Downloaded 91 times


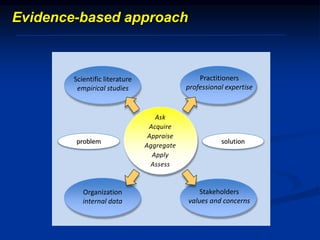


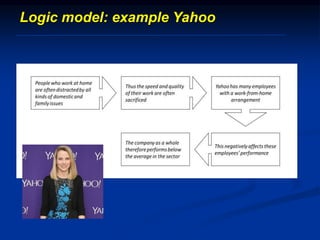

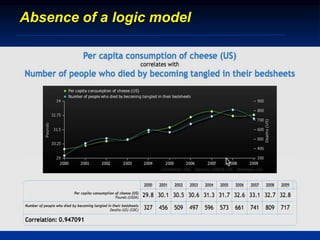














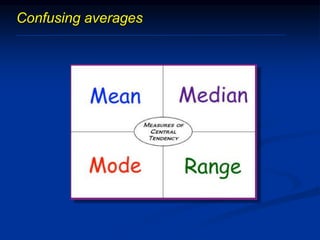
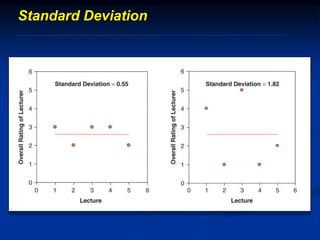



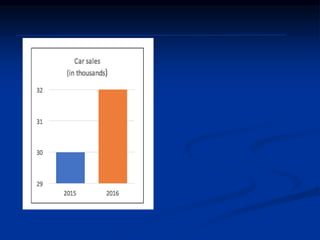
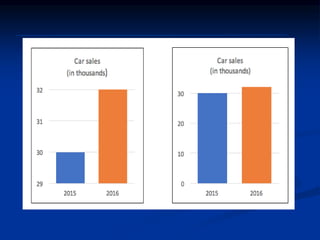
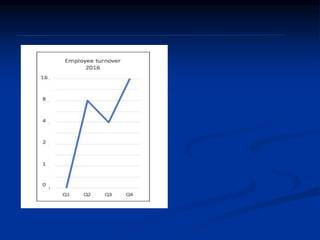
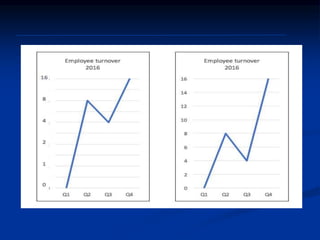
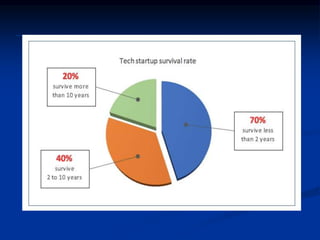
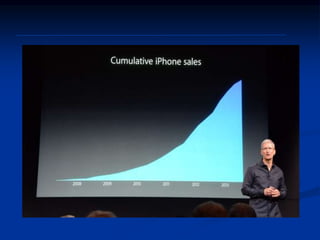

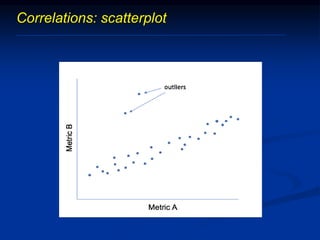


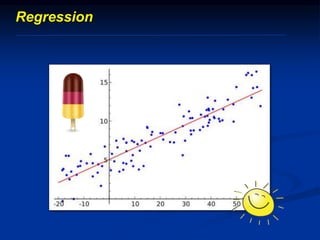


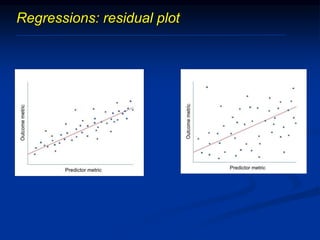









The document discusses several barriers students should be aware of when critically appraising organizational data, including: 1) the absence of a logic model, 2) garbage in/garbage out, 3) measurement errors, 4) small sample sizes, 5) confusing percentages and averages, 6) misleading graphs, and 7) issues with regression analysis like goodness of fit. It provides examples and definitions for each barrier to help students understand potential problems with organizational data and how to properly evaluate it.






















































































