Download as PDF, PPTX




![Sources
Liyin Tang and Jingwei Lu
8
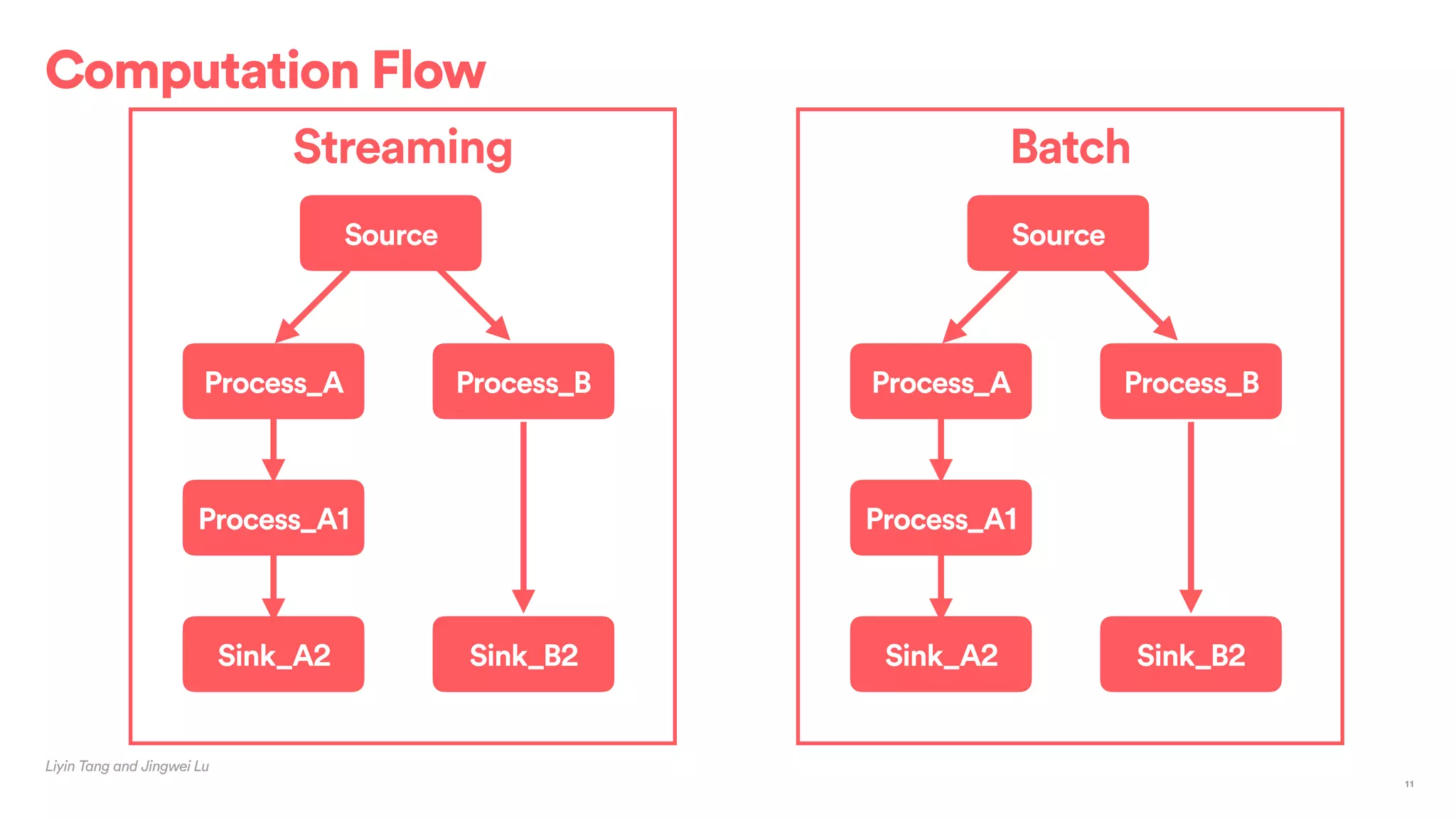
Streaming
source: [
{
name: source_example,
type: kafka,
config: {
topic: "example_topic",
}
}
]
Batch
source: [
{
name: source_example,
type: hive,
sql: {
select * from db.table where
ds=‘2017-06-05’;
}
}
]](https://image.slidesharecdn.com/034lutang-170614011240/75/Building-Data-Product-Based-on-Apache-Spark-at-Airbnb-with-Jingwei-Lu-and-Liyin-Tang-8-2048.jpg)
![Computation
Liyin Tang and Jingwei Lu
9
Streaming/Batch
process: [{
name = process_example,
type = sql,
sql = """
SELECT listing_id, checkin_date, context.source as source
FROM source_example
WHERE user_id IS NOT NULL """
}]](https://image.slidesharecdn.com/034lutang-170614011240/75/Building-Data-Product-Based-on-Apache-Spark-at-Airbnb-with-Jingwei-Lu-and-Liyin-Tang-9-2048.jpg)
![Sinks
Liyin Tang and Jingwei Lu
10
Streaming
sink: [
{
name = sink_example
input = process_example
type = hbase_update
hbase_table_name = test_table
bulk_upload = false
}
]
Batch
sink: [
{
name = sink_example
input = process_example
type = hbase_update
hbase_table_name = test_table
bulk_upload = true
}
]](https://image.slidesharecdn.com/034lutang-170614011240/75/Building-Data-Product-Based-on-Apache-Spark-at-Airbnb-with-Jingwei-Lu-and-Liyin-Tang-10-2048.jpg)



![Unified Write API
Liyin Tang and Jingwei Lu
16
DataFrame
HBase
Region 1
Region 2
Region N
Re-partition
<Region 1, [RowKey, Value]>
<Region 2, [RowKey, Value]>
<Region N, [RowKey, Value]>
… …
Puts
HFile
BulkLoad](https://image.slidesharecdn.com/034lutang-170614011240/75/Building-Data-Product-Based-on-Apache-Spark-at-Airbnb-with-Jingwei-Lu-and-Liyin-Tang-16-2048.jpg)
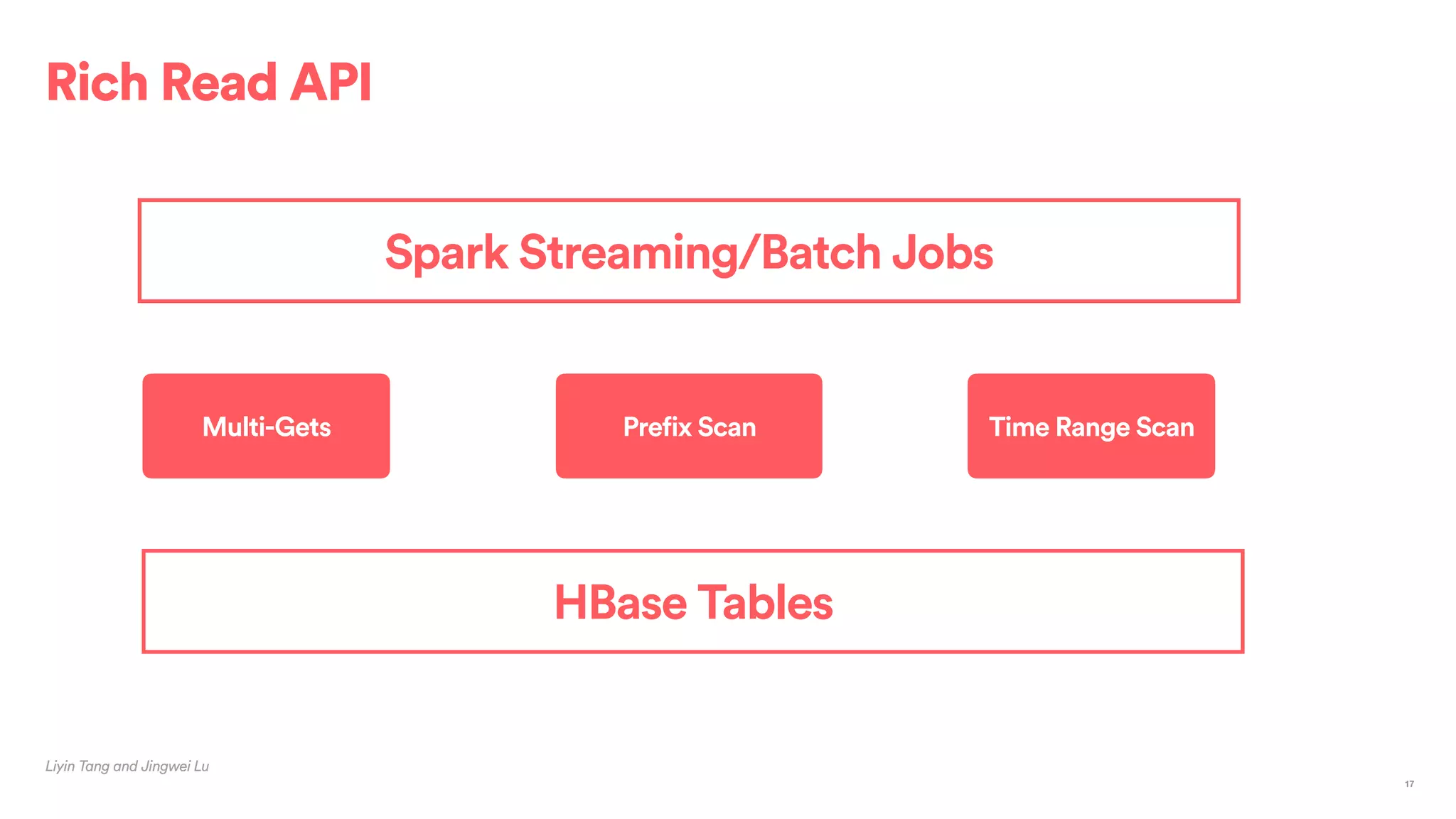
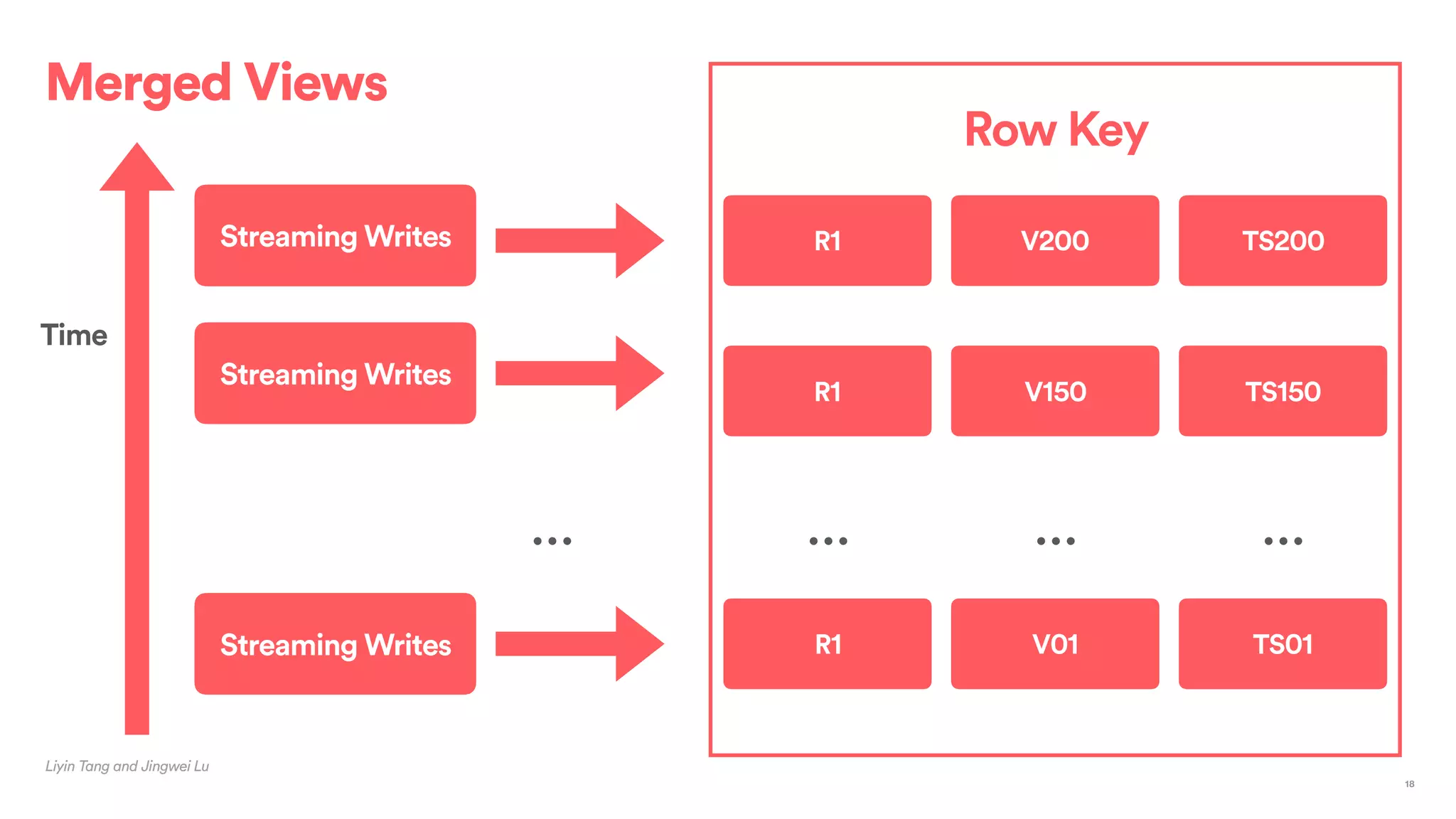
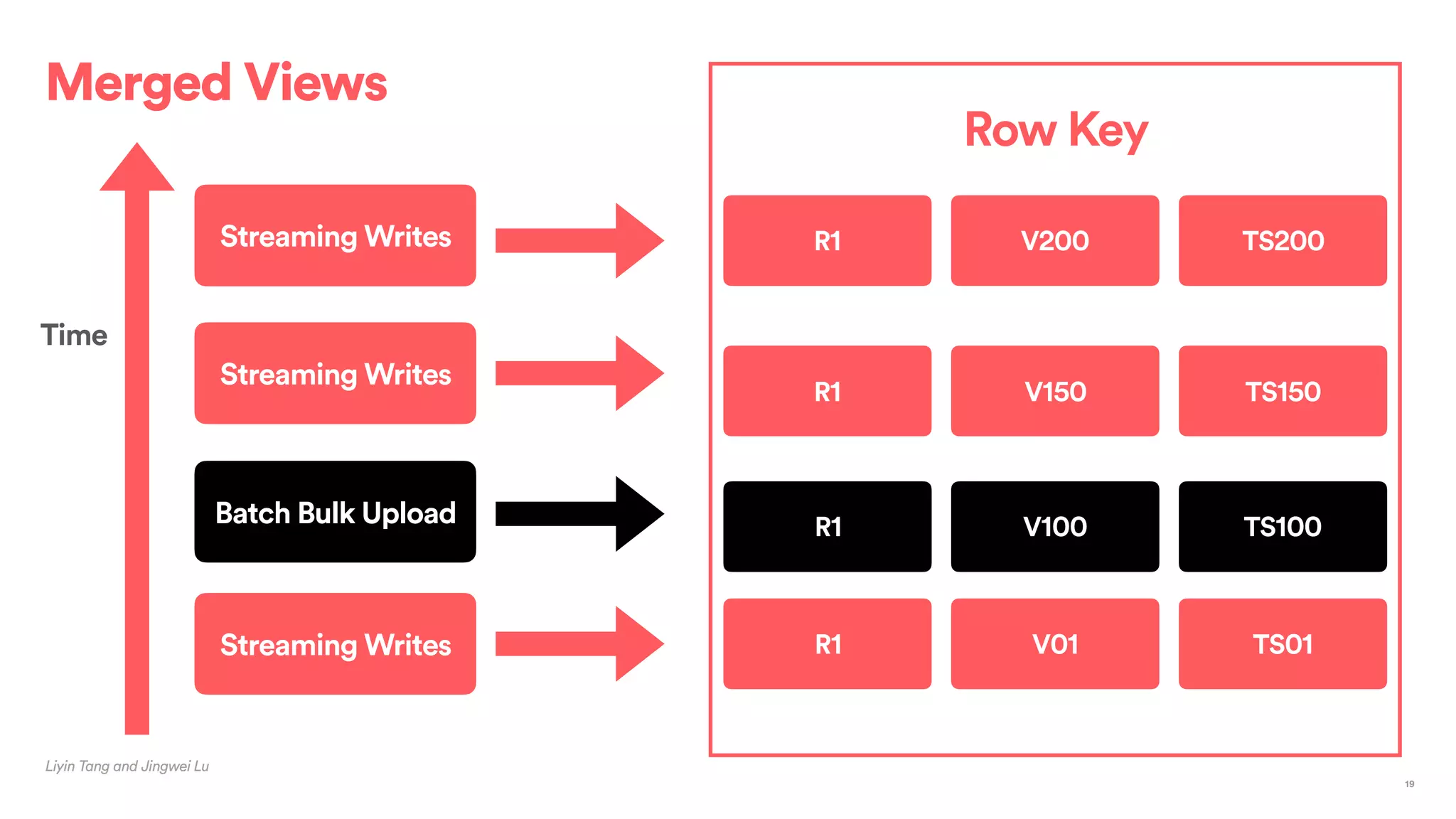





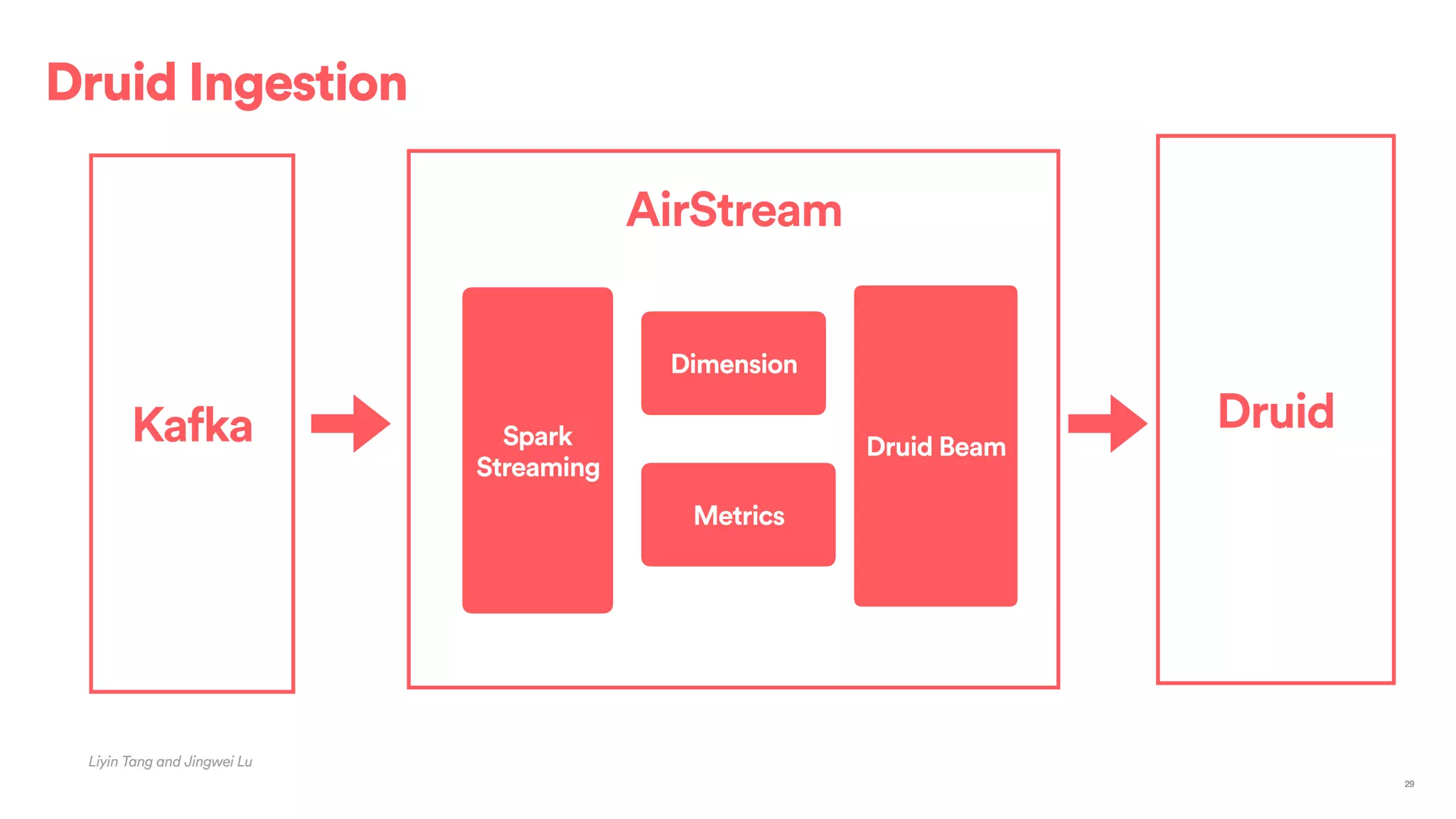


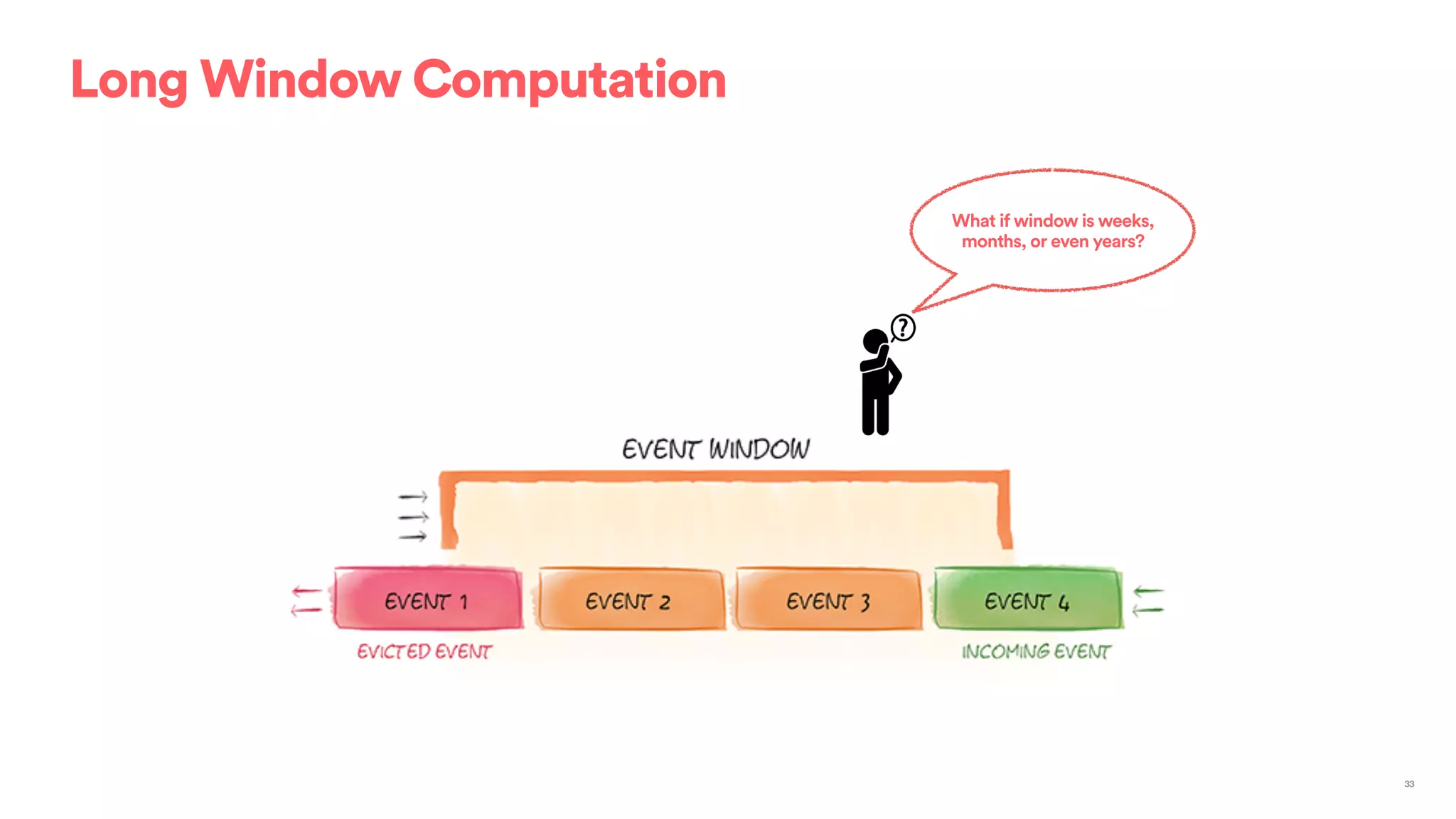
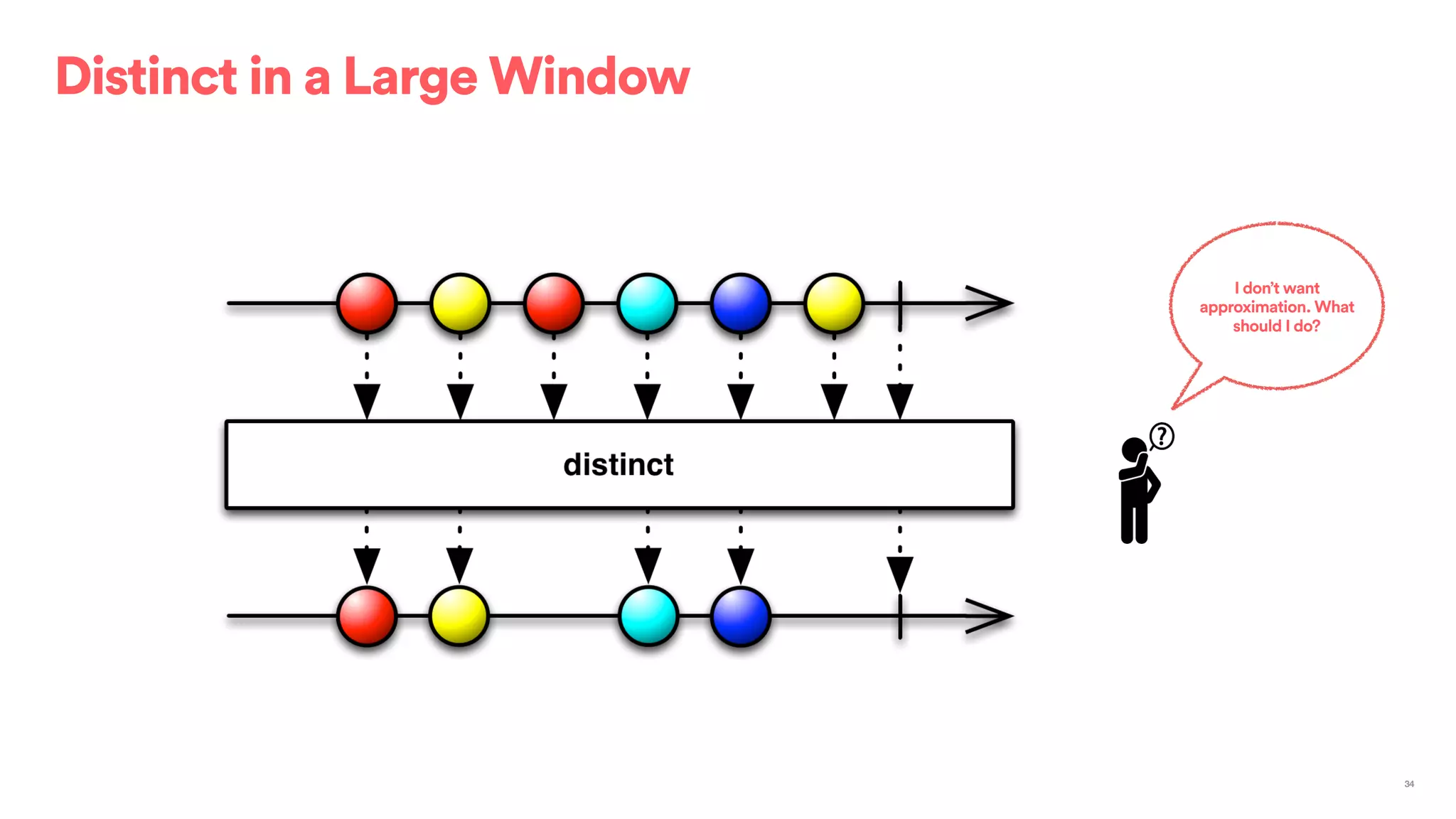
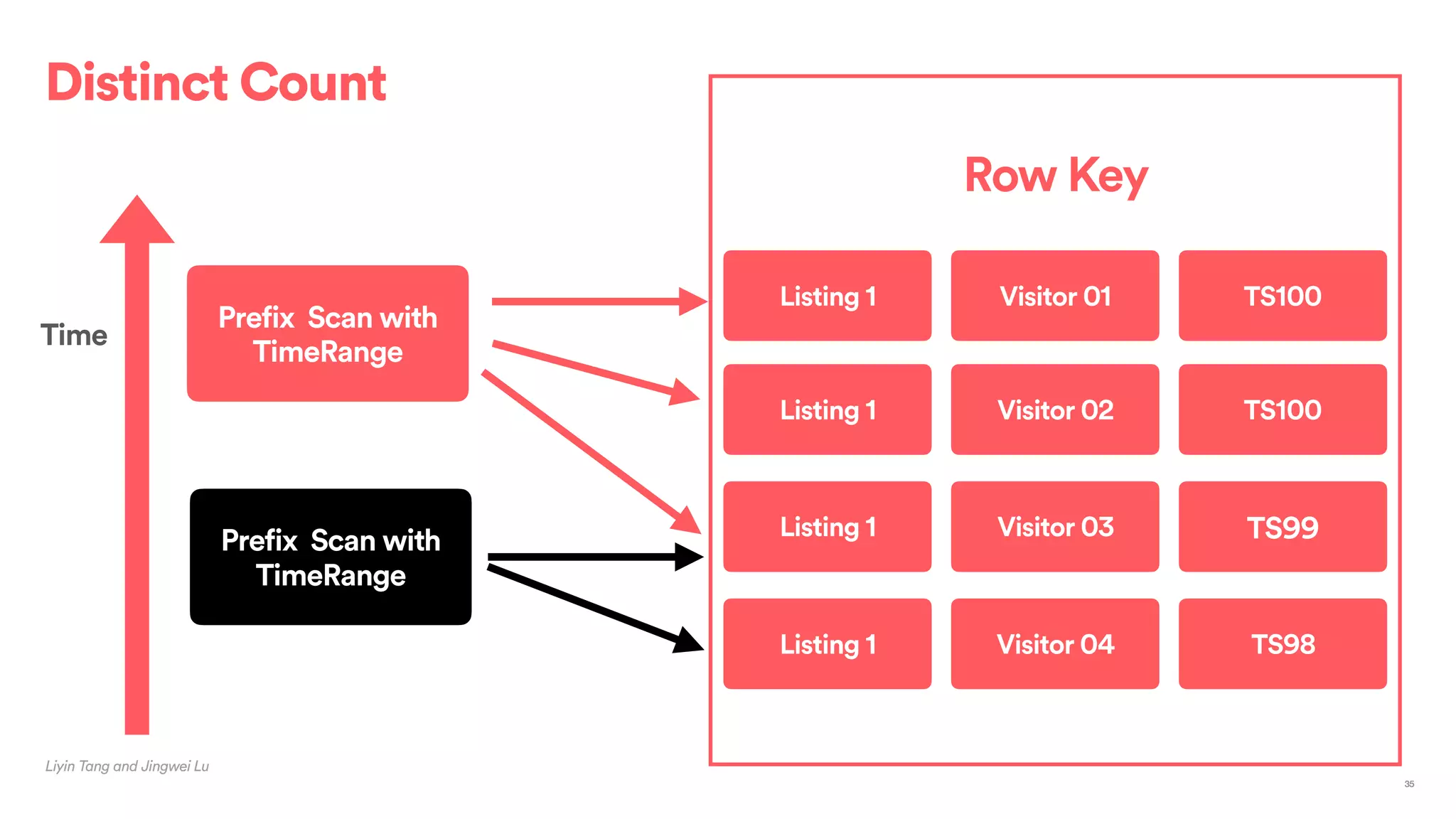
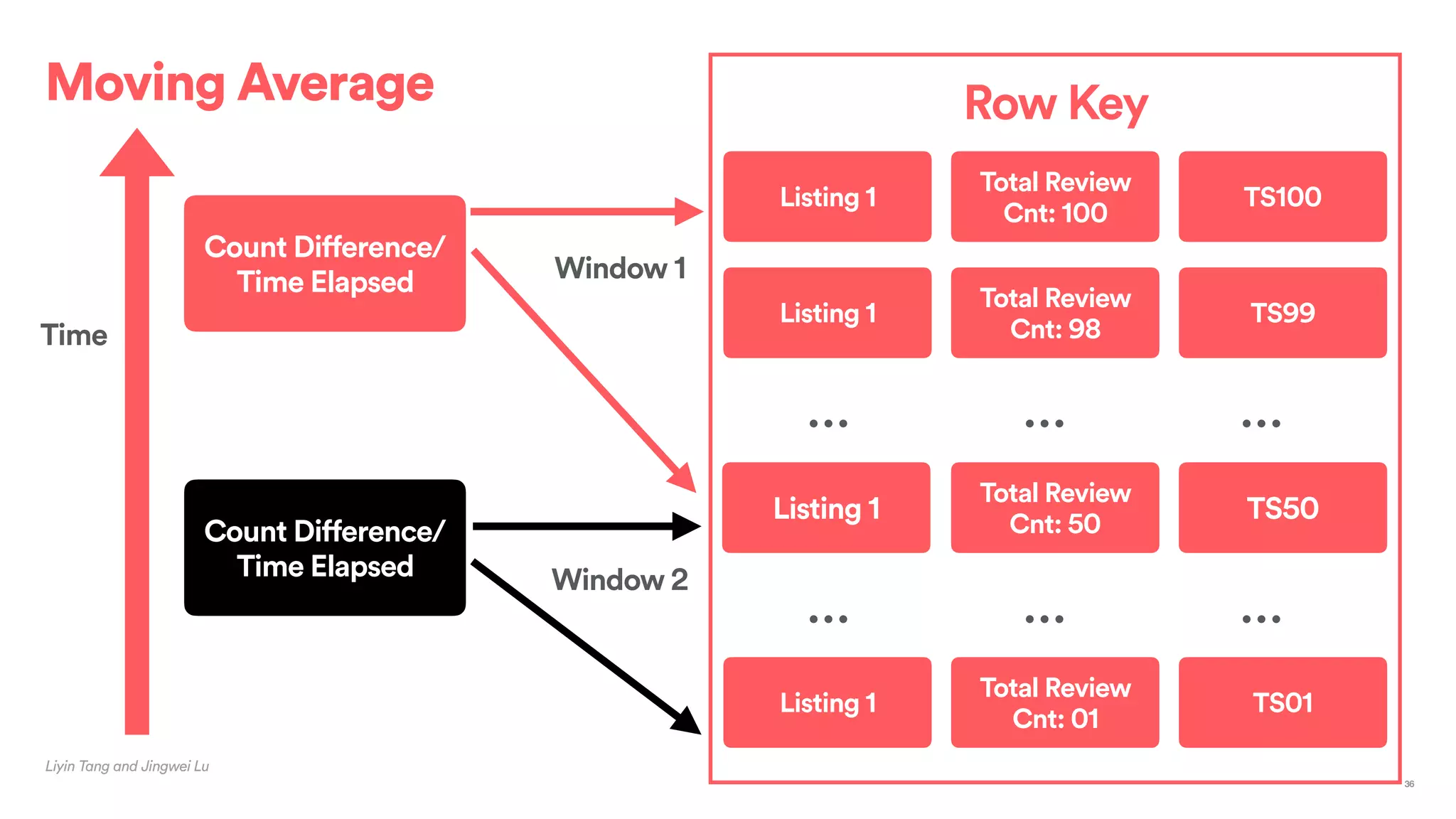

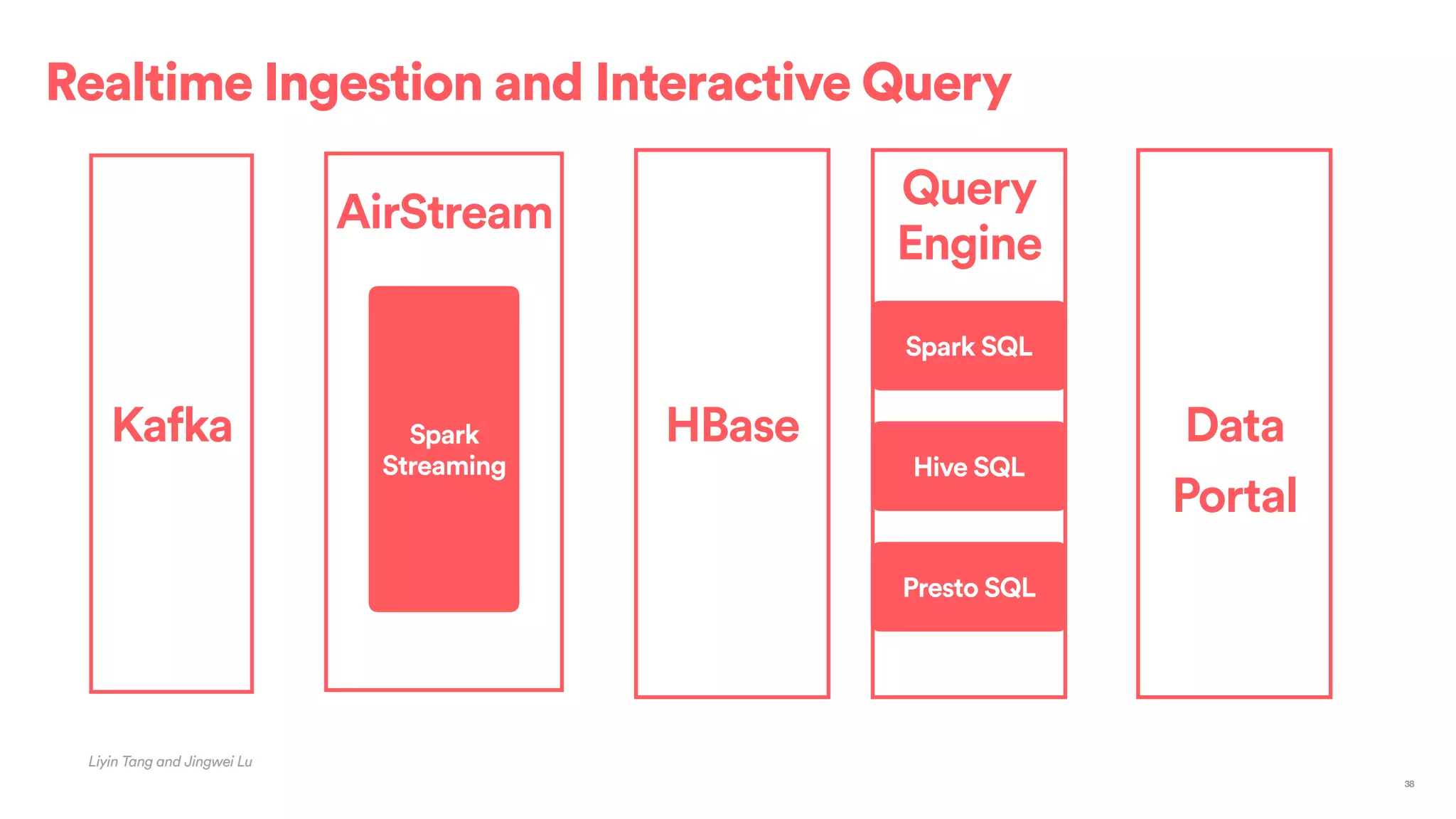

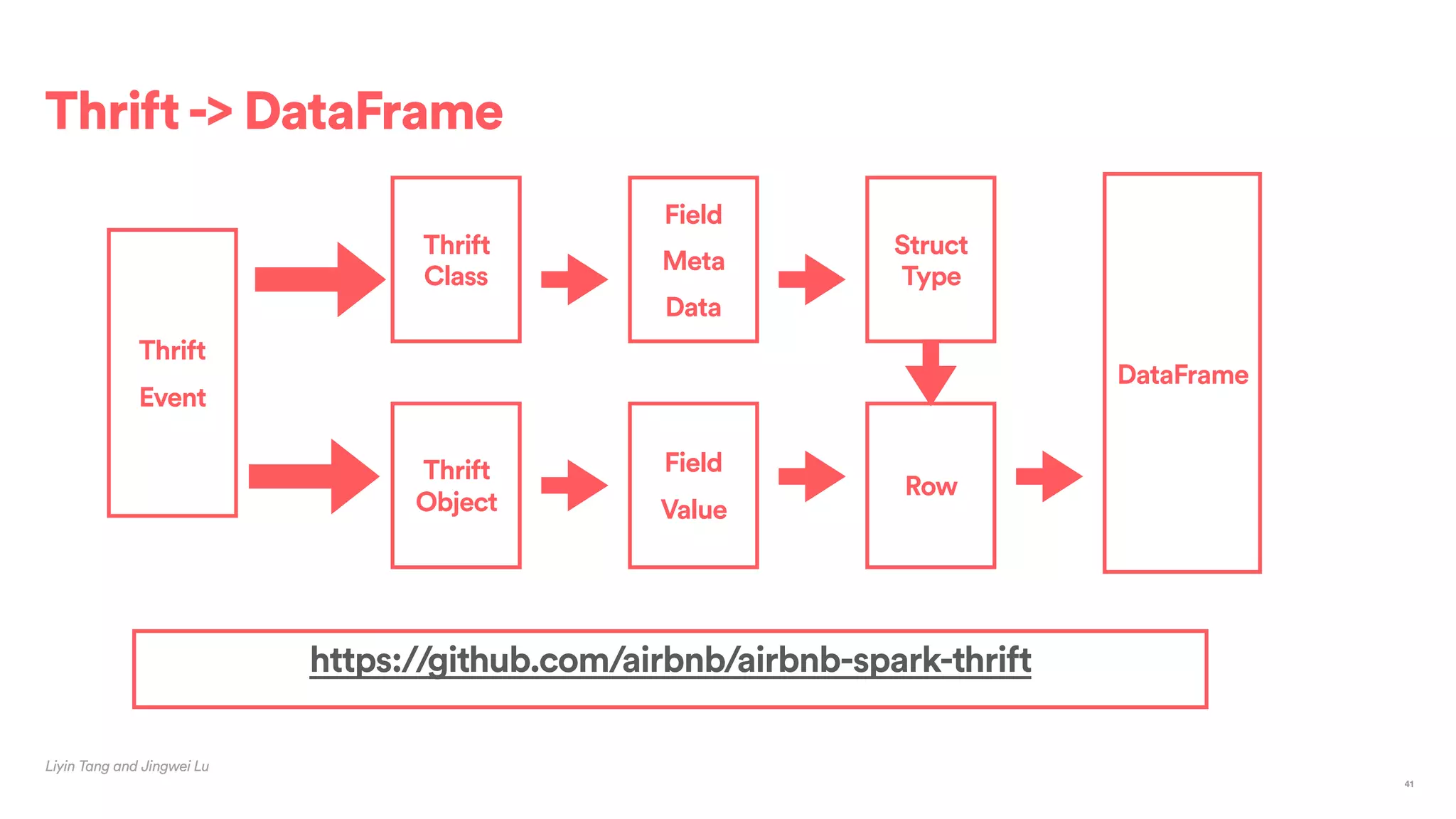





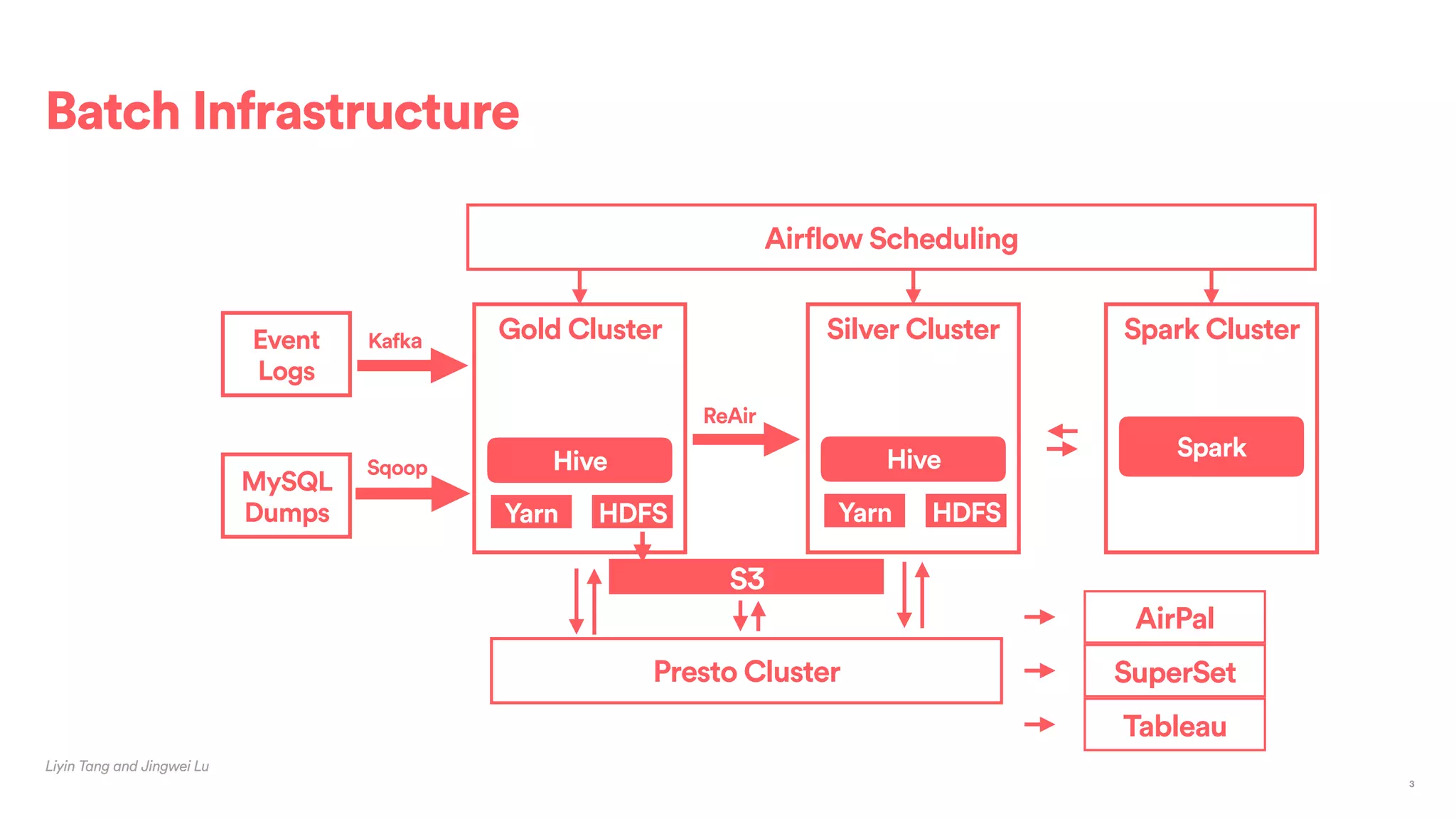
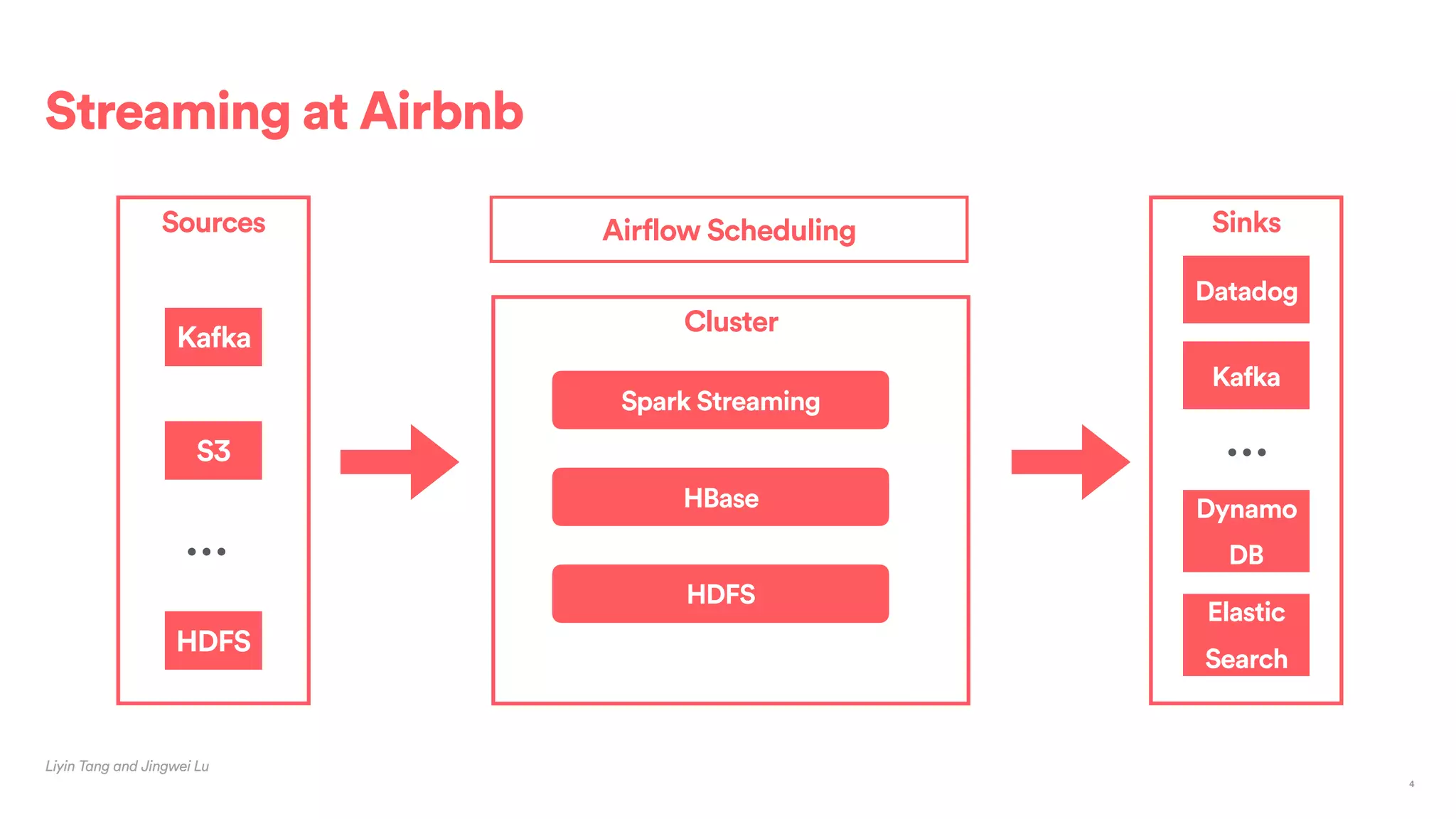
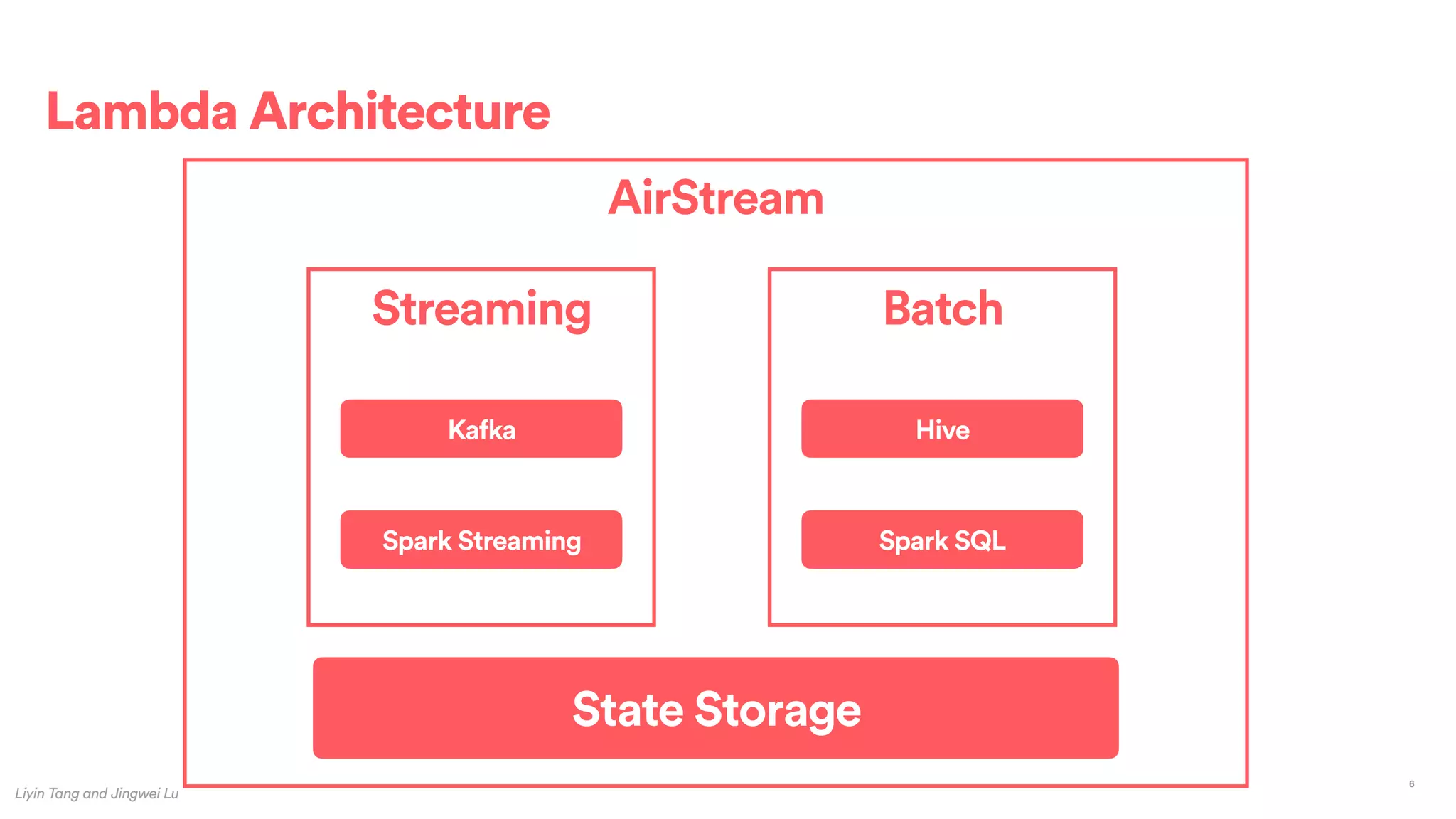
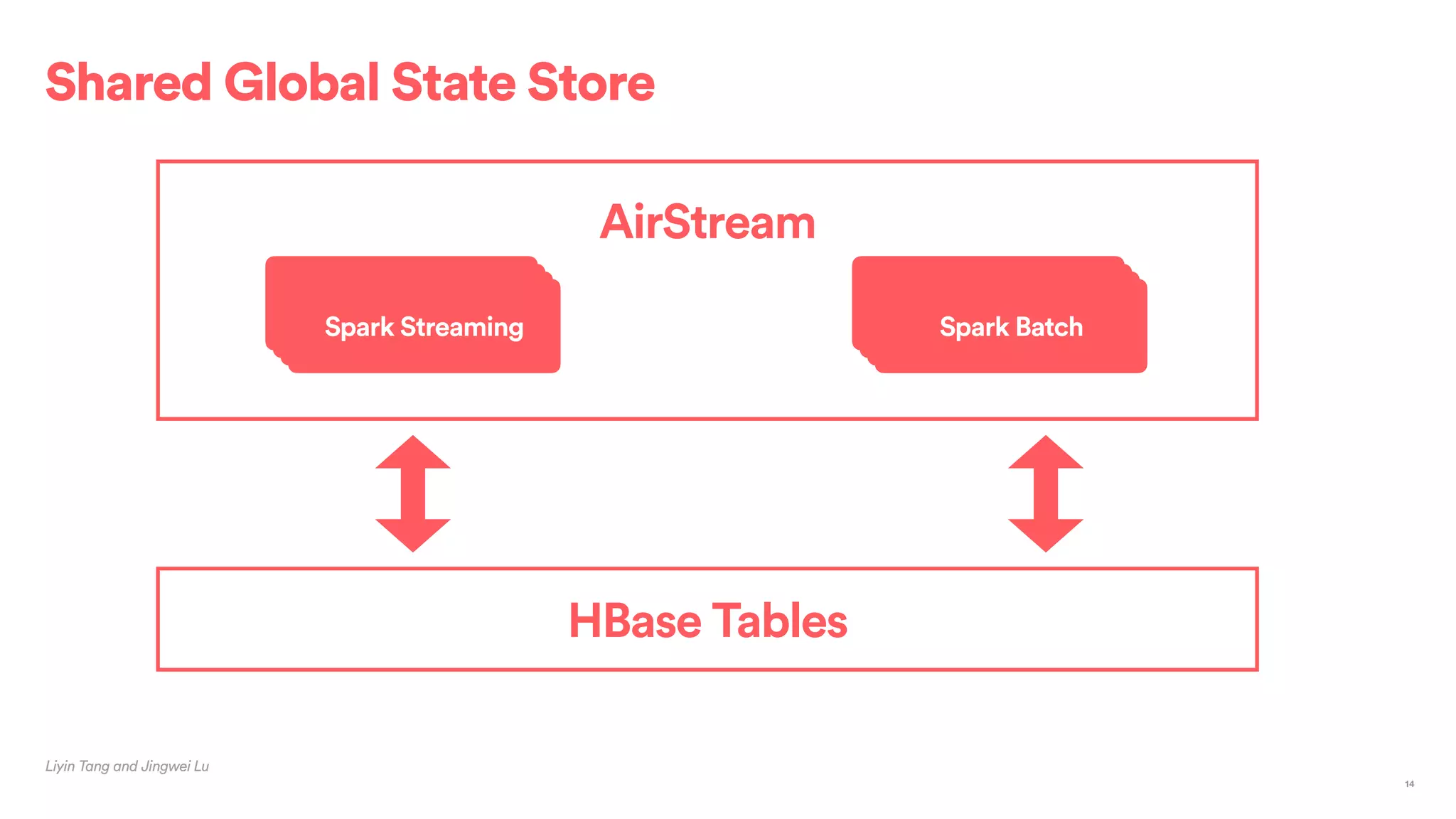
The document outlines Airbnb's approach to building data products using Spark, highlighting their data infrastructure that integrates both streaming and batch processing. It describes the architecture, data sources, computation flows, and technology used, including HBase, Kafka, and various query engines. Key features include a unified API for processing and a shared global state store, enabling efficient data handling across multiple use cases.







































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


