Downloaded 53 times











This document provides an overview of the Tesseract OCR engine, including a brief history of OCR technology, details about Tesseract's development and architecture, and announcements about version 2.00. It describes how Tesseract uses techniques like text line finding, baseline approximation, and static/adaptive classifiers to recognize words despite challenges with spacing, italics, and other font variations. The document also notes areas where commercial OCR systems may have advantages over Tesseract, such as page layout analysis, language support, and accuracy.
Introduction of Tesseract as an OCR engine.
Topics covered: history of OCR, Tesseract architecture, version announcement, training, enhancements.
Defined OCR and outlined its history, emphasizing that it predates electronic computers.
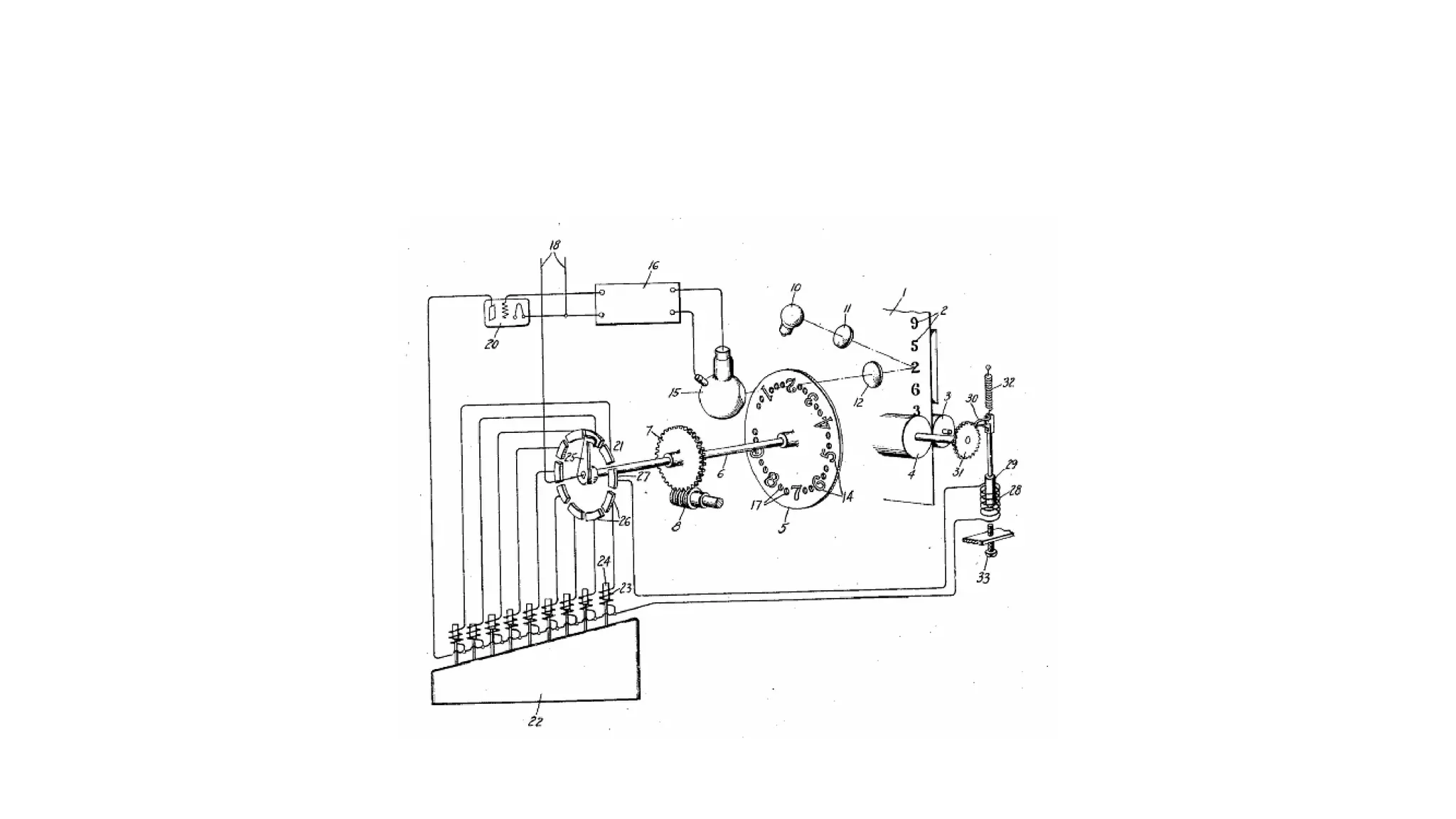
Key milestones from 1929 to 2000 in OCR technology, including significant machines and developments.
Tesseract's development timeline from 1985-1994, its testing against competitors, and open-source status.
Tesseract’s architecture overview, including baseline issues and line finding techniques.
Challenges in recognizing spaces, italics, and justified layouts, alongside Tesseract’s recognition methods.
Description of Tesseract's static and adaptive classifiers and the methods used for character recognition.
Announcement of Tesseract 2.00 features, including Unicode support and training for multiple languages.
Comparison highlighting Tesseract's advantages and areas for improvement relative to commercial OCR.