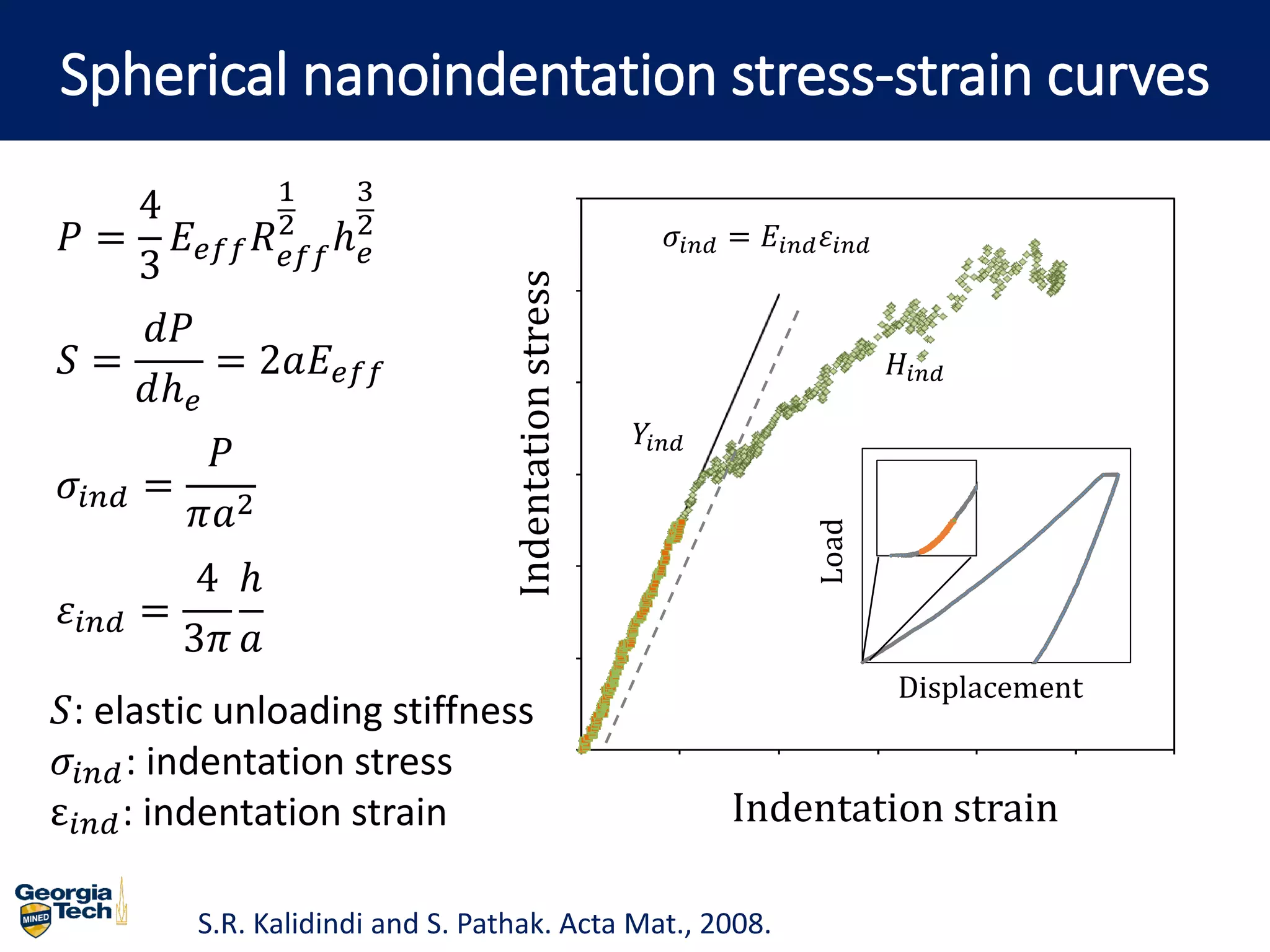
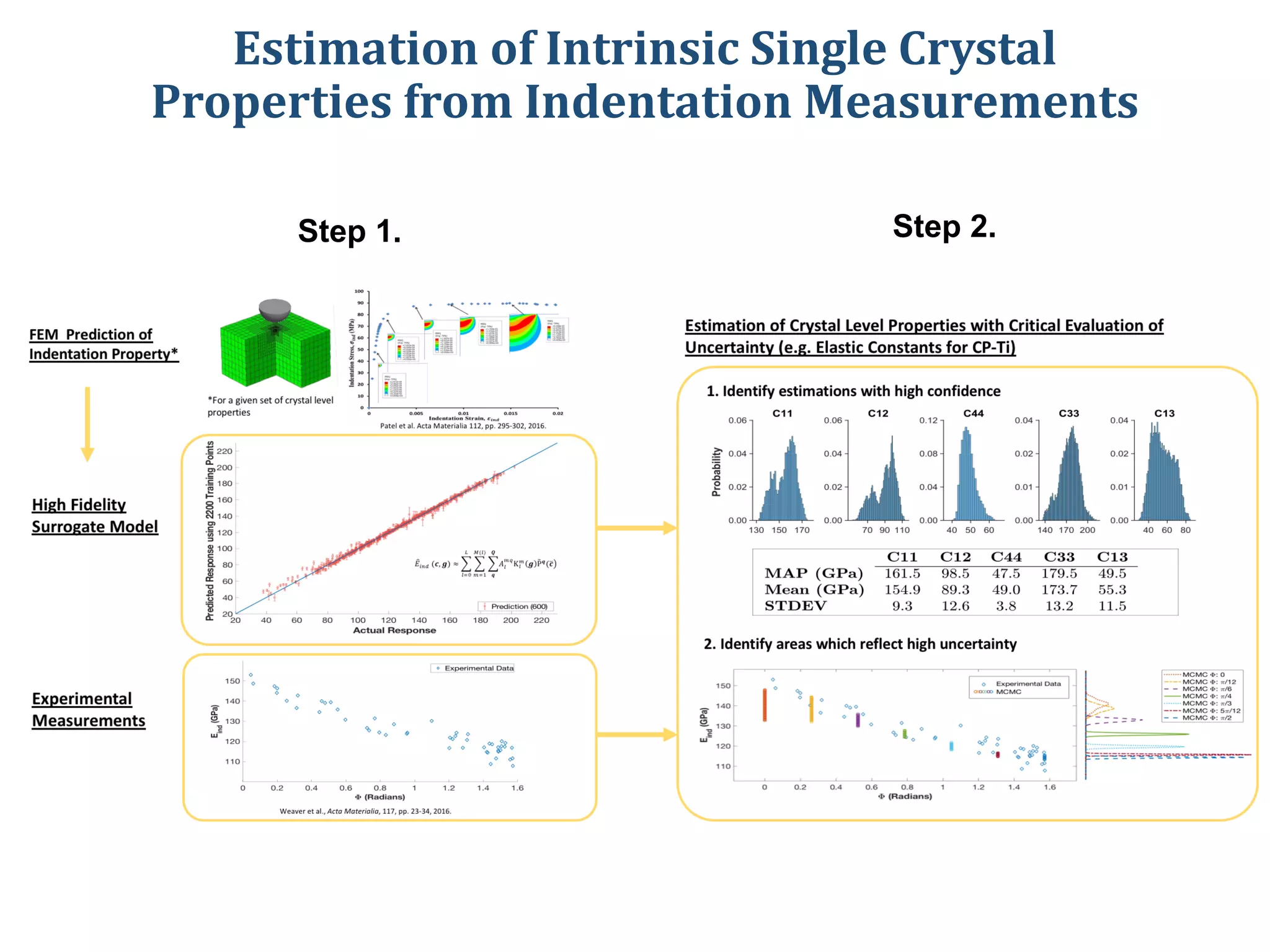
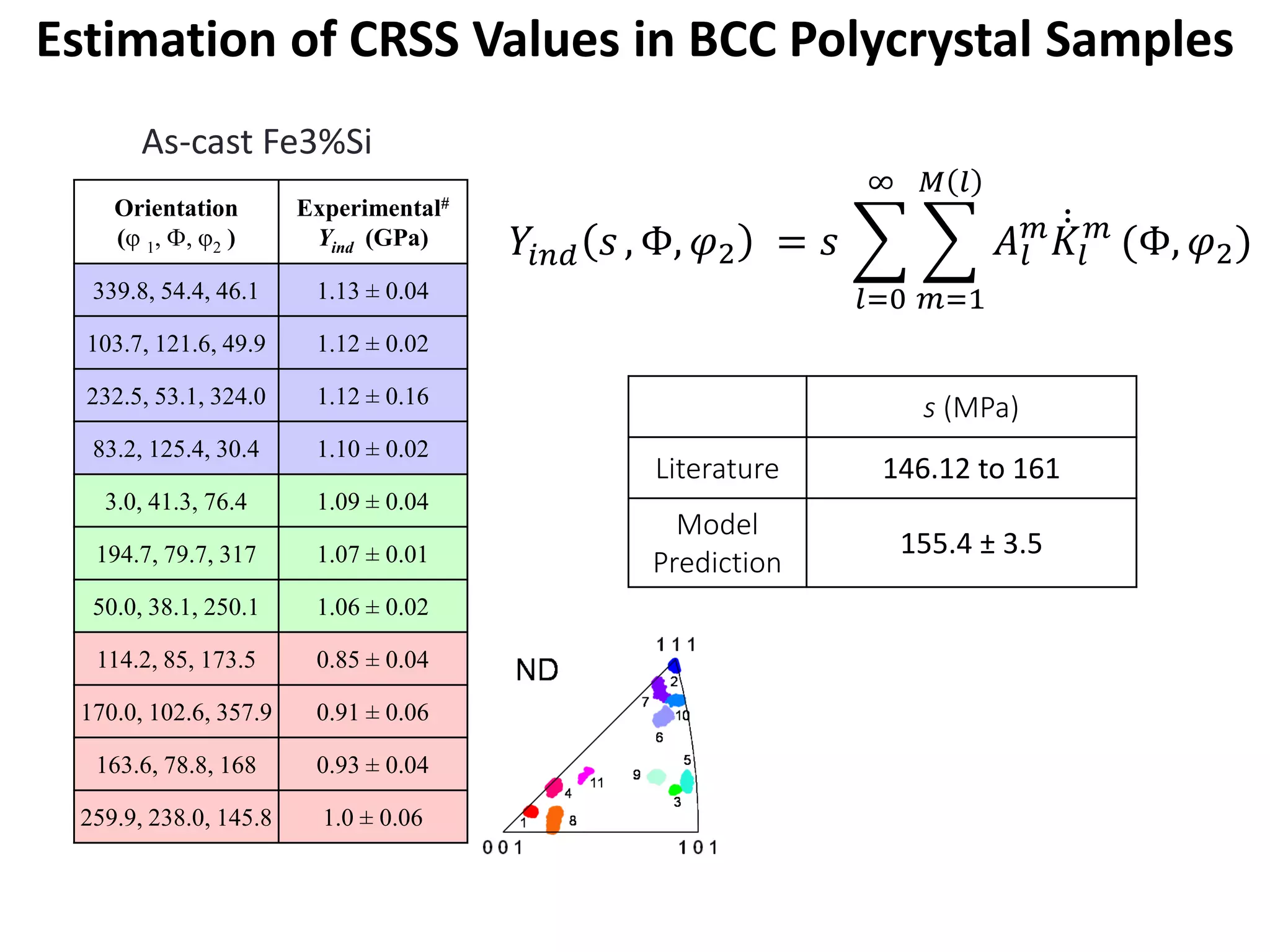
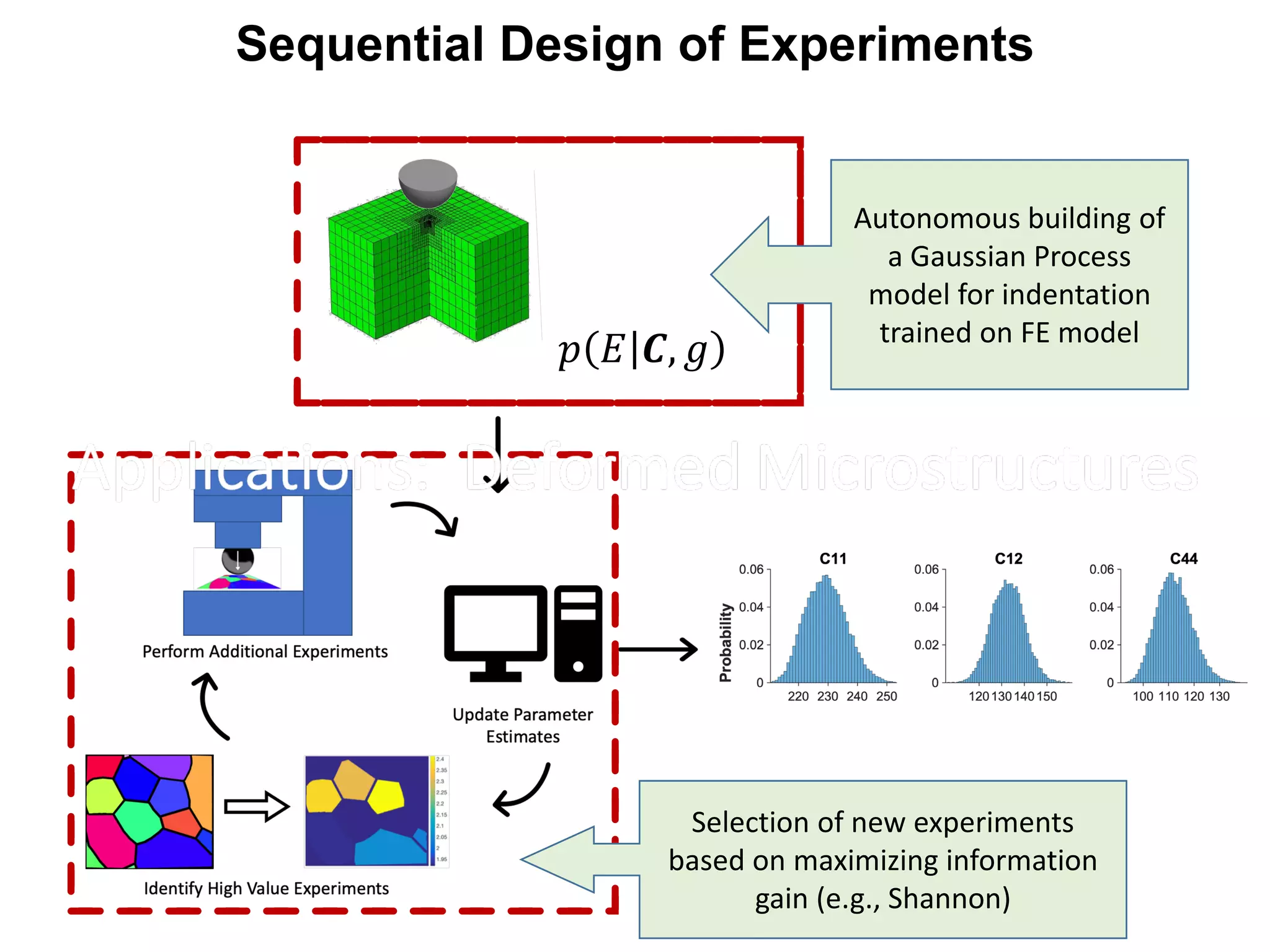
- The document describes a machine learning framework for developing artificial intelligence-based materials knowledge systems (MKS) to support accelerated materials discovery and development.
- The MKS would have main functions of diagnosing materials problems, predicting materials behaviors, and recommending materials selections or process adjustments.
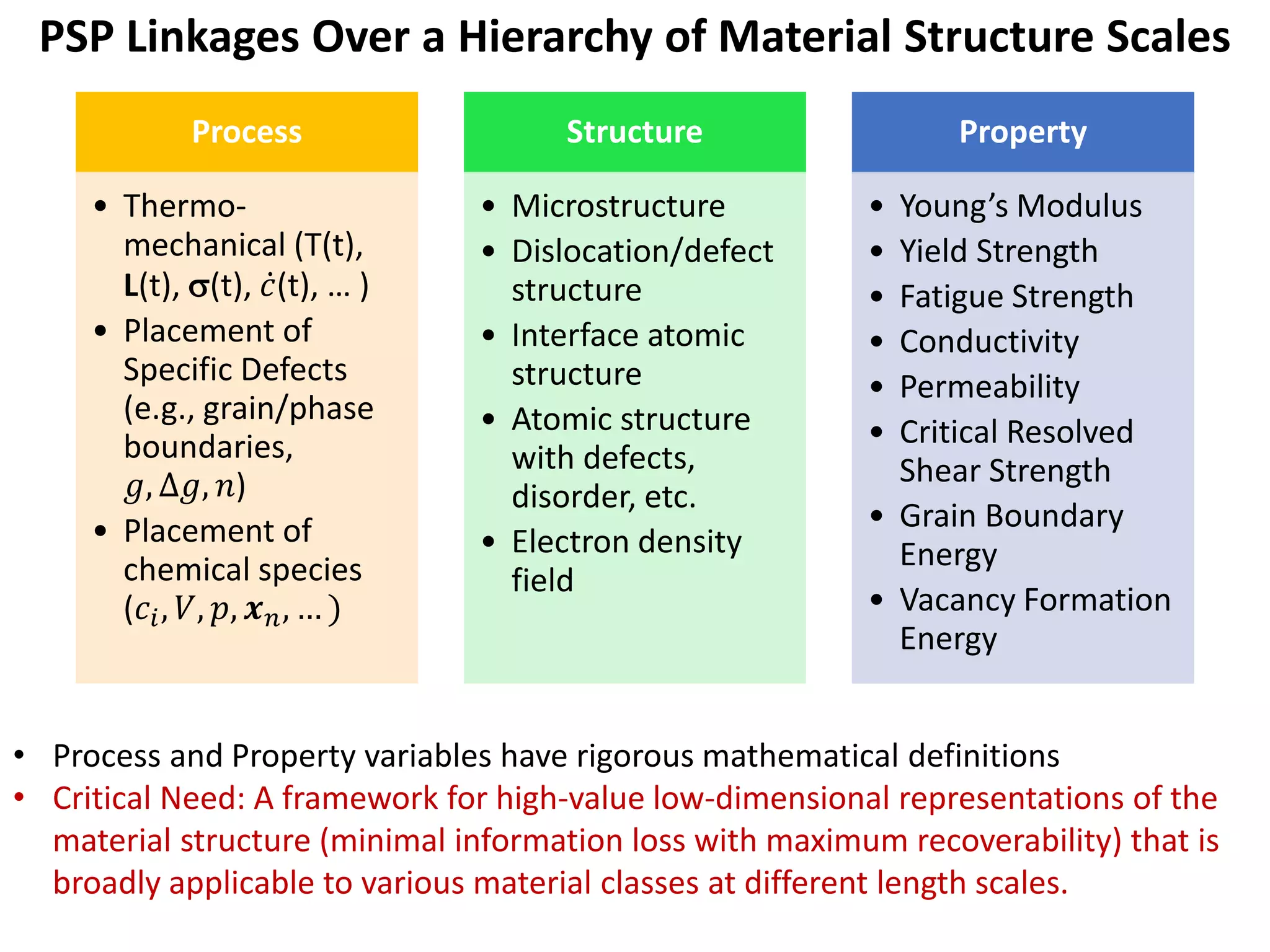
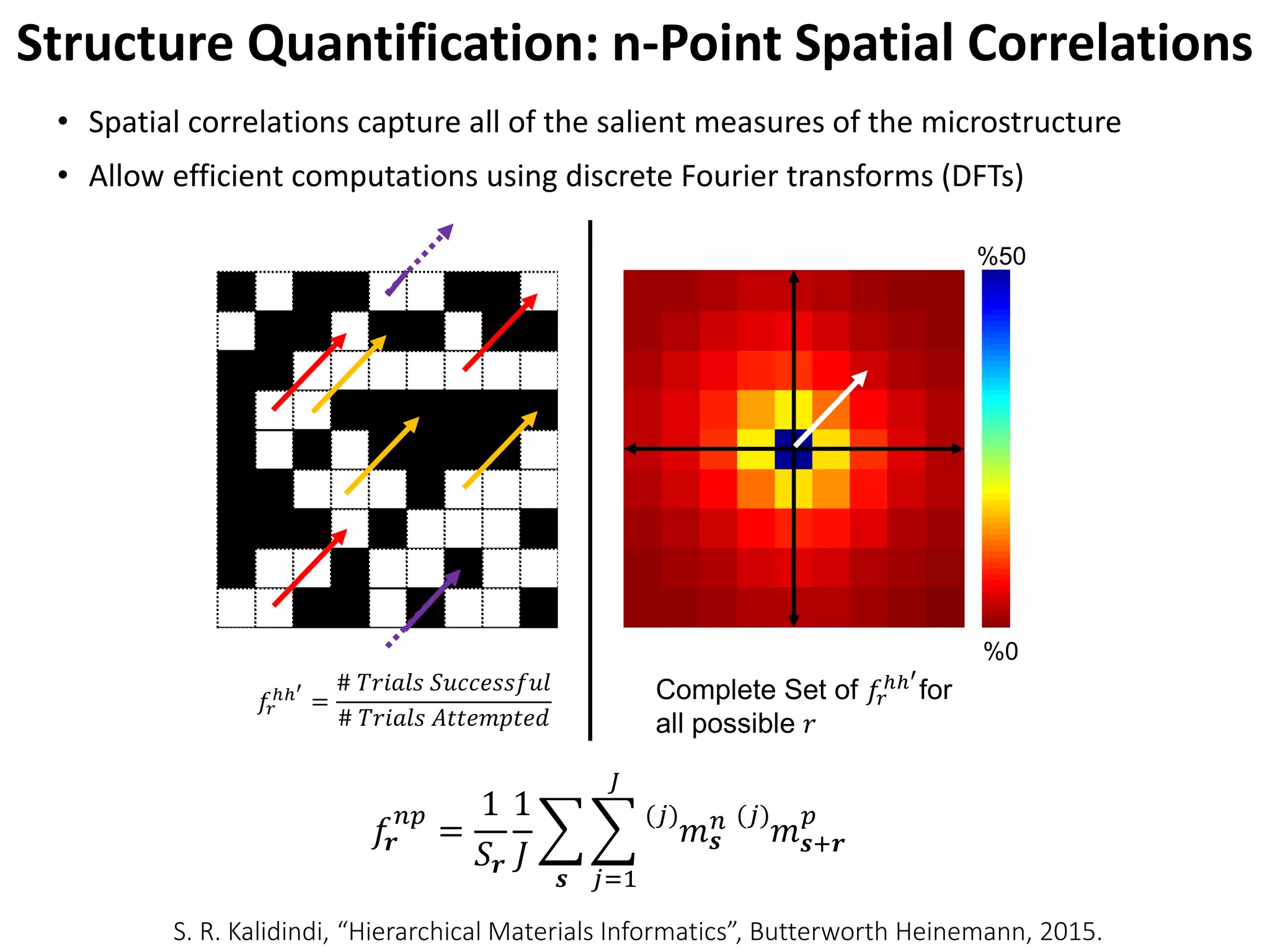
- It would utilize a Bayesian statistical approach to curate process-structure-property linkages for all materials classes and length scales, accounting for uncertainty in the knowledge, and allow continuous updates from new information sources.






![Applications to Rapid Screening of Process Space
0
100
200
300
400
500
600
700
200 300 400IndentationStrength[MPa]
Aging Temperature [°C]
High Throughput Sample
Individual Heat Treatments
0
100
200
300
400
500
600
700
AR 204 °C 274 °C 343 °C 413 °C
Strength[MPa]
Indentation Yield Strength
Tensile Yield Strength](https://image.slidesharecdn.com/surya-190826170657/75/A-Machine-Learning-Framework-for-Materials-Knowledge-Systems-25-2048.jpg)
![Orientation Dependence of
Indentation Properties of primary α
in Ti alloys
60
80
100
120
140
160
180
0 20 40 60 80 100
Indentationmodulus[GPa]
Declination angle
Indentation Modulus, MPa
Primary α
Ti64
Ti5-2.5
Ti811
Ti6242
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 20 40 60 80 100
IndentationYieldstrength[GPa]
Declination angle
Indentation Yield Strength, GPa
Primary α
Ti64
Ti5-2.5
Ti811
Ti6242](https://image.slidesharecdn.com/surya-190826170657/75/A-Machine-Learning-Framework-for-Materials-Knowledge-Systems-26-2048.jpg)










































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)









