Download as PDF, PPTX








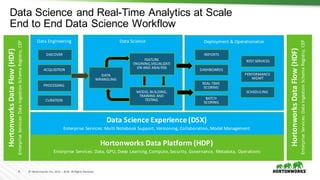























The document discusses the rapid growth of data science and real-time analytics, highlighting the increasing volume and complexity of data generated by connected devices and its implications for businesses. It emphasizes the need for advanced analytics solutions, such as those provided by IBM and Hortonworks, to effectively manage and utilize this data for tasks like fraud detection and intelligent job matching. The collaboration between IBM's hardware and Hortonworks' open-source software aims to enhance data science workflows and improve model training times significantly.


















































































