This paper improves the skip-gram model for learning word and phrase embeddings. It proposes using phrases instead of words as training samples, which greatly reduces the number of samples. It also introduces subsampling frequent words to speed up training and improve performance on infrequent words. Further, it compares different methods for reducing computational complexity like hierarchical softmax and negative sampling, finding negative sampling works best. Empirical tests on analogical reasoning tasks show the best model uses hierarchical softmax with subsampling and is trained on billions of words. The paper also demonstrates additive compositionality of word vectors.


![Background
This paper follows the paper [1] Efficient estimation of word representations in
vector space in 2013.
This paper proposed some important improvements for the Skip-gram model,
which is widely used for obtaining the famous “word vectors”. [1] proposed the
CBOW (Continuous Bag-of-words Model) and Skip-gram, using a 3-layer neural
network to train the word-vectors.
While CBOW is entering the context to predict the center, Skip-gram is entering
the center word to predict the context.](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-3-2048.jpg)





![In order to reduce the complexity of calculating the weights of output layer.
Hierarchical Softmax (HS) was used in the Skip-gram model. HS was firstly
proposed by [2] Morin and Bengio (2005).
We will introduce the data structure used in HS: Huffman Tree / Coding. Huffman
tree assigns short codes (path) to the most frequent words, and thus the random
walk on the tree will find these words quickly.
The Hierarchical Softmax](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-9-2048.jpg)
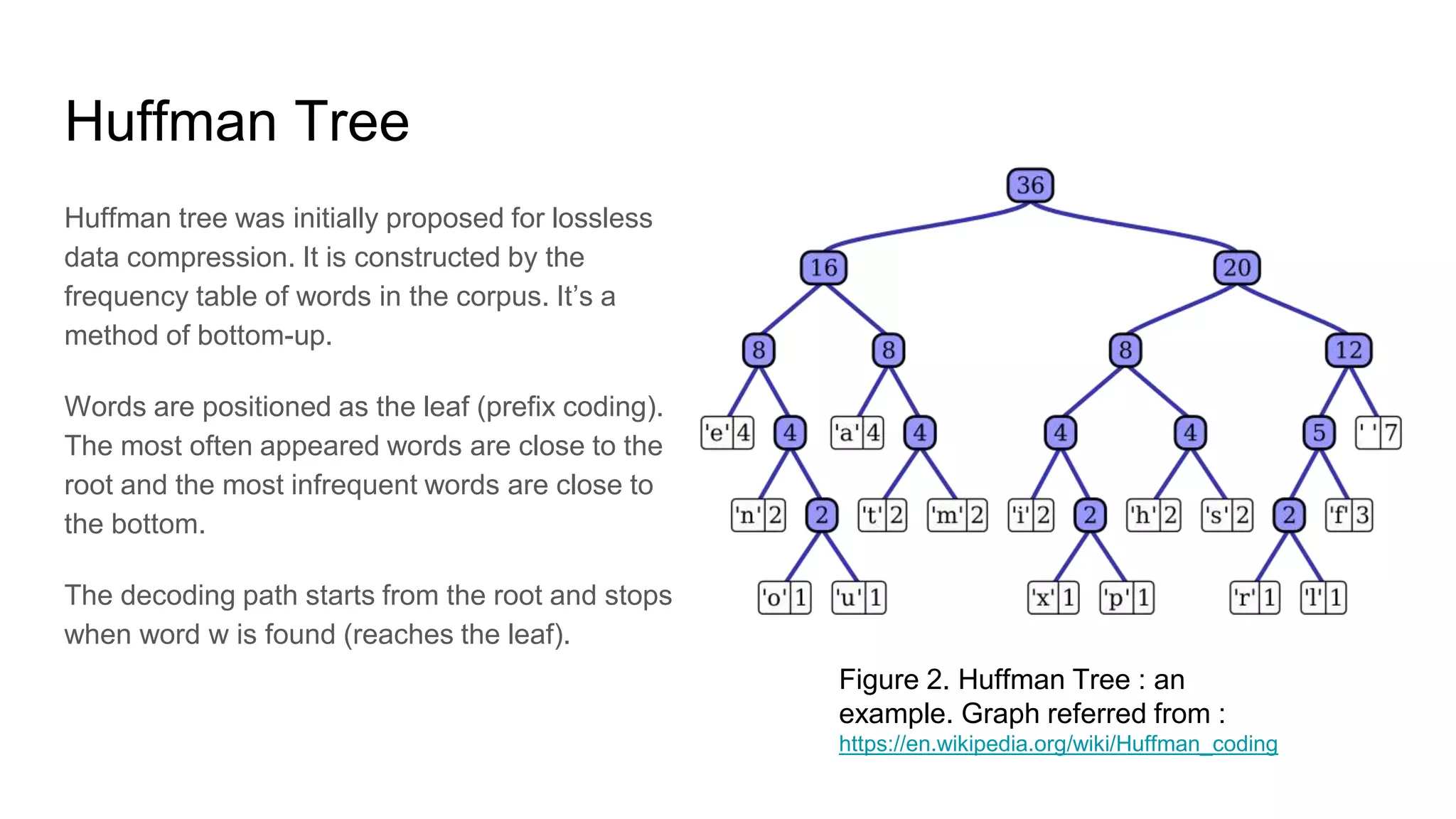

![The number of parameters rest the same yet a binary Huffman Tree reduced the
computation volume to an acceptable level.
Different methods for constructing the tree structure can be found by [3] Mnih and
Hinton (2009).
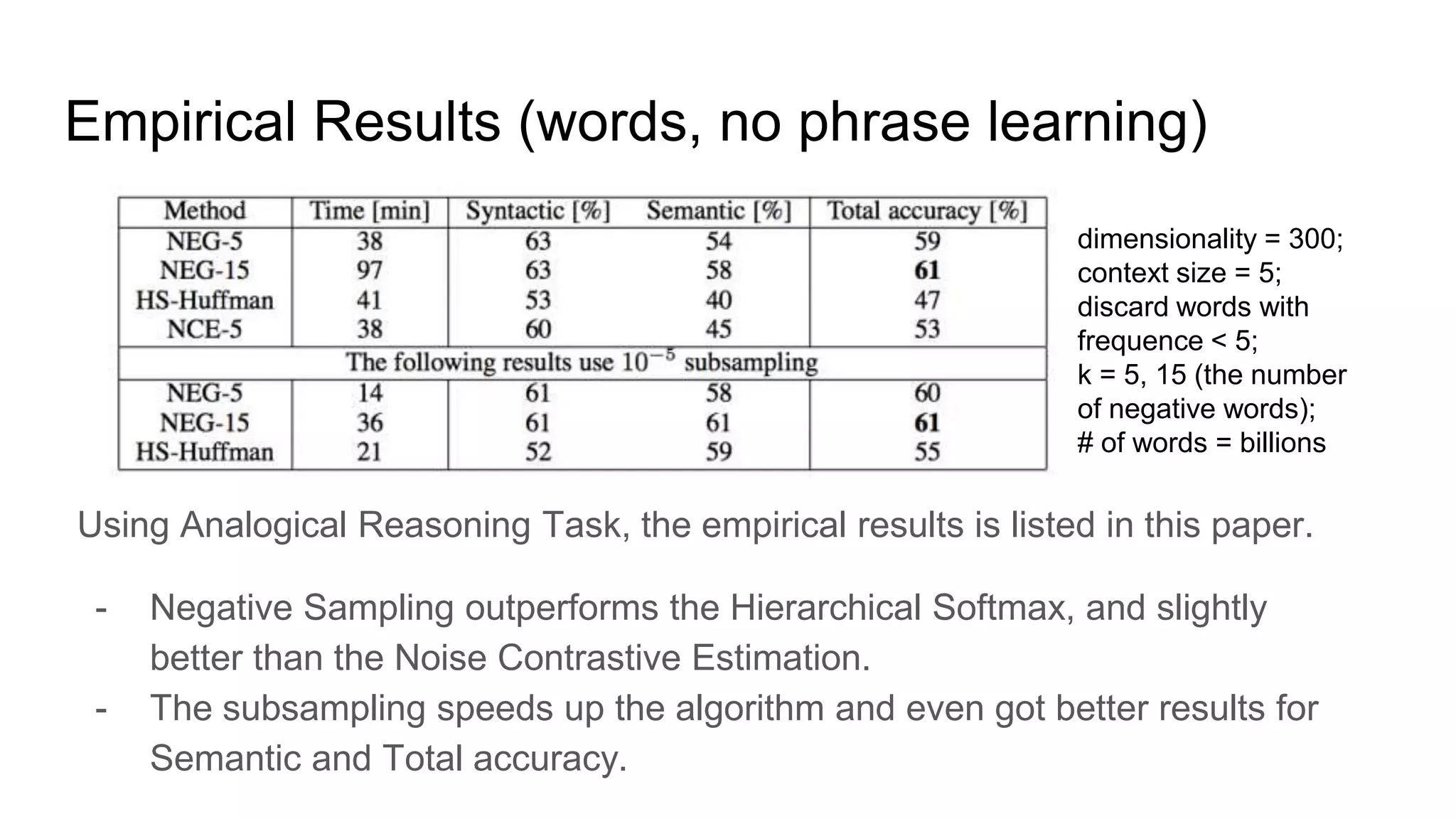
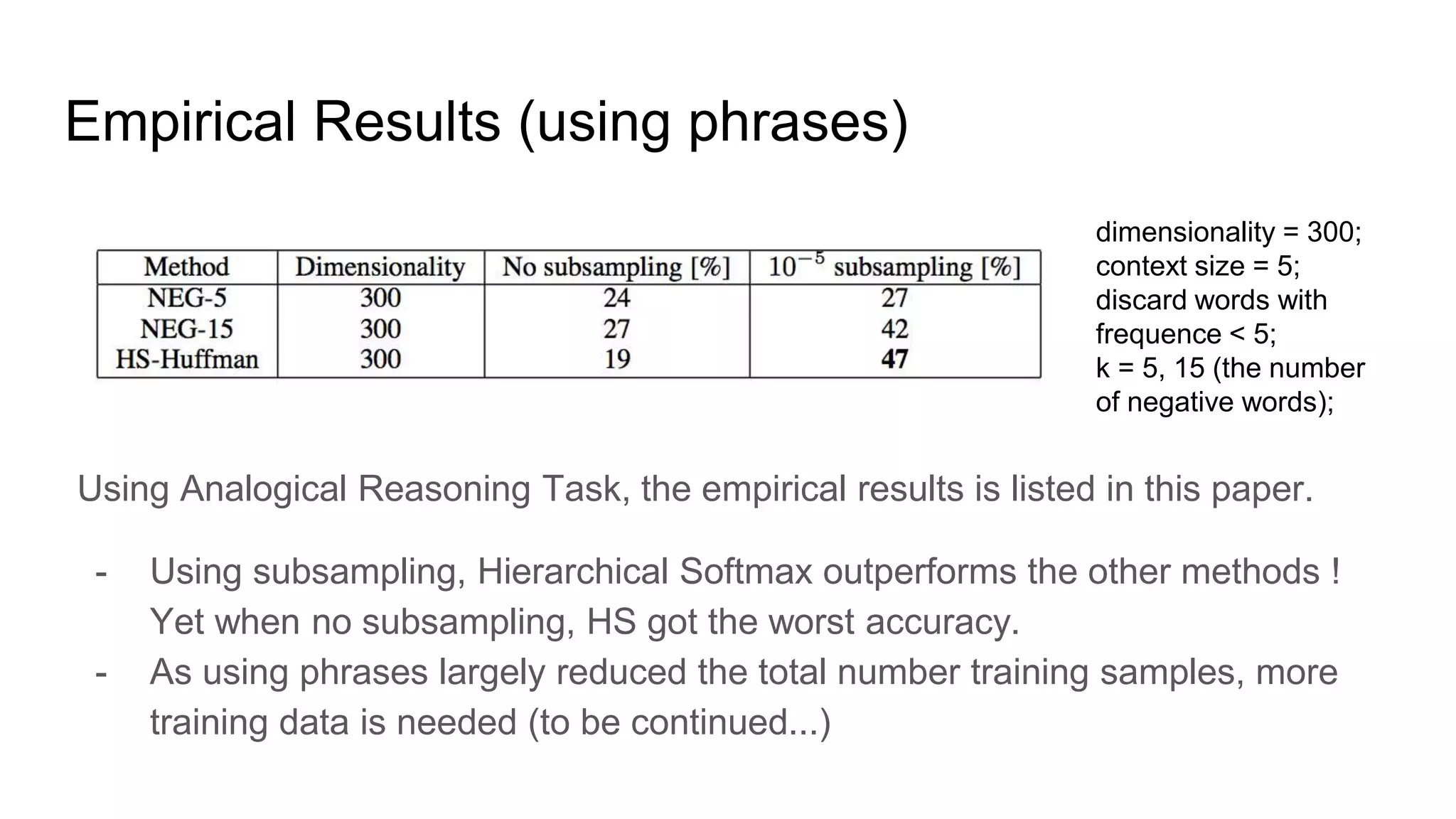
HS was proposed in paper [1] a priori and the performance is not satisfying. This
paper compared the results of Hierarchical Softmax with Negative Sampling, and
also Noise Contrastive Estimation - NCE proposed by [4] Gutmann and
Hyvarinen (2012), together with the subsampling trick and using phrase as
training samples.
Huffman Tree](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-12-2048.jpg)








![Analogical Reasoning Task
An example for analogical reasoning is
as left. Given three phrases, to how
much degree can the fourth phrase be
inferred from the first three phrase-
vectors. By using cosine distance
between the vectors, the closest answer
is selected and compared with the true
answer.
This test method is used also in [1].
Figure 3. Examples for Analogical Reasoning test : In
each cell, given the first three words, test the accuracy
of calculating the fourth.](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-21-2048.jpg)



![Conclusion
This paper mainly has three contributions:
- Using common word pairs (phrase representations) to replace words in the
training model.
- Subsampling the frequent words to largely decrease training time and get
better performance for infrequent words.
- Proposing Negative Sampling
- Comparing different methods’ combination and trained a best model (up-to-
then) on a huge (30 billions words) data set.
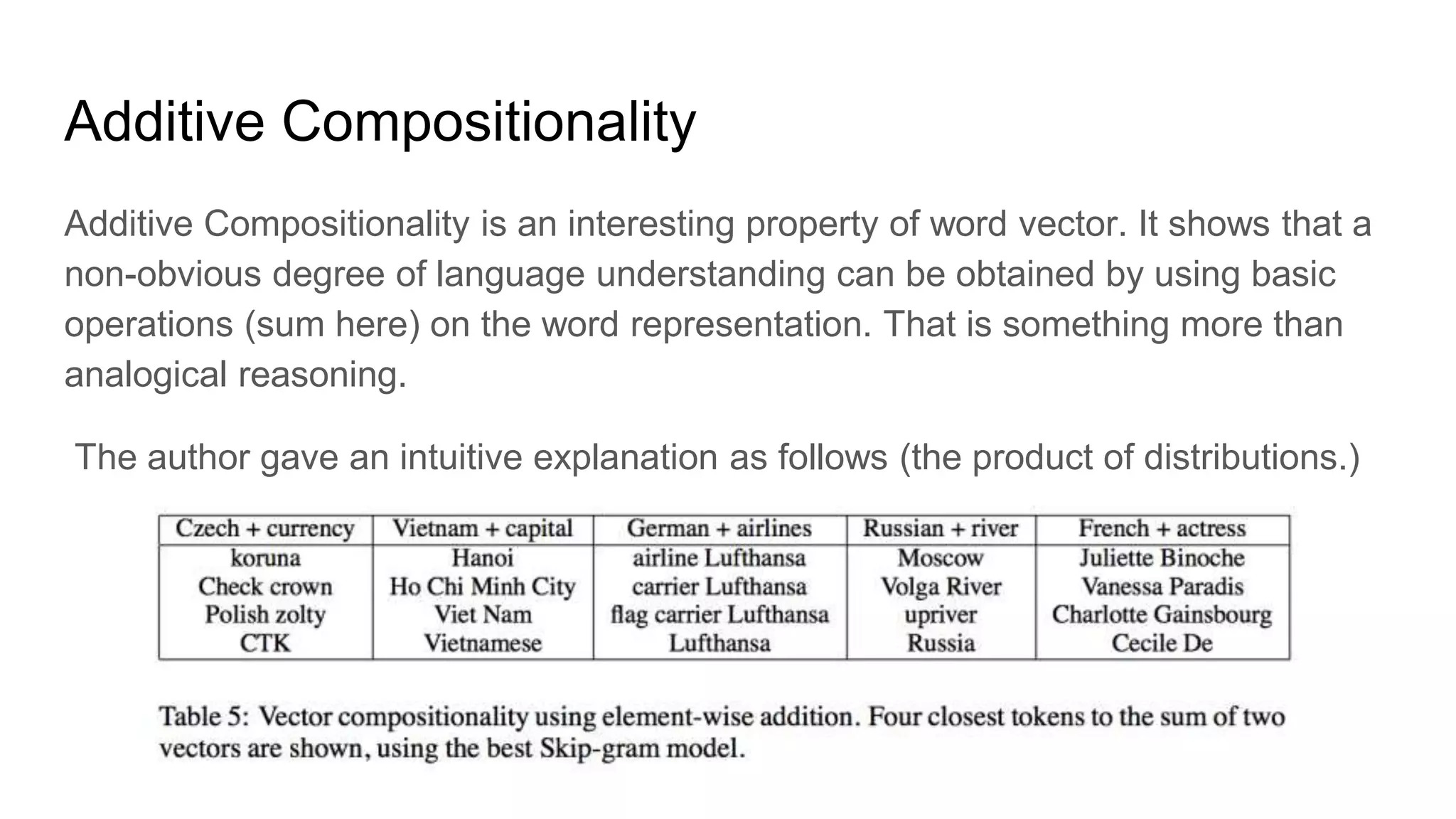
- Addressing the additive compositionality of word vector.
The works of this paper can be further used in CBOW in [1], and the code is given
at https://code.google.com/archive/p/word2vec/](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-28-2048.jpg)
![Referrence
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word
representations in vector space. ICLR Workshop, 2013.
[2] Frederic Morin and Yoshua Bengio. Hierarchical probabilistic neural network language model. In Pro-
ceedings of the international workshop on artificial intelligence and statistics, pages 246–252, 2005.
[3] Andriy Mnih and Geoffrey E Hinton. A scalable hierarchical distributed language model. Advances in
neural information processing systems, 21:1081–1088, 2009.
[4] Michael U Gutmann and Aapo Hyva ̈rinen. Noise-contrastive estimation of unnormalized statistical
mod- els, with applications to natural image statistics. The Journal of Machine Learning Research,
13:307–361, 2012.](https://image.slidesharecdn.com/summarydistributedrepresentationswordsphrases-180308235944/75/Summary-distributed-representations_words_phrases-29-2048.jpg)

















































![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
