Download as PDF, PPTX




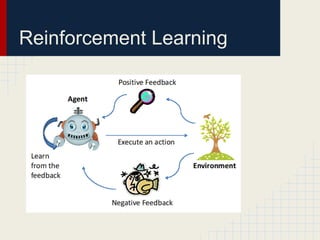






















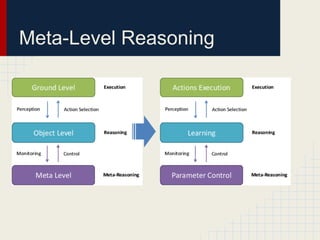
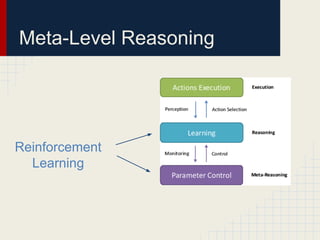

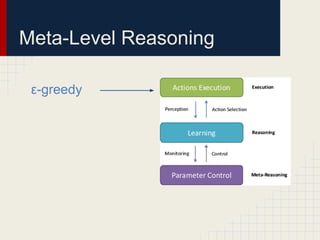






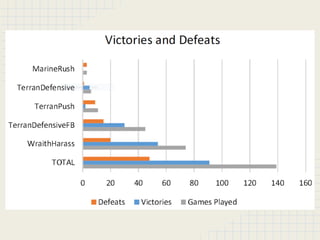
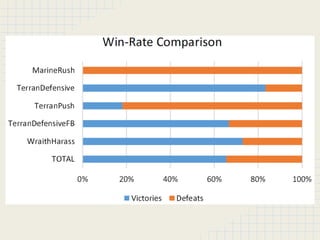
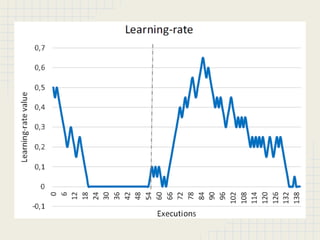
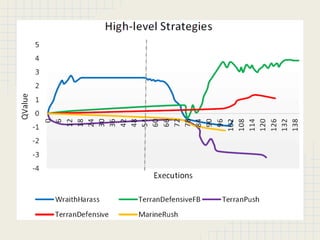




This document discusses using reinforcement learning and meta-level reasoning to develop adaptive high-level strategies in StarCraft. It introduces Q-learning as a reinforcement learning technique to update state-action values. A meta-level reinforcement learning approach is then used to select exploration rates and learning rates over time based on the agent's need to learn. Experiments inject code into StarCraft using BWAPI to implement different Terran strategies and apply meta-level reasoning to select strategies and dynamically adjust hyperparameters. Results showed this approach enabled the development of adaptive high-level strategies in the complex StarCraft environment.









![Q-Learning Algorithm: A Concise Introduction [Shakeeb A.]](https://cdn.slidesharecdn.com/ss_thumbnails/q-learningshakeebabuzarmustafasneha-200921155609-thumbnail.jpg?width=640&height=640&fit=bounds)




































