Download as PDF, PPTX




![5
©
Hortonworks
Inc.
2011
–
2016.
All
Rights
Reserved
OCR
At
Scale:
Use-‐cases
in
Journalism
à The
Problem
– Journalists
are
now
asked
to
analyze
large
volumes
of
data
– The
Panama
Papers
alone
were
2.6TB
of
data,
much
of
it
in
scanned
images
of
pages
– FOIA
requests
can
quickly
outstrip
the
reading
capability
of
a
single
person
or
team
à The
Value
ProposiAon
– Building
a
scalable
data
pipeline
to
extract
the
text
from
the
data
journalists
are
asked
to
mine
enables
more
advanced
analyAcs
and
be]er
reporAng.
– This
is
a
tool
to
enable
be]er
journalism](https://image.slidesharecdn.com/june29550hortonworksmiklavcicstella-160711180837/75/Scalable-OCR-with-NiFi-and-Tesseract-5-2048.jpg)







![15
©
Hortonworks
Inc.
2011
–
2016.
All
Rights
Reserved
Ques>ons?
All
of
this
sorware
shown
in
this
presentaAon
is
open
source
and
located
at
h]ps://github.com/mmiklavc/scalable-‐ocr
Find
us
on
Twi]er
@casey_stella
@MikeMiklavcic](https://image.slidesharecdn.com/june29550hortonworksmiklavcicstella-160711180837/75/Scalable-OCR-with-NiFi-and-Tesseract-15-2048.jpg)

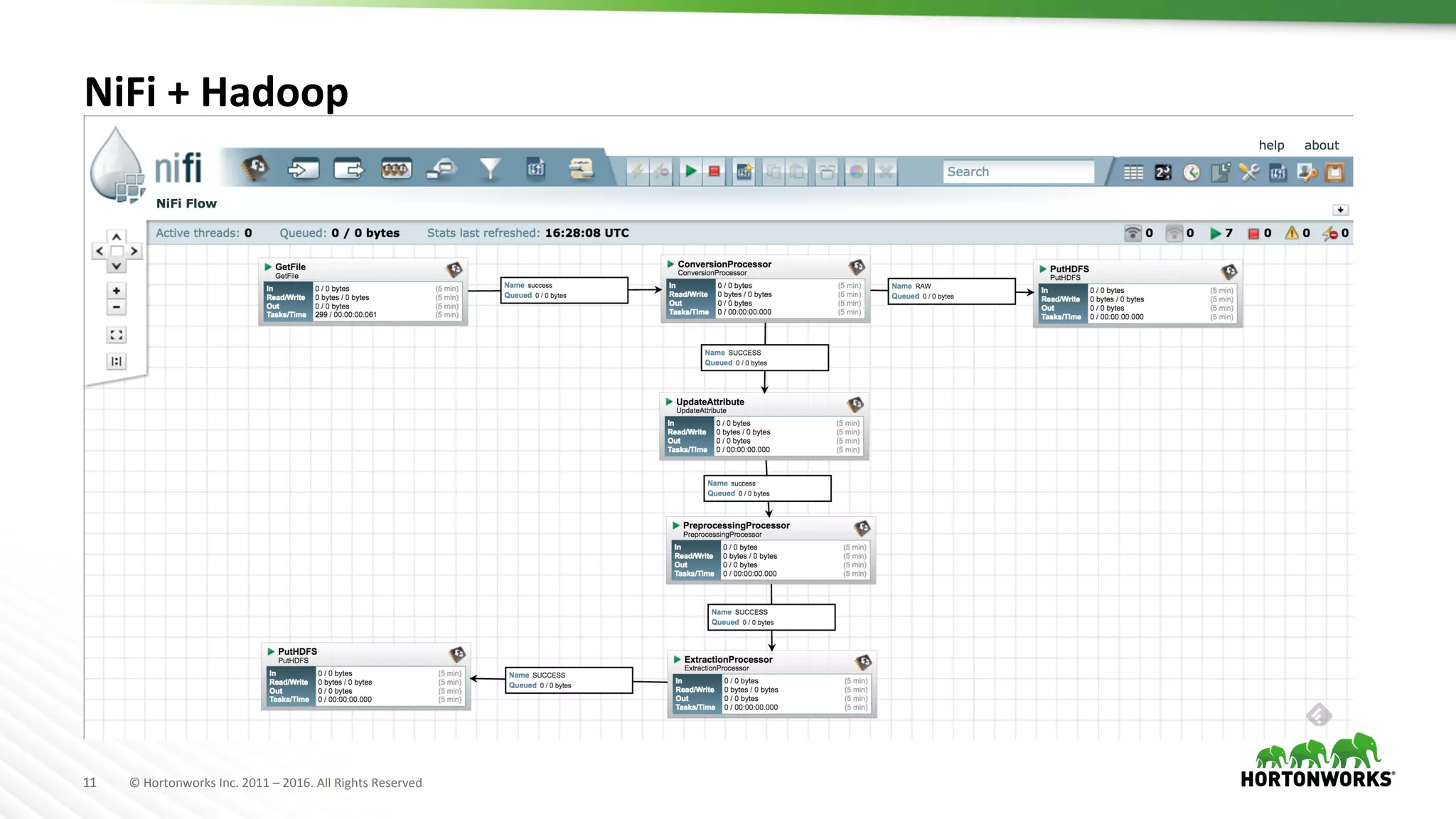
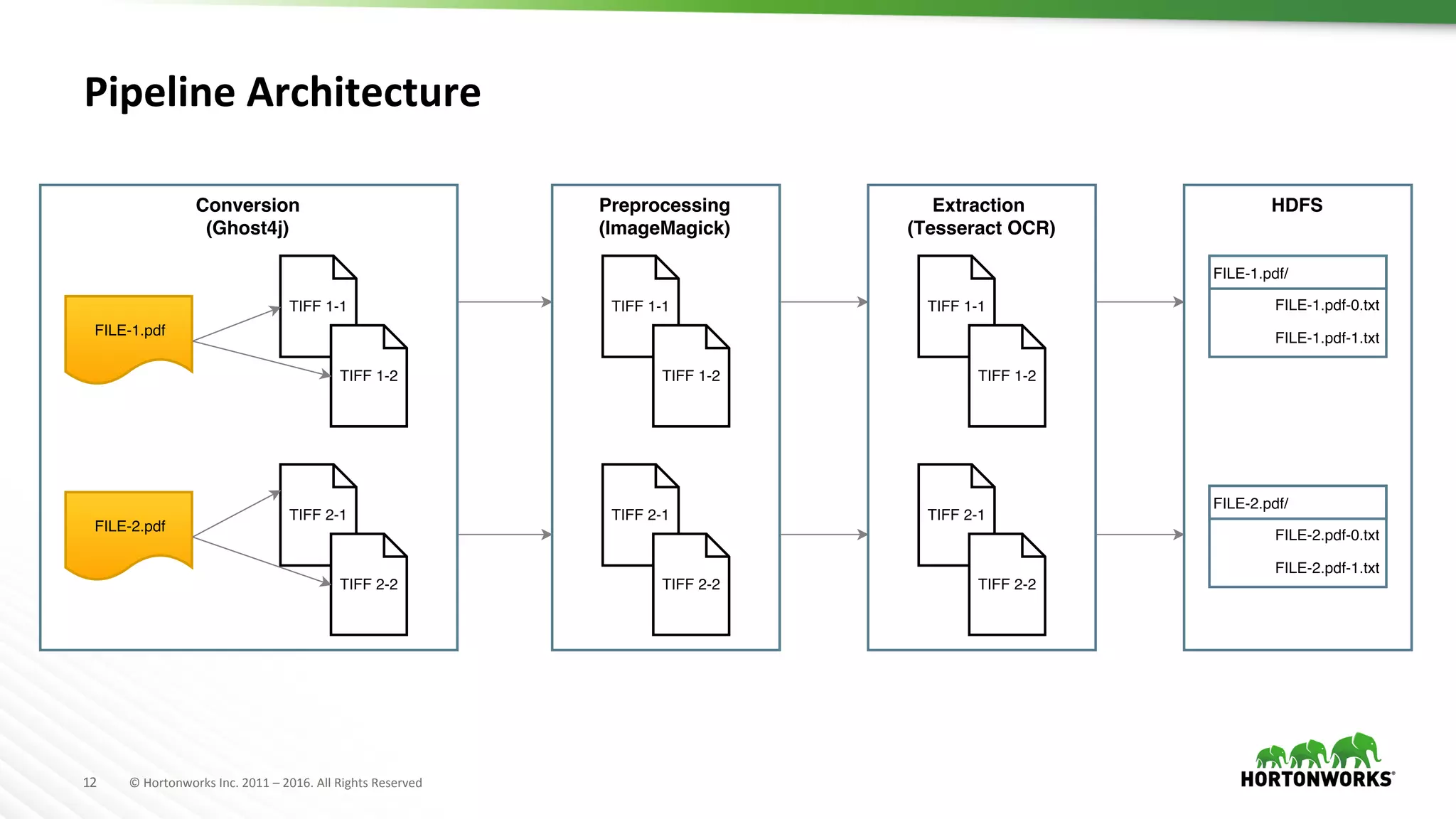
This document describes a scalable optical character recognition (OCR) pipeline using Apache NiFi and Tesseract to extract text from PDF documents at large scale. The pipeline includes steps for converting PDFs to images, preprocessing the images using ImageMagick to enhance text, and performing OCR with Tesseract to extract text. NiFi is used to operationalize the pipeline and handle large-scale processing. Example use cases discussed include analyzing medical records and extracting text from large datasets to enable better journalism.













































![[CB19] Shattering the dark: uncovering vulnerabilities of the dark web by Tak...](https://cdn.slidesharecdn.com/ss_thumbnails/cb19-shattering-the-dark-uncovering-vulnerabilities-of-the-dark-web-by-takahiro-yoshimura-kenya-yosh-191217054359-thumbnail.jpg?width=640&height=640&fit=bounds)









































