Download as PDF, PPTX











![WORD COUNT EXAMPLE WITH CASCADING
5
!
!
String docPath = args[ 0 ];!
String wcPath = args[ 1 ];!
Properties properties = new Properties();!
AppProps.setApplicationJarClass( properties, Main.class );!
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );!
!
configuration
integration
!
// create source and sink taps!
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );!
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );!
!
processing
// specify a regex to split "document" text lines into token stream!
Fields token = new Fields( "token" );!
Fields text = new Fields( "text" );!
RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ [](),.]" );!
// only returns "token"!
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );!
// determine the word counts!
Pipe wcPipe = new Pipe( "wc", docPipe );!
wcPipe = new GroupBy( wcPipe, token );!
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );!
scheduling
!
// connect the taps, pipes, etc., into a flow definition!
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )!
.addSource( docPipe, docTap )!
.addTailSink( wcPipe, wcTap );!
// create the Flow!
Flow wcFlow = flowConnector.connect( flowDef ); // <<-- Unit of Work!
wcFlow.complete(); // <<-- Runs jobs on Cluster](https://image.slidesharecdn.com/cbag-bigdatameetupoct-141029170550-conversion-gate02/85/C-BAG-Big-Data-Meetup-Chennai-Oct-29-2014-Hortonworks-and-Concurrent-on-Cascading-19-320.jpg)
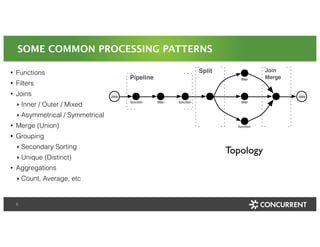




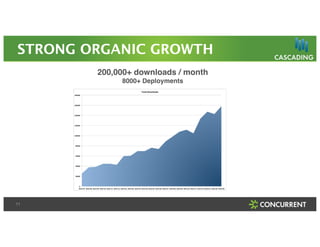




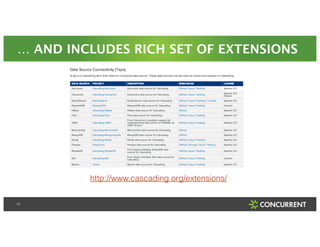









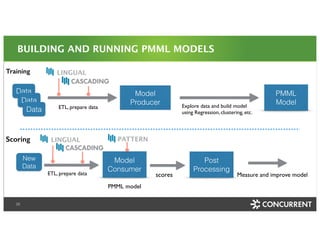

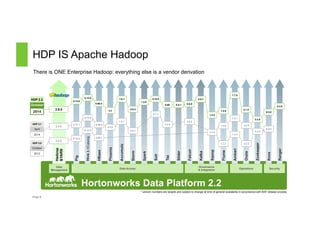
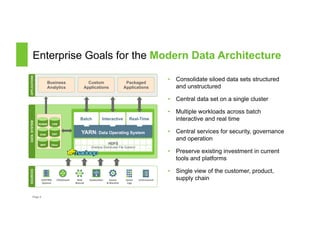
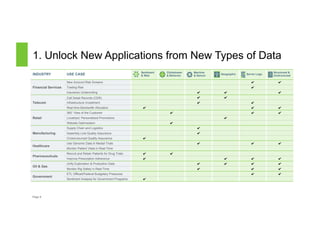
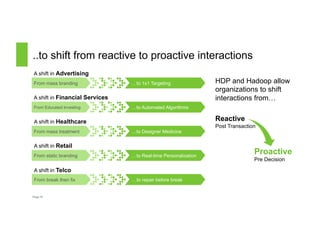
The document discusses a Big Data Meetup organized by C-BAG (Chennai Big Data Analytic Group) on October 29, 2014 in Chennai. It provides details about two speakers, Dhruv Kumar from Concurrent Inc. and Vinay Shukla from Hortonworks, who will discuss reducing development time for production-grade Hadoop applications and Hortonworks' Hadoop platform respectively. The remainder of the document consists of presentation slides that cover topics including the modern data architecture with Hadoop, enterprise goals for data architecture, unlocking applications from new data types, and case studies.























































































