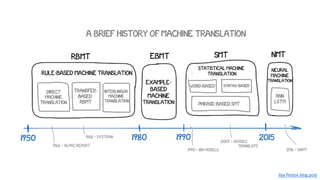
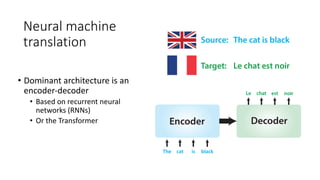
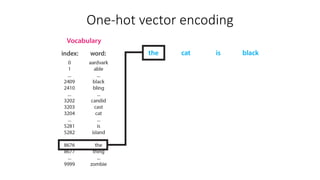
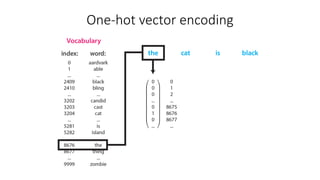
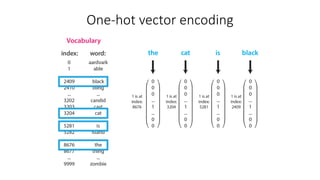
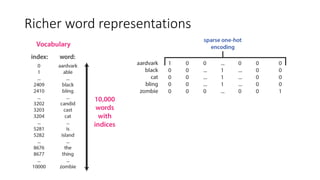
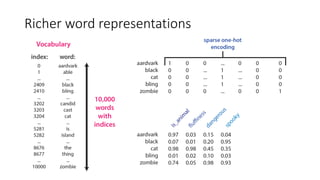
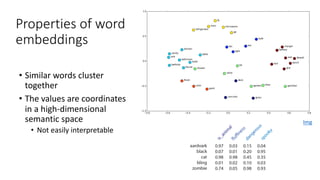
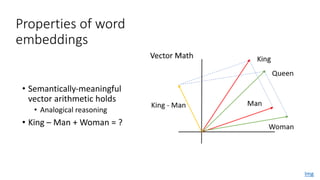
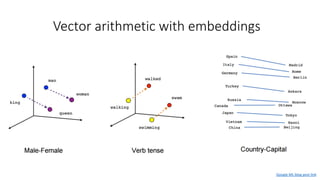
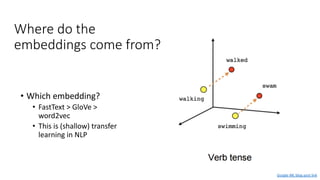
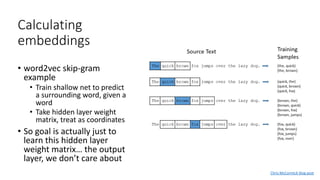
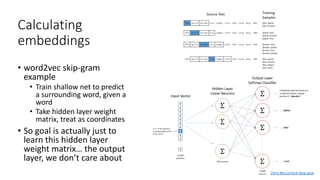
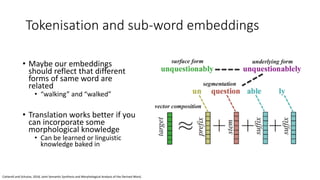
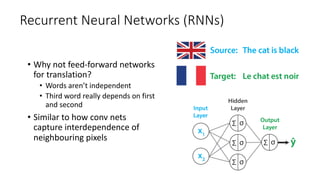
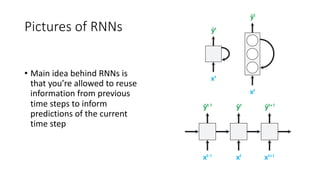
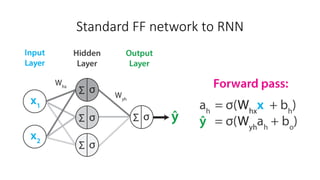
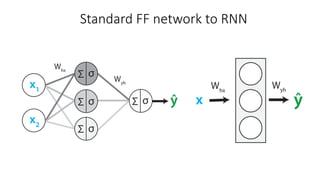
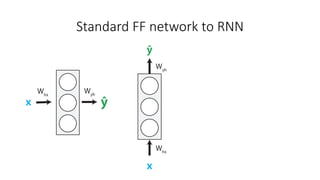
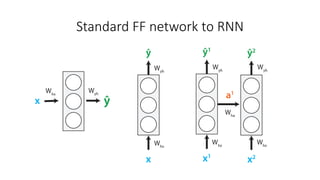
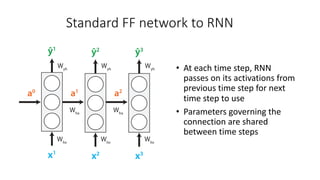
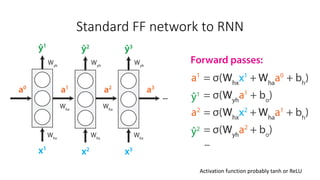
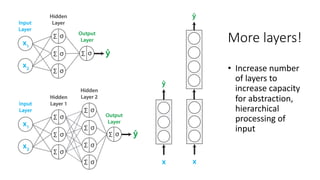
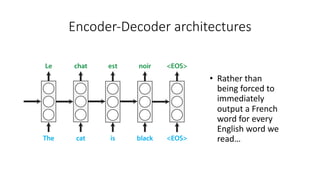
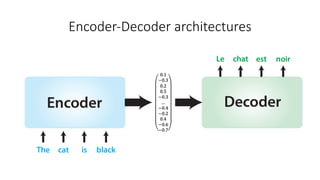
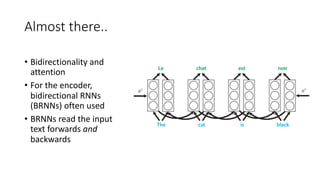
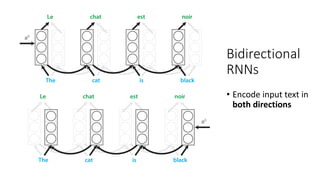
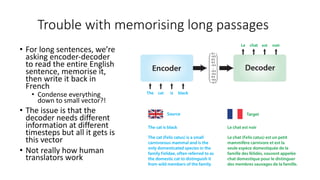
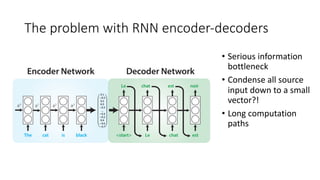
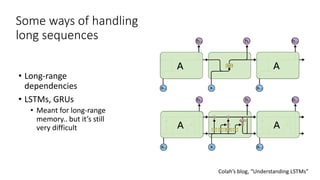
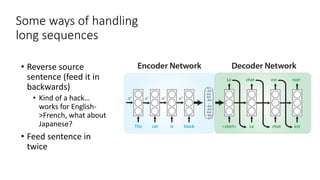
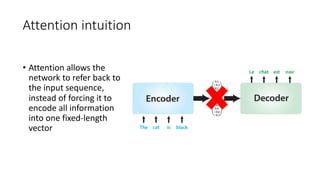
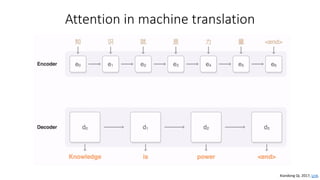
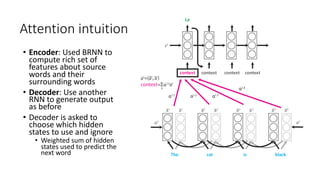
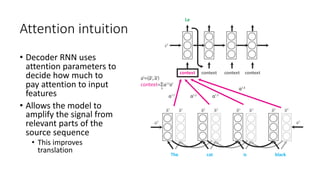
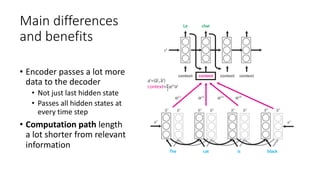
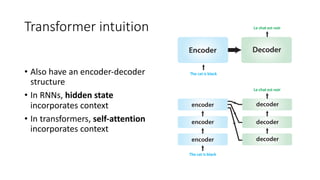
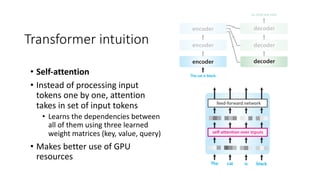
The document discusses building a neural machine translation (NMT) system, covering fundamentals such as data requirements, architectures like recurrent neural networks and transformers, and the significance of word embeddings. It highlights the complexity of language and the importance of NMT in addressing communication needs while noting challenges like data scarcity and long-range dependencies. Additionally, it outlines the tech stack and recommendations for implementing effective machine translation systems.