



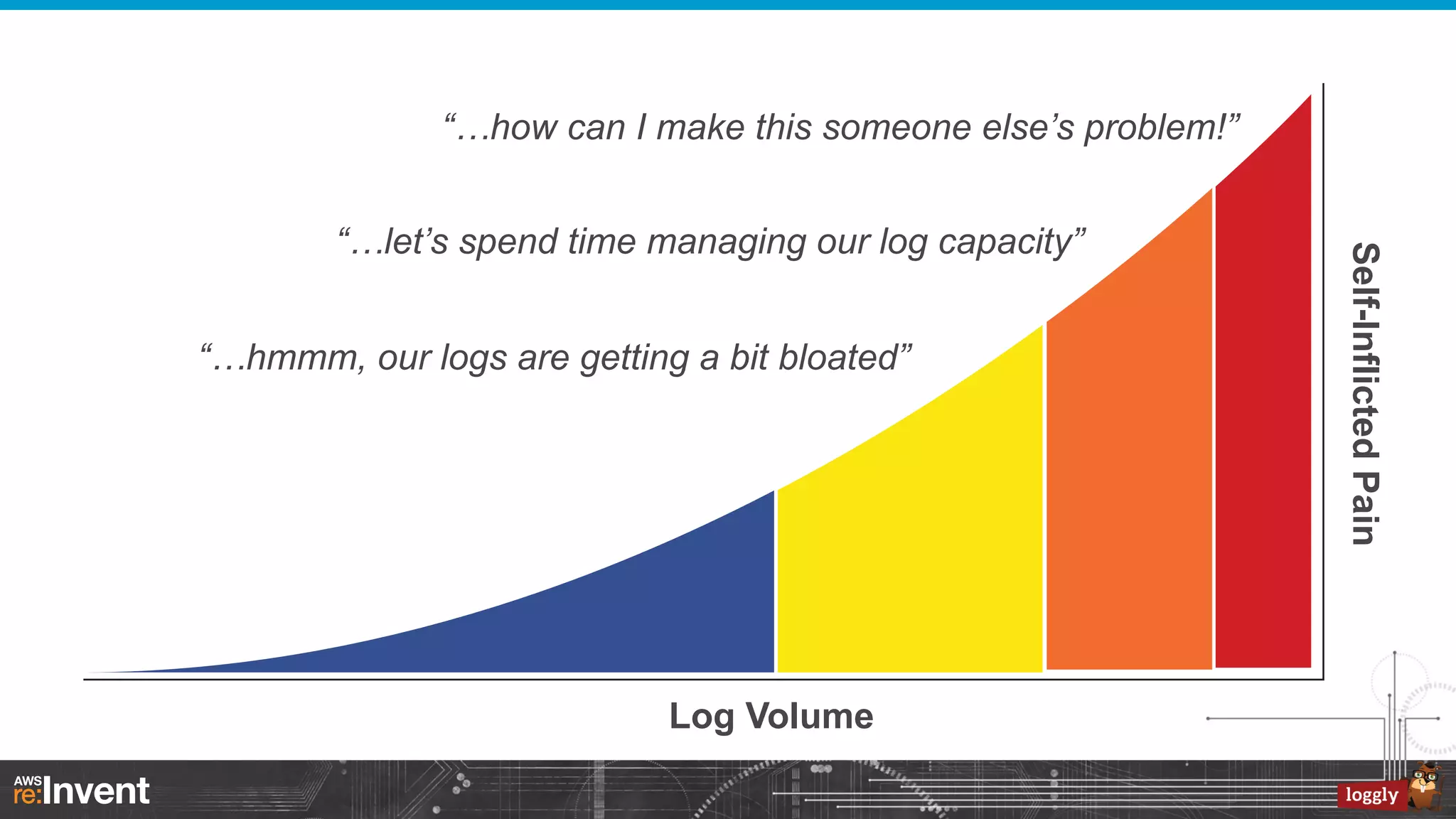

![You Have Logs...
2013-10-25T18:35:43.387+0000: 441.482: [GC [PSYoungGen: 2430541K->268617K(2484544K)] 7687523K>5660738K(8076992K), 0.3266870 secs] [Times: user=1.05 sys=0.17, real=0.33 secs]!
2013-10-25T18:35:43.714+0000: 441.809: [Full GC [PSYoungGen: 268617K->0K(2484544K)] [ParOldGen: 5392121K>354965K(5592448K)] 5660738K->354965K(8076992K) [PSPermGen: 44444K->44395K(83968K)], 0.9225290 secs] [Times:
user=2.22 sys=0.26, real=0.92 secs]!
• In this case, JVM garbage collection logs
enabled with…
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps](https://image.slidesharecdn.com/aws-reinvent-loggly-session-finalslideshare-131121154337-phpapp01/75/AWS-re-Invent-presentation-Unmeltable-Infrastructure-at-Scale-by-Loggly-8-2048.jpg)





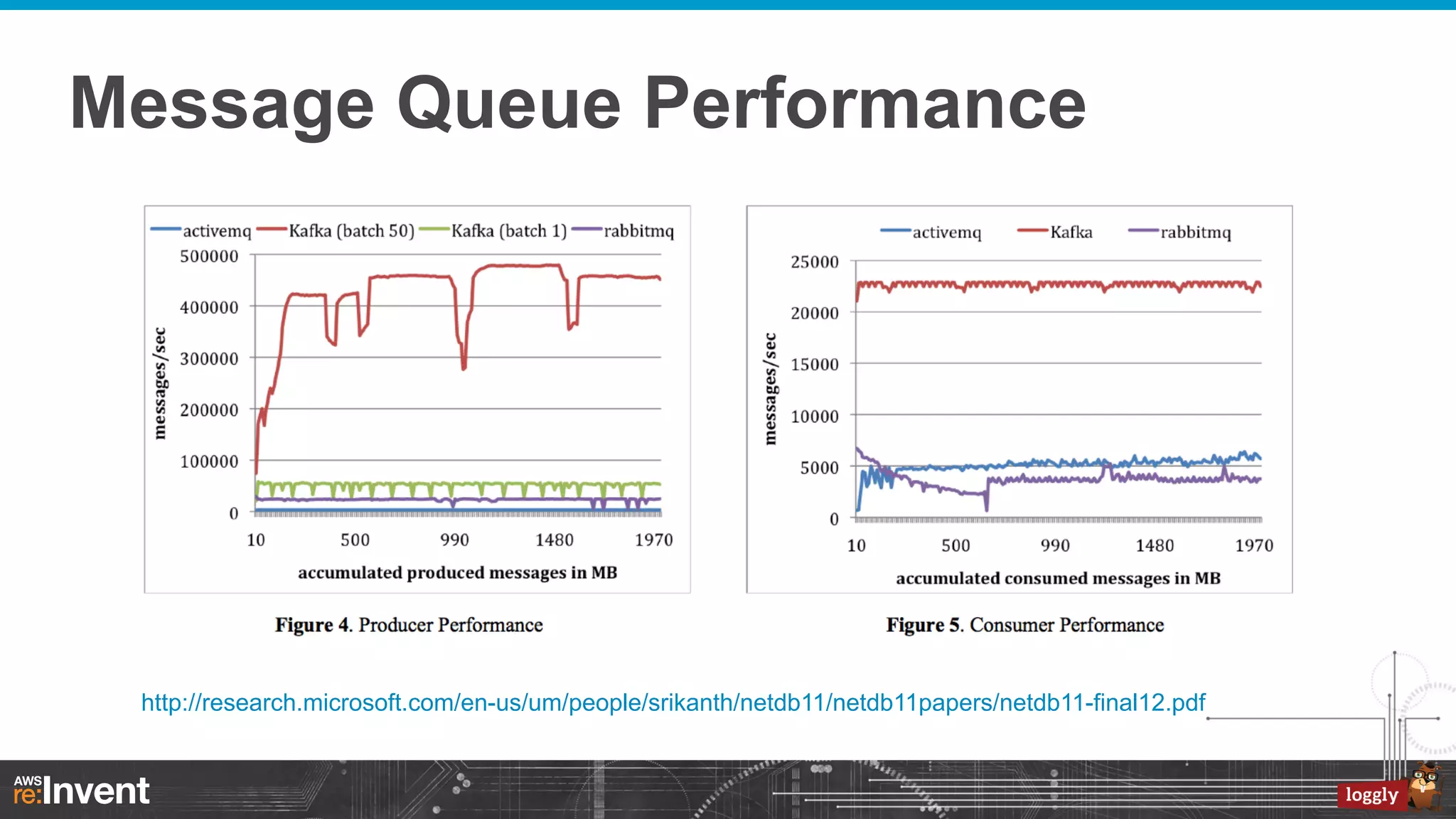

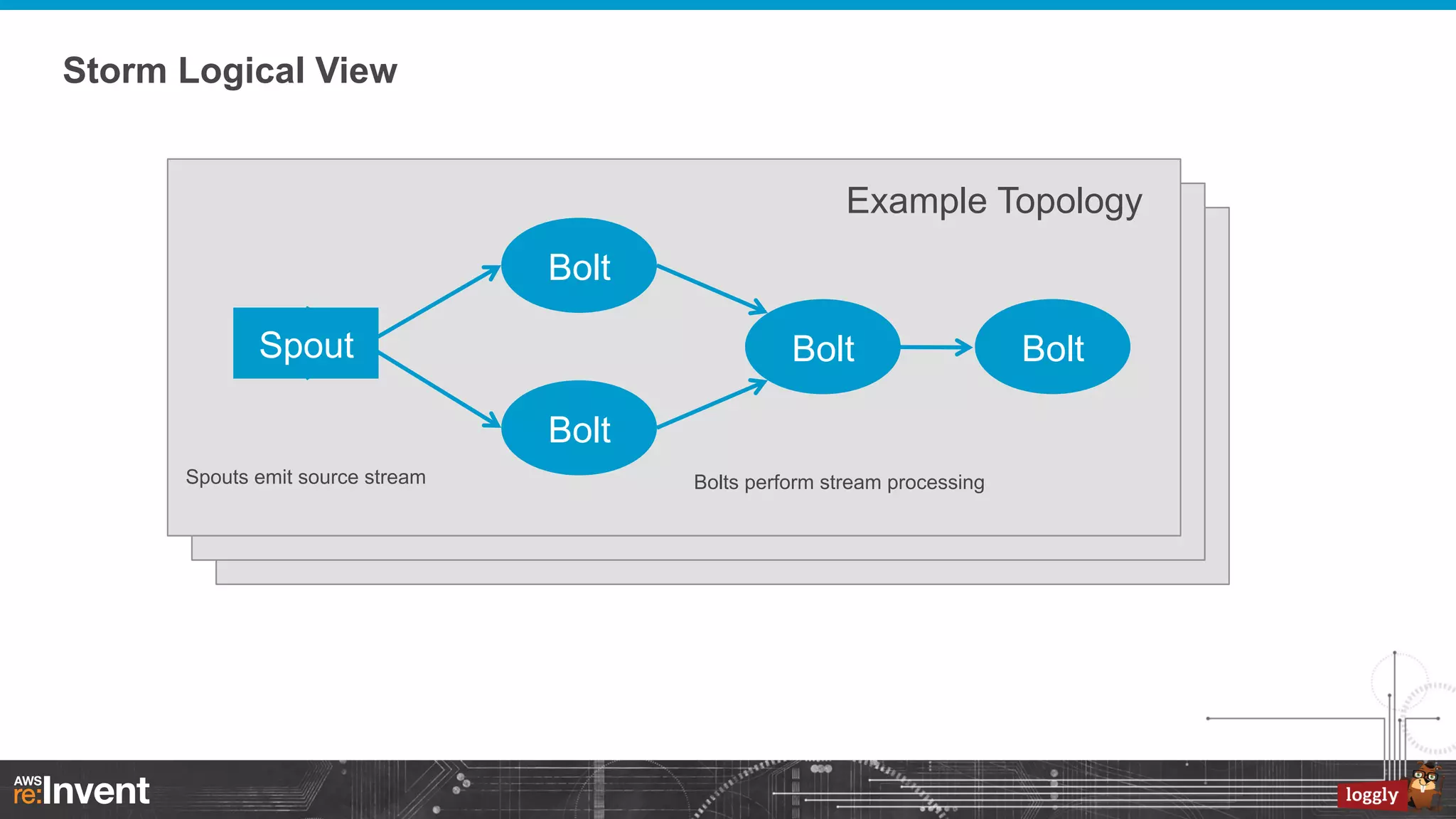
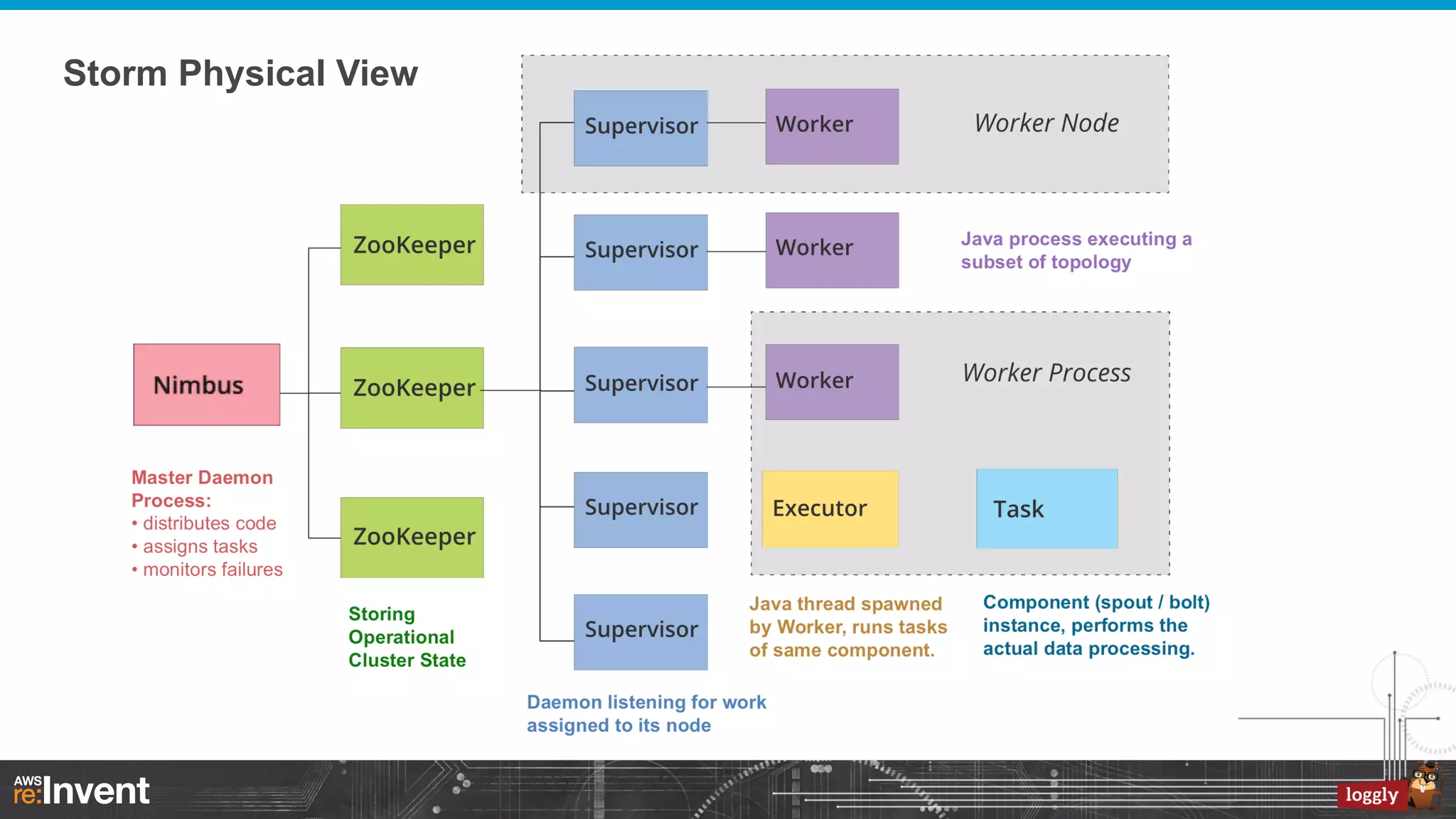

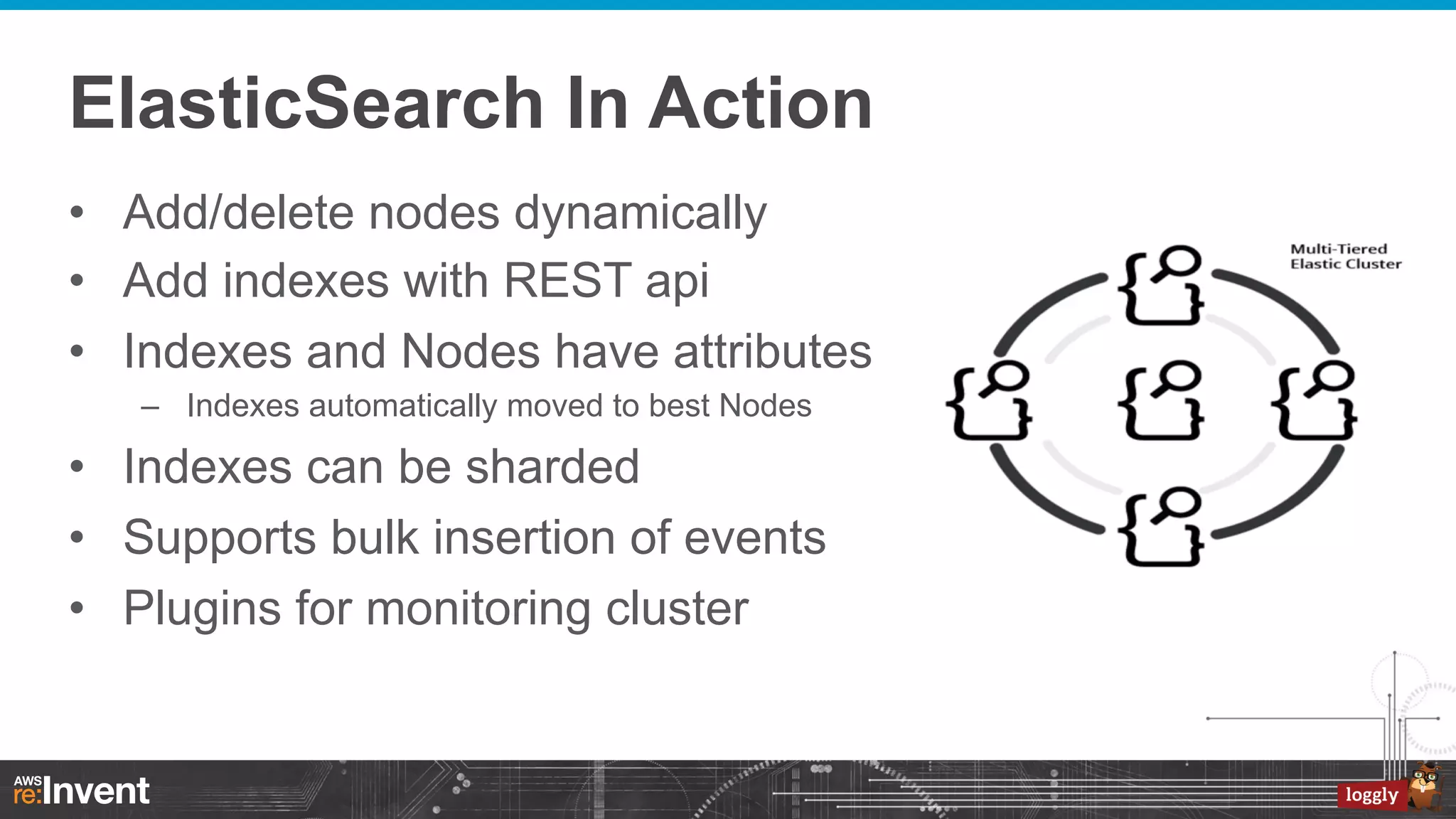





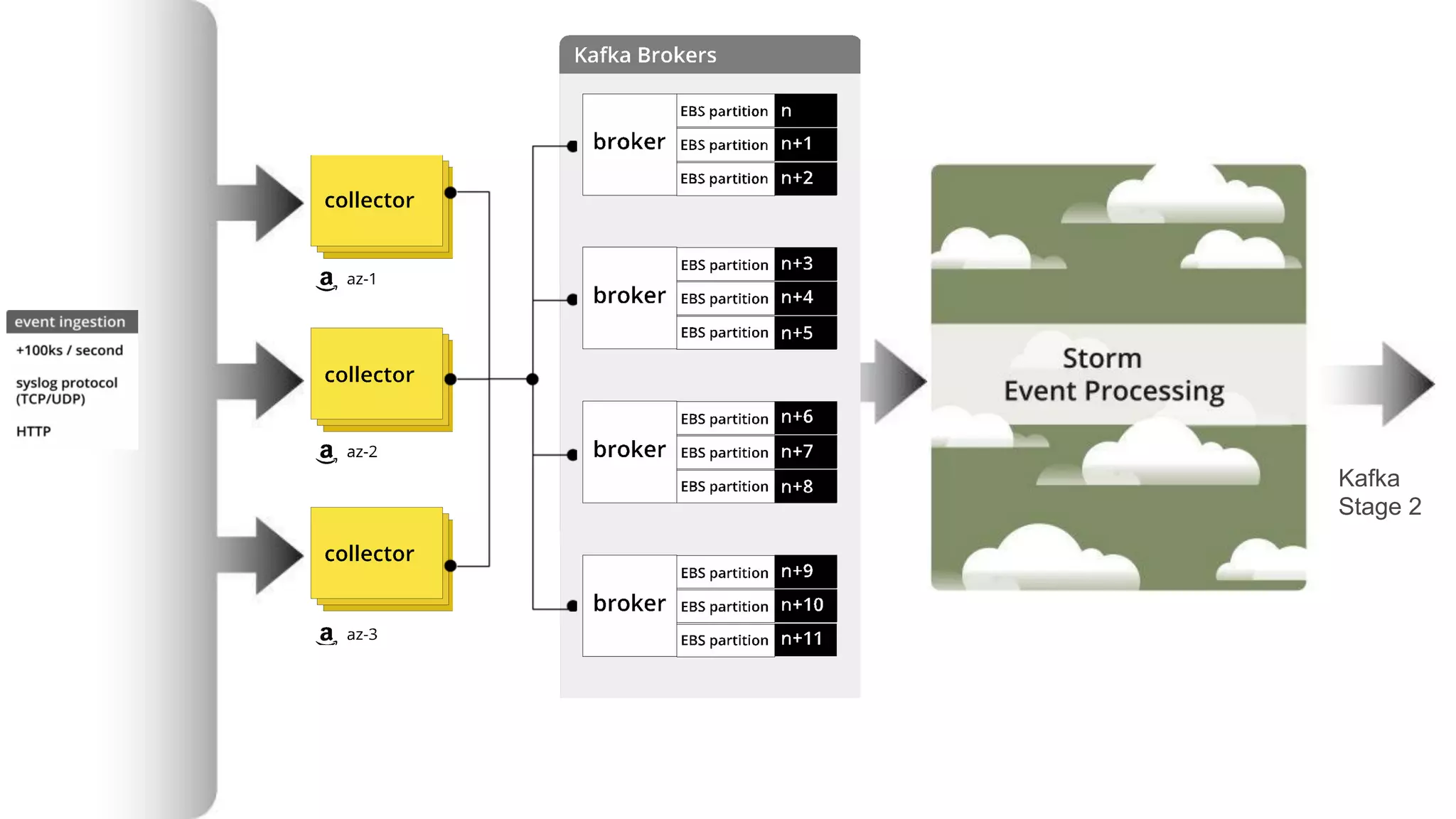
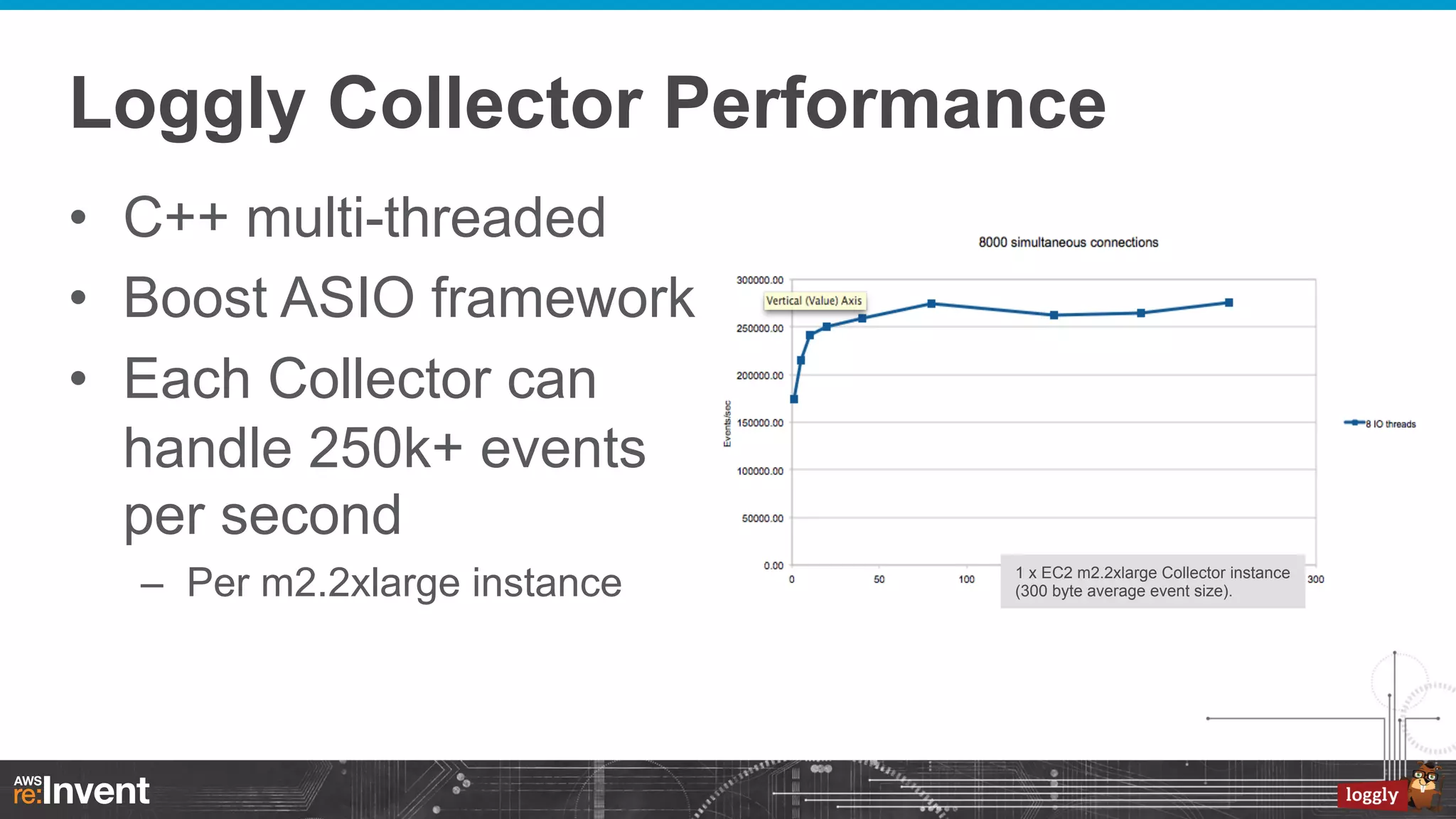

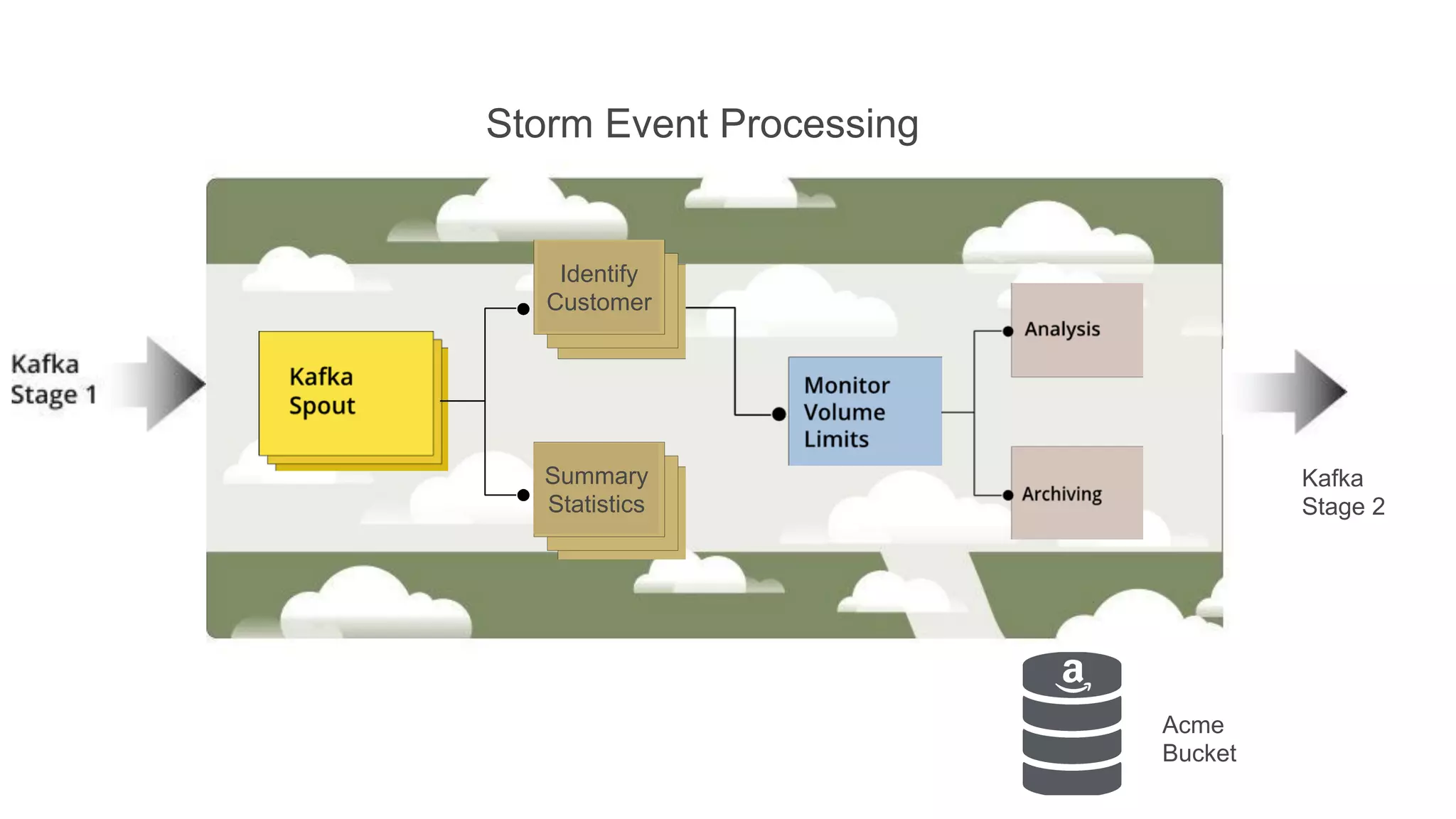

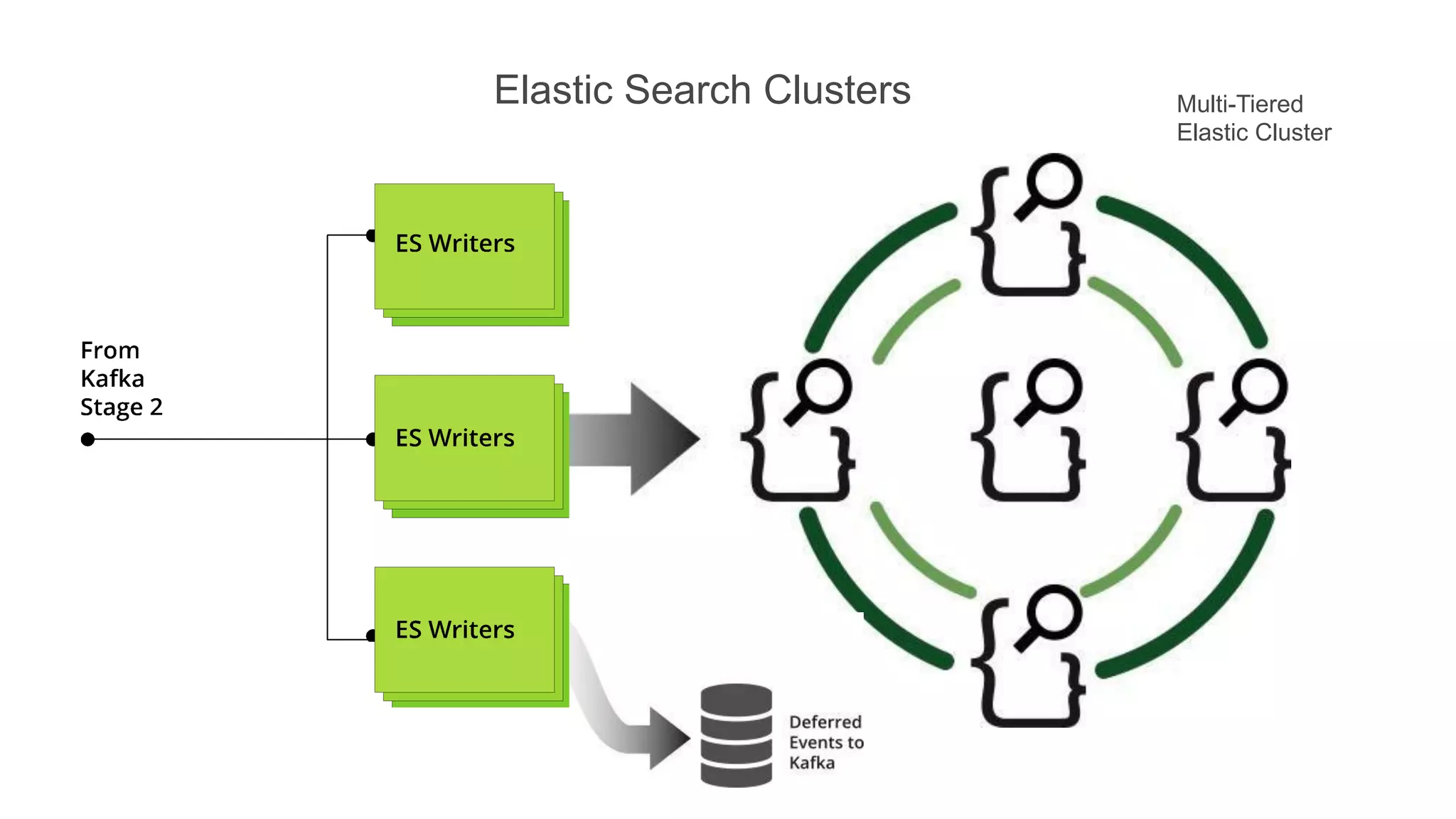

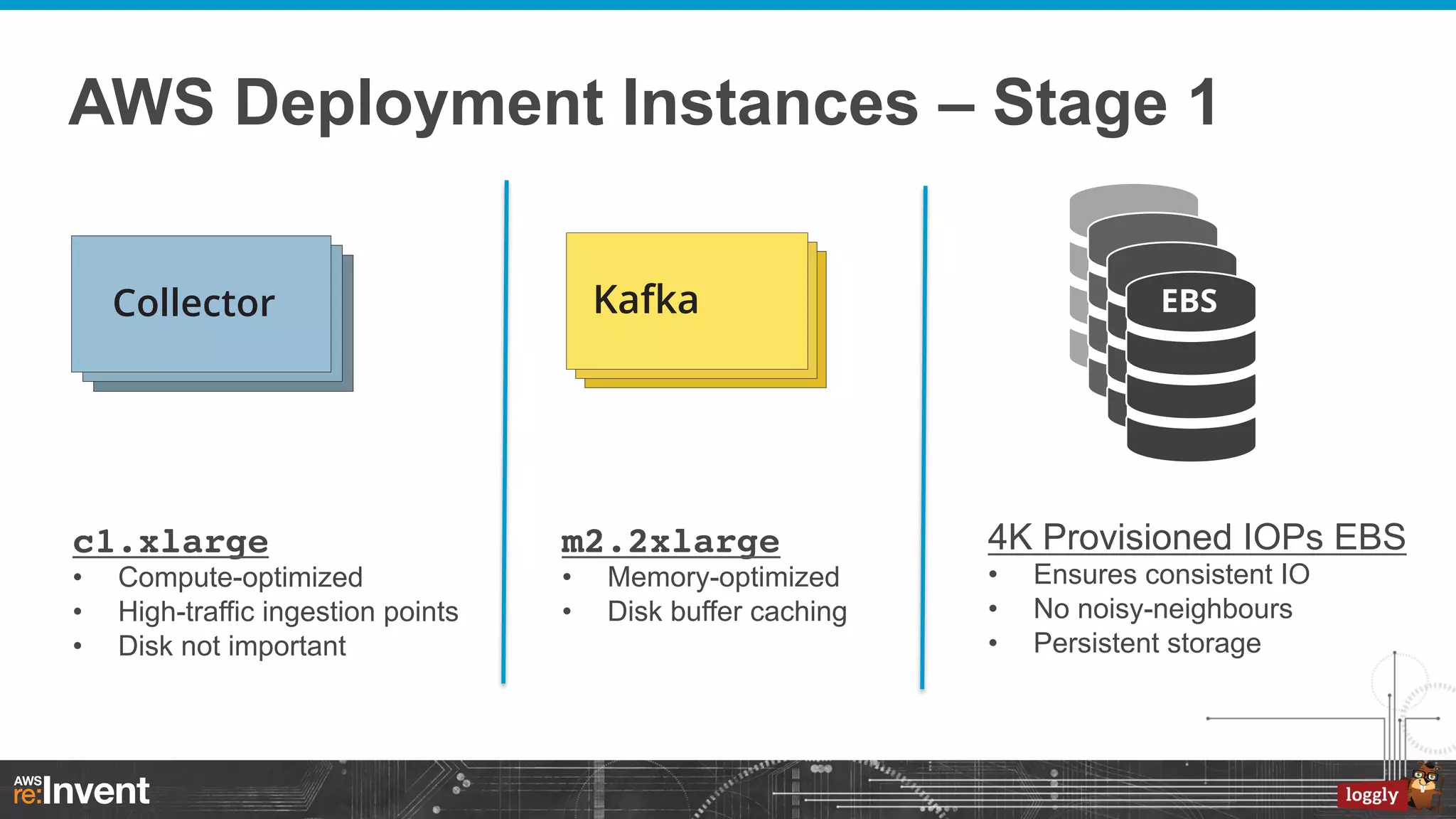
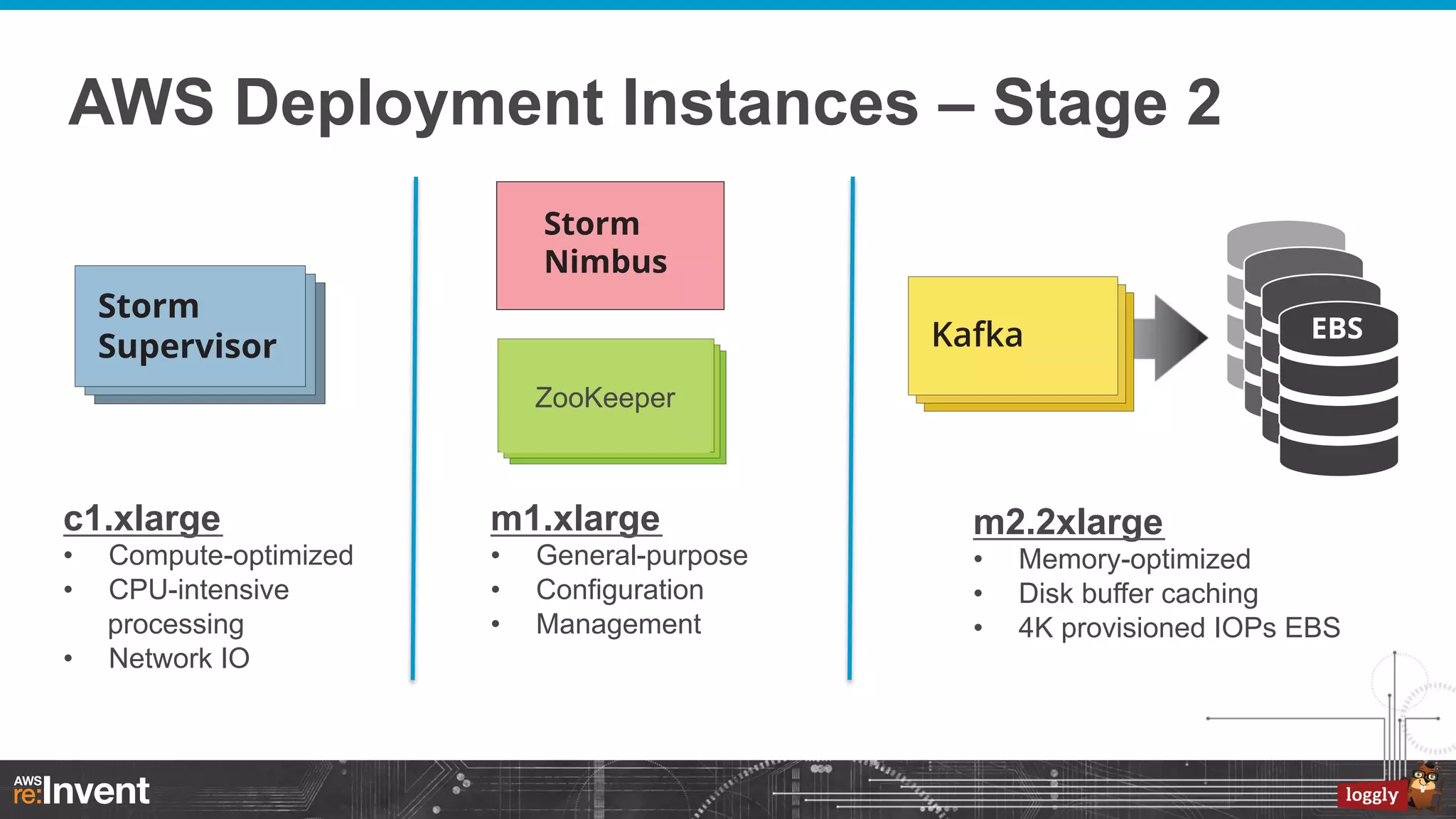
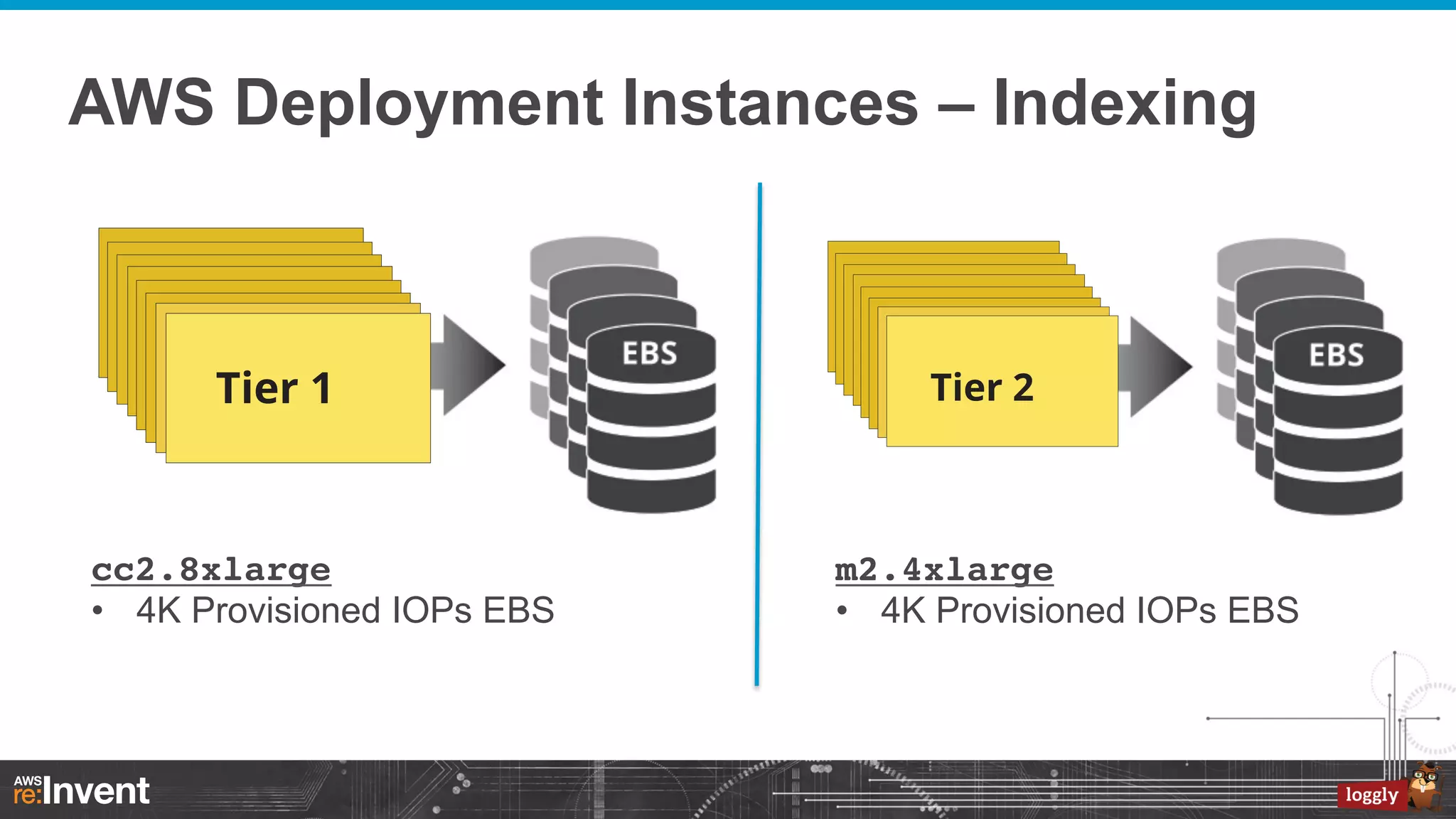






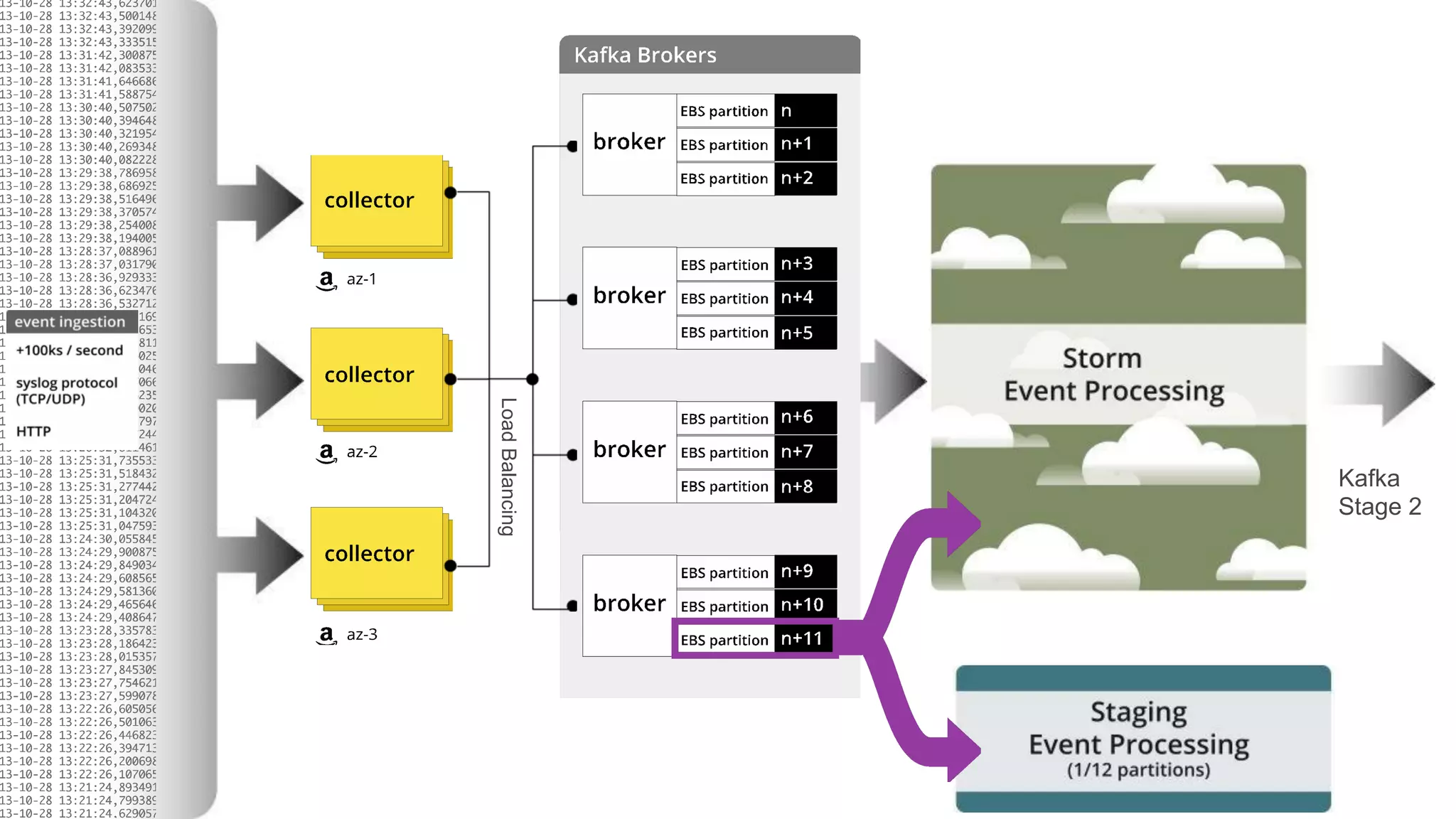

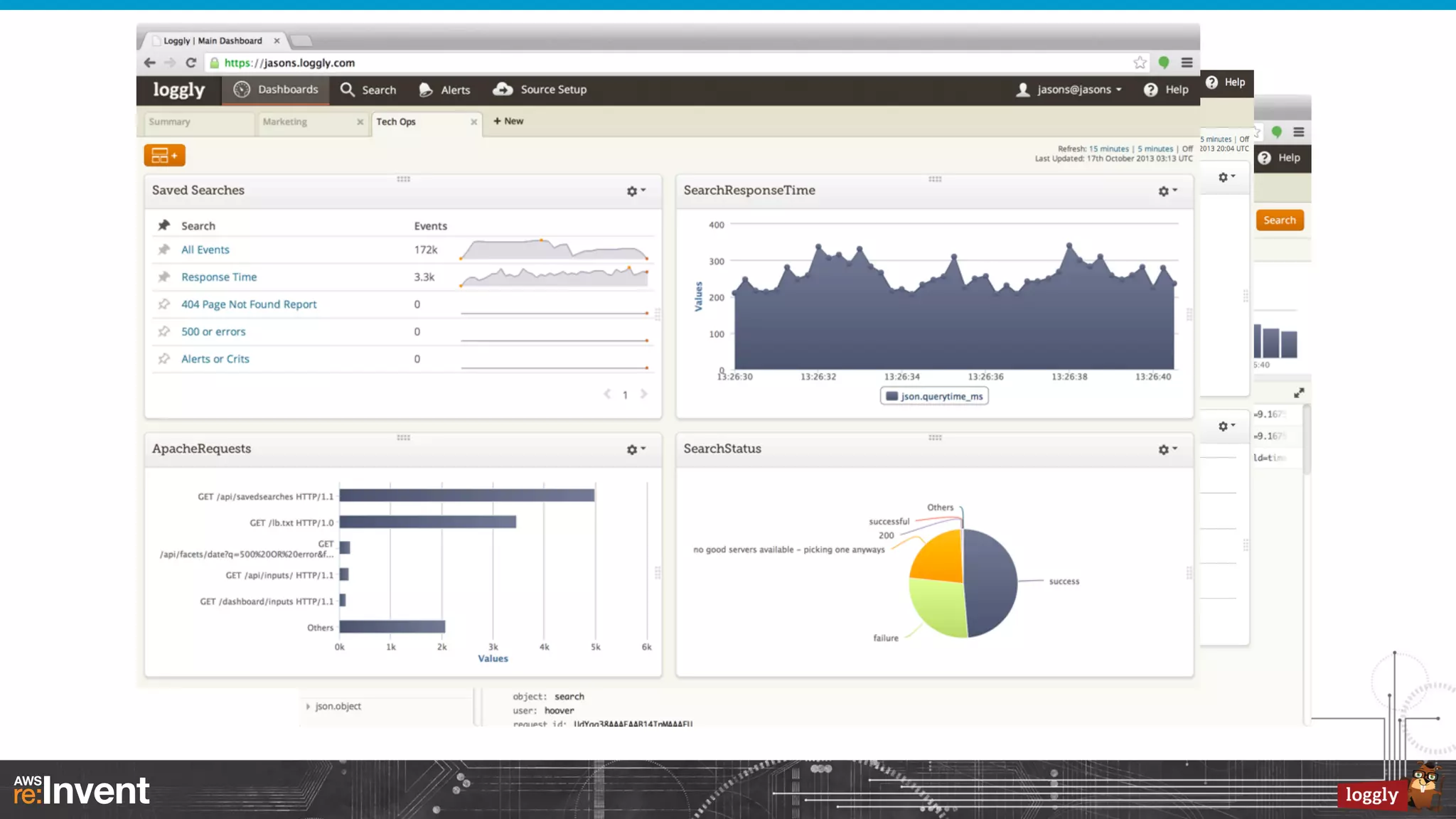




This document summarizes Loggly's transition from their first generation log management infrastructure to their second generation infrastructure built on Apache Kafka, Twitter Storm, and ElasticSearch on AWS. The first generation faced challenges around tightly coupling event ingestion and indexing. The new system uses Kafka as a persistent queue, Storm for real-time event processing, and ElasticSearch for search and storage. This architecture leverages AWS services like auto-scaling and provisioned IOPS for high availability and scale. The new system provides improved elasticity, multi-tenancy, and a pre-production staging environment.

















































![[DSC Europe 23] Muhammad Arslan - A Journey of Auditlogs from Kafka to Elasti...](https://cdn.slidesharecdn.com/ss_thumbnails/muhammad-arslan-journey-of-auditlogs-231128233713-59253f09-thumbnail.jpg?width=640&height=640&fit=bounds)






















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















