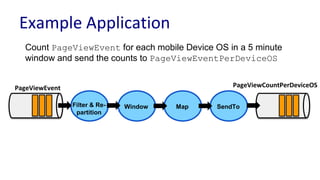
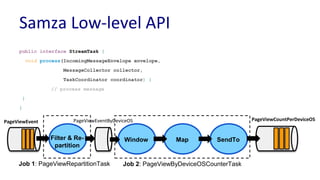
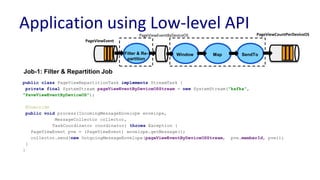
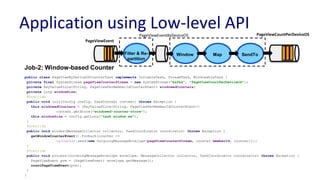
Downloaded 63 times




















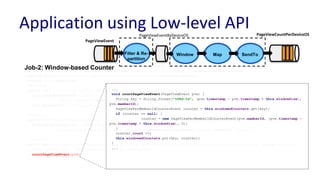







![Embedding Processor within Application
- An instance of the processor is
embedded within user’s application
- LocalApplicationRunner helps launch
the processor within the application
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new
LocalApplicationRunner(config);
CountByDeviceOSApplication app = new
CountByDeviceOSApplication();
runner.run(app);
runner.waitForFinish();
}](https://image.slidesharecdn.com/navinarameshunifiedbatchampstreamprocessingwithapachesamza-170925184825/85/Unified-Batch-Stream-Processing-with-Apache-Samza-55-320.jpg)
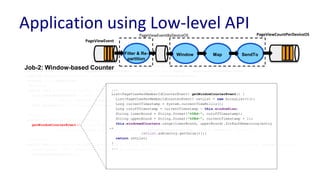
![Pluggable Coordination Config
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new
LocalApplicationRunner(config);
CountByDeviceOSApplication app = new
CountByDeviceOSApplication();
runner.run(app);
runner.waitForFinish();
}
Configs with Zk-based coordination
job.coordinator.factory =
org.apache.samza.zk.ZkJobCoordinatorFactory
job.coordinator.zk.connect = foobar:2181/samza](https://image.slidesharecdn.com/navinarameshunifiedbatchampstreamprocessingwithapachesamza-170925184825/85/Unified-Batch-Stream-Processing-with-Apache-Samza-56-320.jpg)
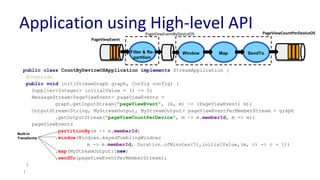
![Pluggable Coordination Config
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new
LocalApplicationRunner(config);
CountByDeviceOSApplication app = new
CountByDeviceOSApplication();
runner.run(app);
runner.waitForFinish();
}
Configs with Azure-based coordination:
job.coordinator.factory =
org.apache.samza.azure.AzureJobCoordinatorFactory
job.coordinator.azure.connect = http://foobar:29892/storage/
Configs with Zk-based coordination
job.coordinator.factory =
org.apache.samza.zk.ZkJobCoordinatorFactory
job.coordinator.zk.connect = foobar:2181/samza](https://image.slidesharecdn.com/navinarameshunifiedbatchampstreamprocessingwithapachesamza-170925184825/85/Unified-Batch-Stream-Processing-with-Apache-Samza-57-320.jpg)
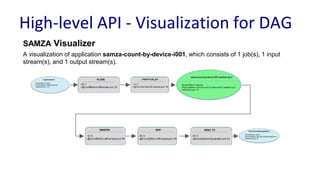
![Pluggable Coordination Config
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new
LocalApplicationRunner(config);
CountByDeviceOSApplication app = new
CountByDeviceOSApplication();
runner.run(app);
runner.waitForFinish();
}
Only Config Change!
Configs with Azure-based coordination:
job.coordinator.factory =
org.apache.samza.azure.AzureJobCoordinatorFactory
job.coordinator.azure.connect = http://foobar:29892/storage/
Configs with Zk-based coordination
job.coordinator.factory =
org.apache.samza.zk.ZkJobCoordinatorFactory
job.coordinator.zk.connect = foobar:2181/samza](https://image.slidesharecdn.com/navinarameshunifiedbatchampstreamprocessingwithapachesamza-170925184825/85/Unified-Batch-Stream-Processing-with-Apache-Samza-58-320.jpg)
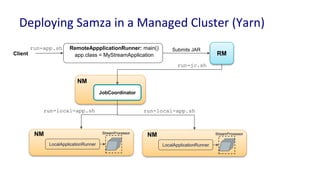
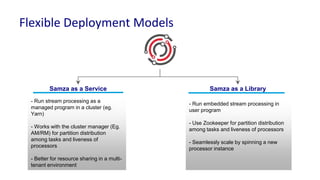




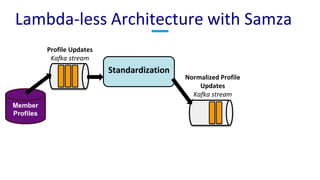
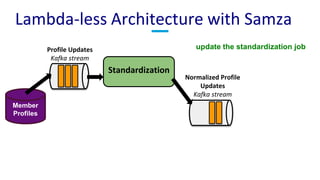
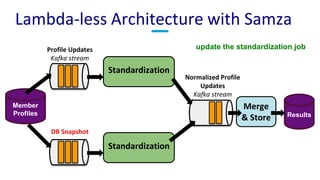
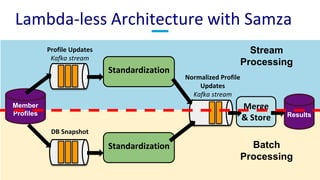
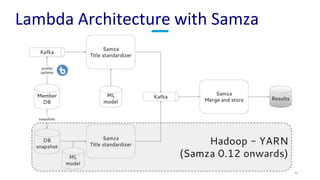

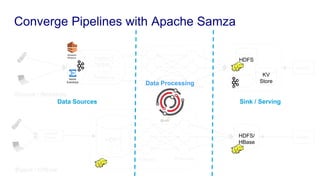
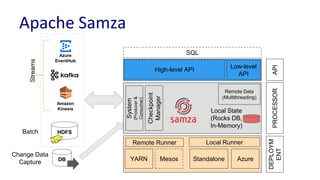
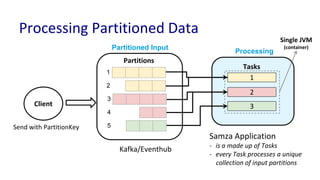
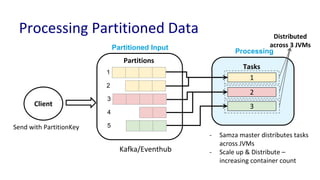
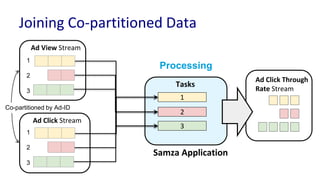
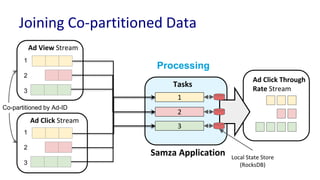
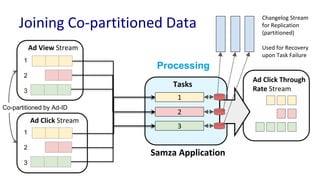
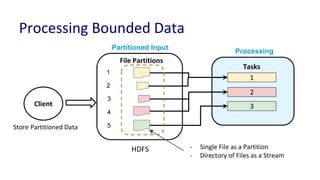
The document discusses unified batch and stream processing at LinkedIn using Apache Samza, highlighting its role in various data processing scenarios, such as real-time analytics and security measures. Apache Samza supports both batch and stream processing through a unified API, allowing for flexible deployment models and efficient state management. It emphasizes the challenges of maintaining separate systems for batch and stream processing and proposes a solution by treating batch processing as a special case of streaming.






















































































