




















































![/driverAcceptanceRate?
geo_dist(10, [37, 22])&
time_range(2015-02-04,2015-03-06)&
aggregate(timeseries(7d))&
eq(msg.driverId,1)](https://image.slidesharecdn.com/qcon-london-stonse-2016-160316180149/85/Stream-Computing-Analytics-at-Uber-73-320.jpg)





































![/driverAcceptanceRate?
geo_dist(10, [37, 22])&
time_range(2015-02-04,2015-03-06)&
aggregate(timeseries(7d))&
eq(msg.driverId,1)](https://image.slidesharecdn.com/qcon-london-stonse-2016-160316180149/85/Stream-Computing-Analytics-at-Uber-119-320.jpg)


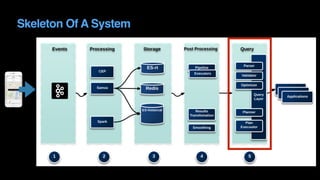

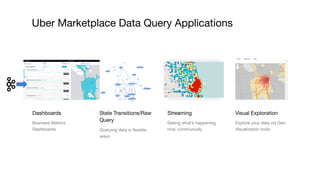
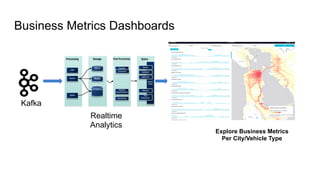
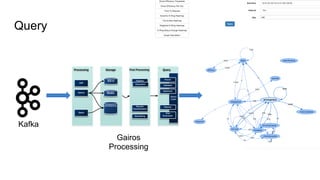
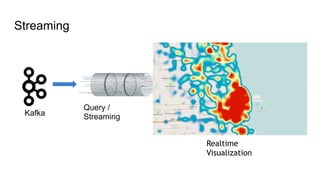
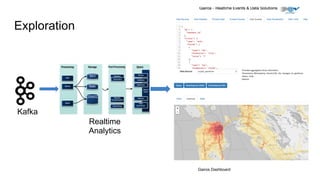

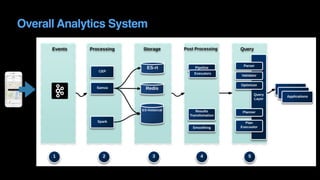
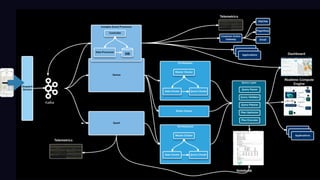

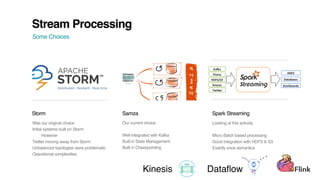





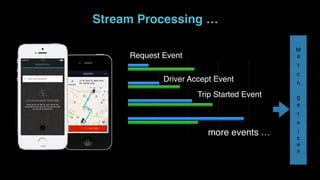
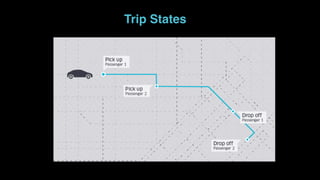
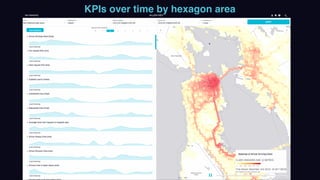
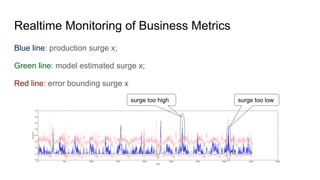
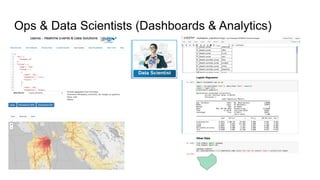
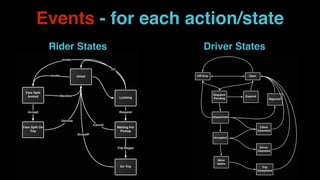
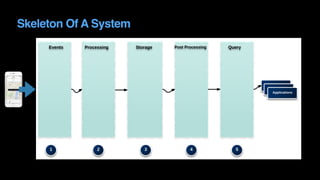
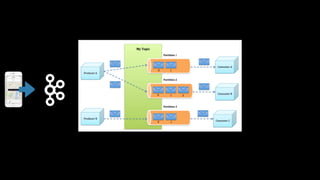
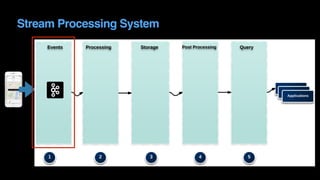
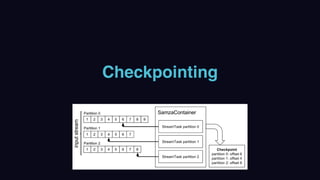
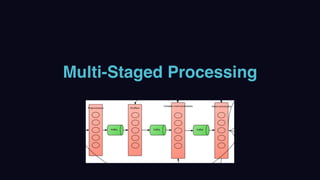
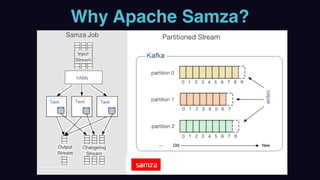
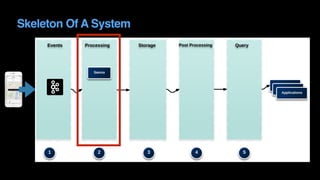
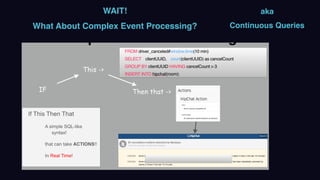
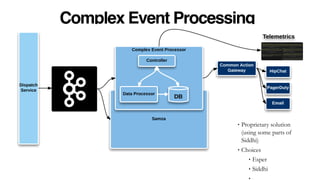
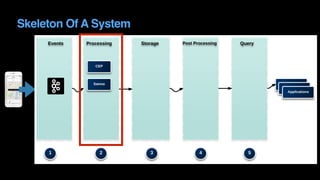
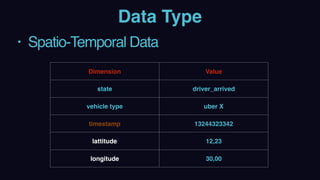
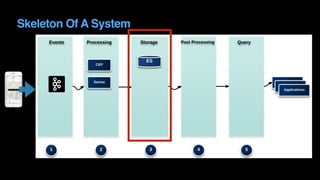
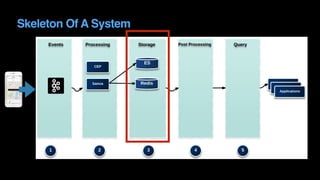
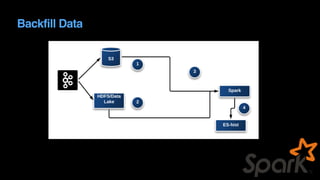
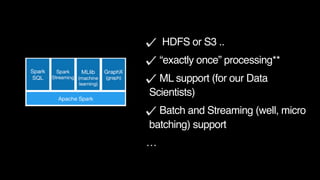
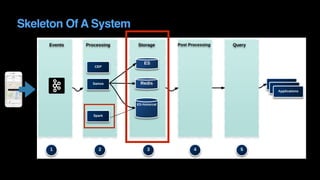
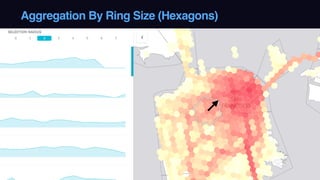
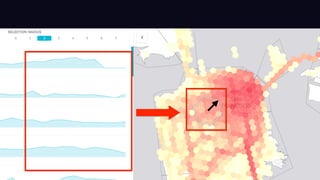
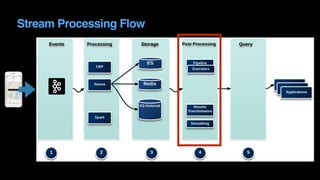
The document outlines Uber's approach to stream computing and analytics, detailing the architecture and use cases for processing real-time data related to transportation dynamics. It discusses challenges in handling large-scale, spatio-temporal data, and the technologies used such as Apache Kafka and Samza for efficient event processing and analytics. Finally, it highlights choices made regarding analytics systems and tools for data visualization and monitoring at Uber.















































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)


















