Downloaded 193 times



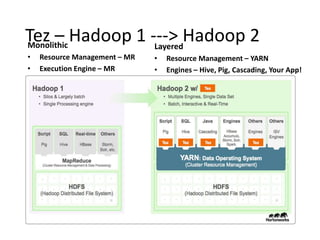



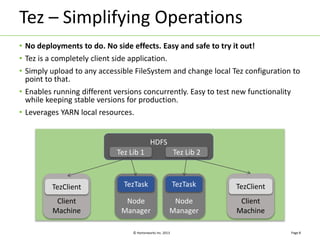
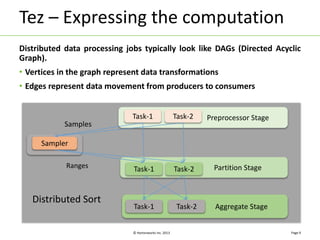

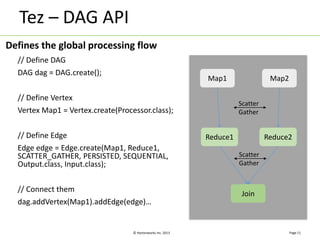
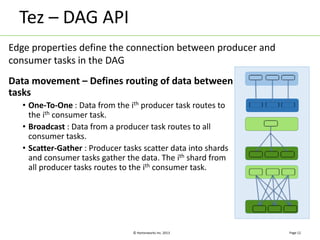
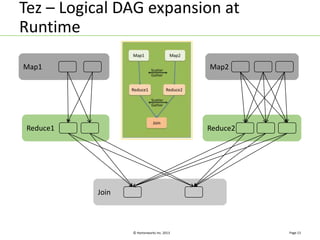

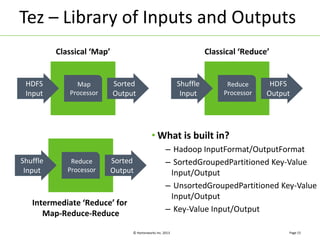
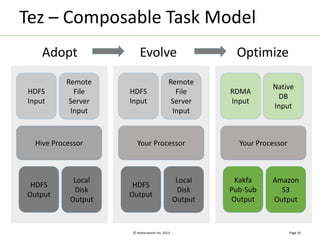

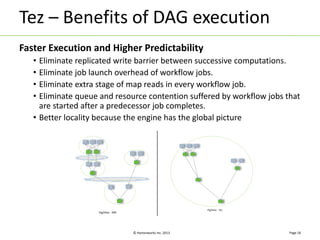
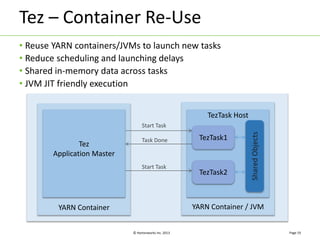
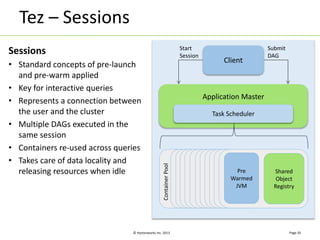



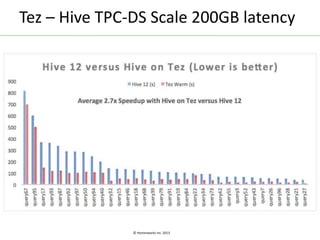
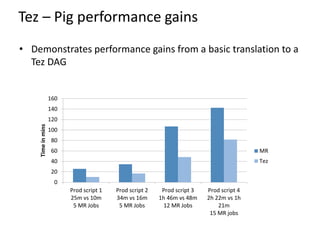

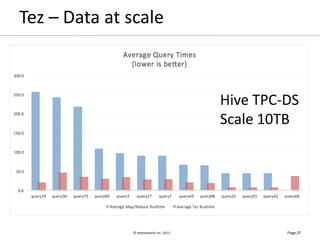
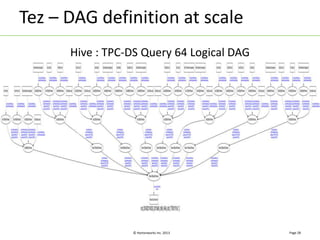

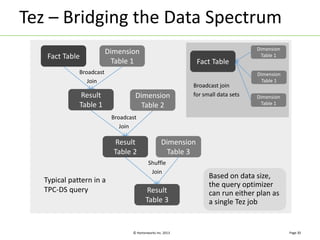








Apache Tez is a distributed execution framework designed for data-processing applications, built on top of YARN. It simplifies Hadoop operations by allowing custom application logic, optimizing performance, and facilitating better resource management and scalability. Tez enables applications to focus on domain-specific problems, providing higher application developer productivity and minimizing overheads.











































































































