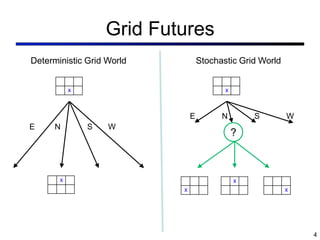
This document provides an overview of reinforcement learning concepts. It introduces reinforcement learning as using rewards to learn how to maximize utility. It describes Markov decision processes (MDPs) as the framework for modeling reinforcement learning problems, including states, actions, transitions, and rewards. It discusses solving MDPs by finding optimal policies using value iteration or policy iteration algorithms based on the Bellman equations. The goal is to learn optimal state values or action values through interaction rather than relying on a known model of the environment.