Download to read offline



![Specifications
• Virtual session on event detection
• Query other signals in context of the session
• Supports TTL on the dependency signal
Deduplication
• Identify and discard duplicates
• Useful to avoid triggering duplicate notifications
• Provide TTL for deduplication at ms granularity
Sessions
"dedup": true,
"dedup_ttl_ms": 86400000
"query" : "select `id`, `range_threshold`, `pet_mode_status`from stream
where `range_threshold` = 'VEHICLE_RANGE_CRITICALLY_LOW'",
…
"dependency": {
"type": "thermal",
"subtype": "hvac_settings",
"signal": "pet_mode_status",
"values": ["On"]
},](https://image.slidesharecdn.com/pramodimmaneni-realtimeanalytics-231129101509-4494cb76/75/DSC-Europe-23-Pramod-Immaneni-Real-time-analytics-at-IoT-scale-13-2048.jpg)

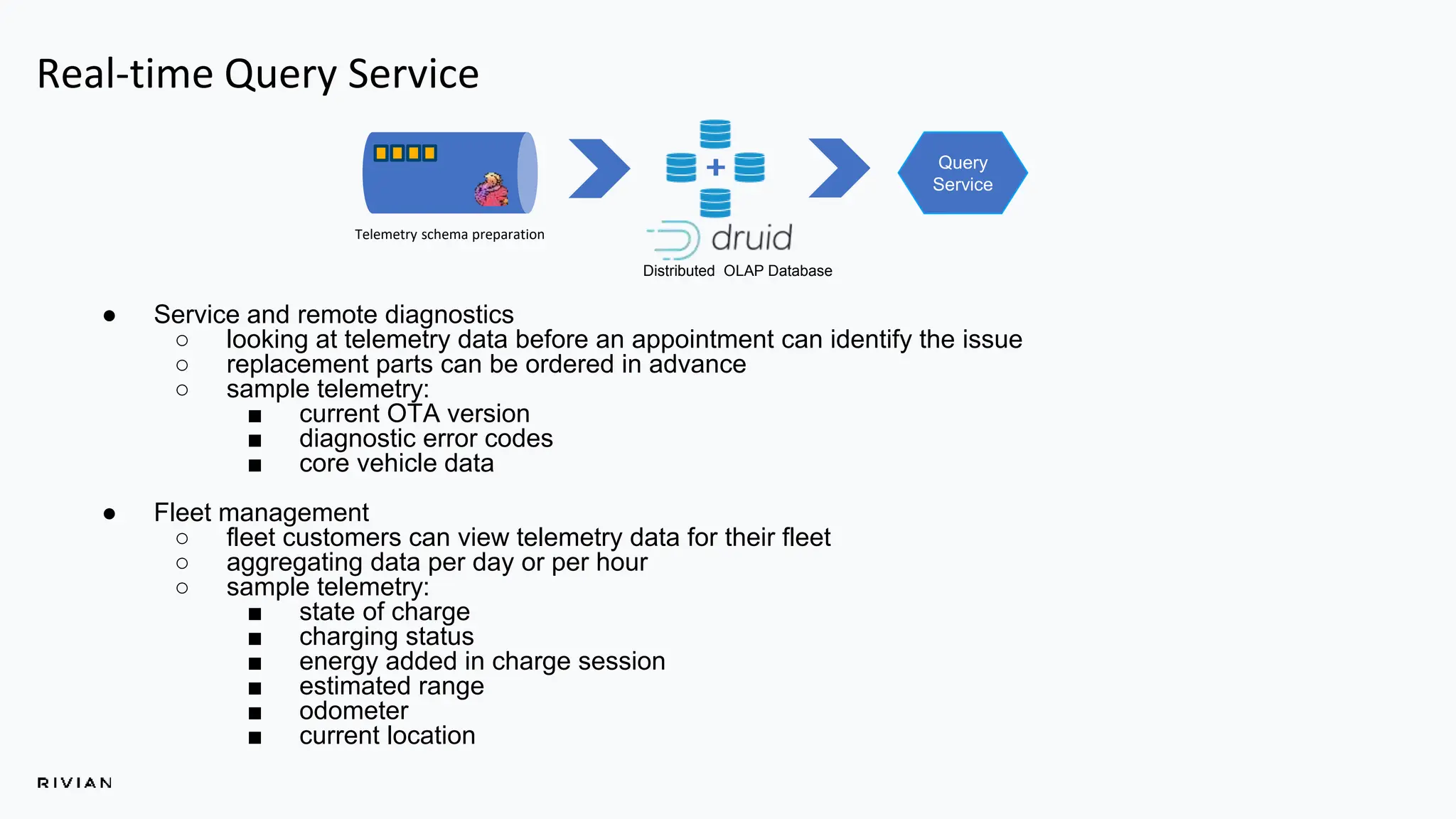
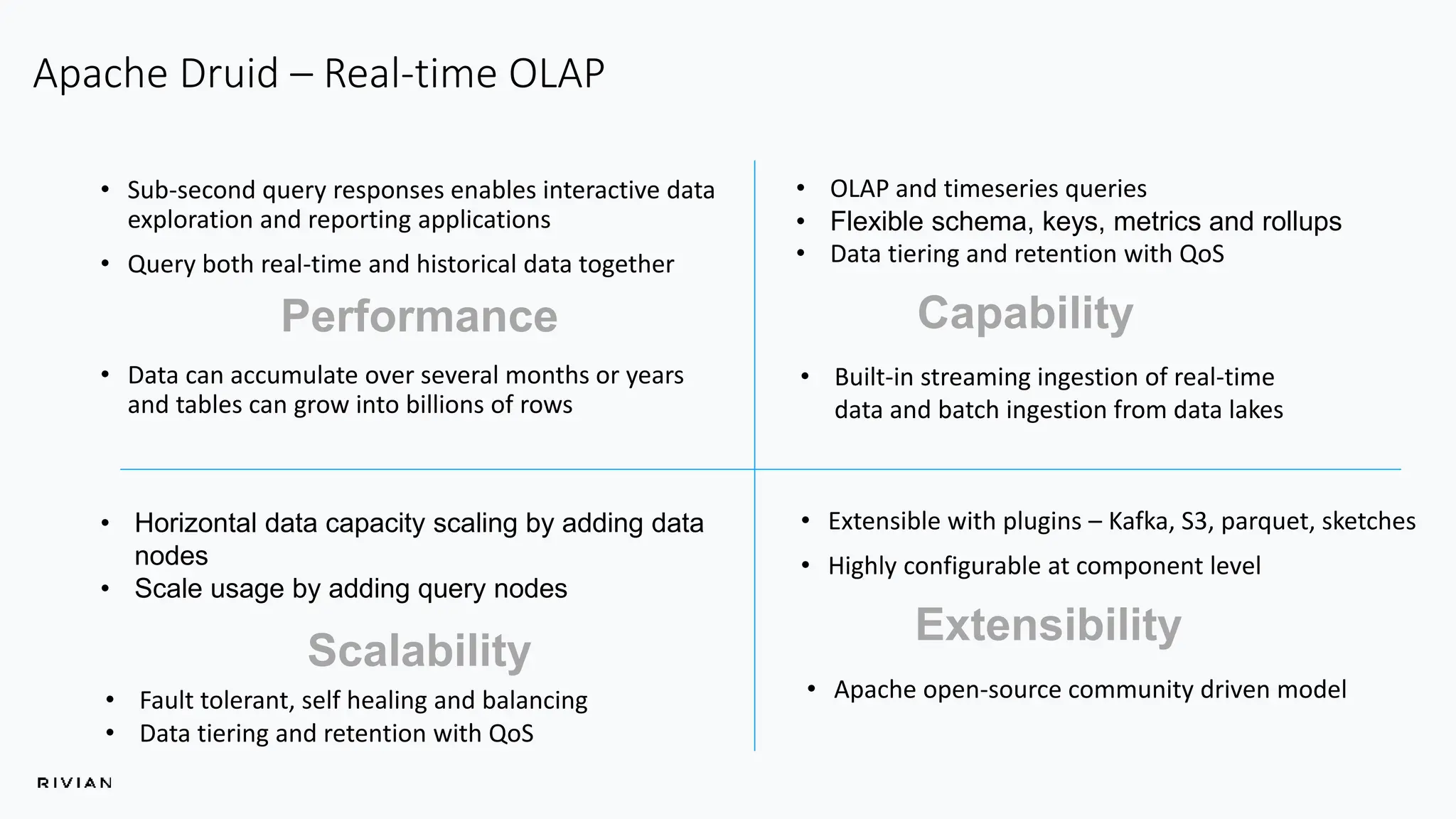
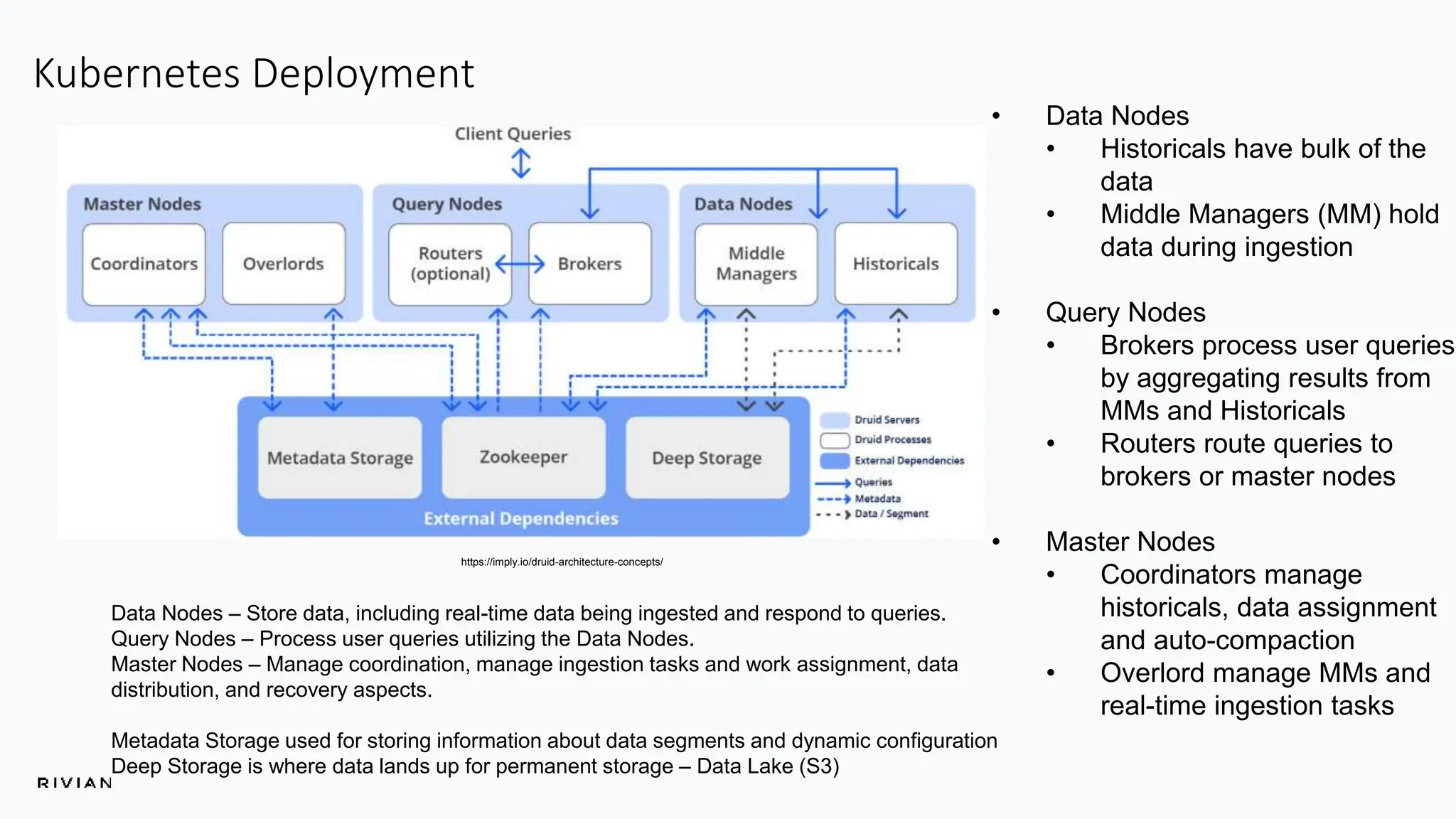
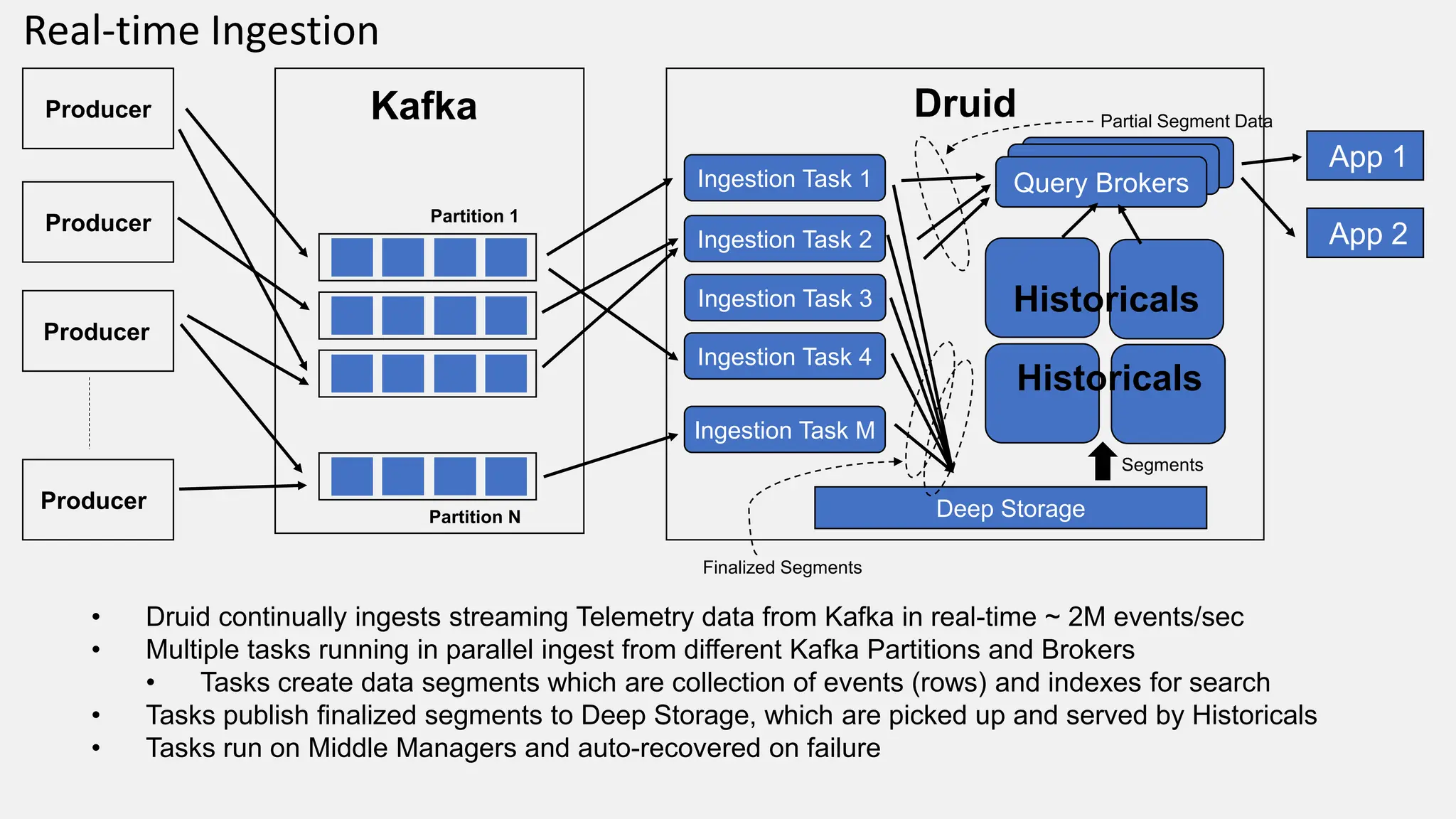


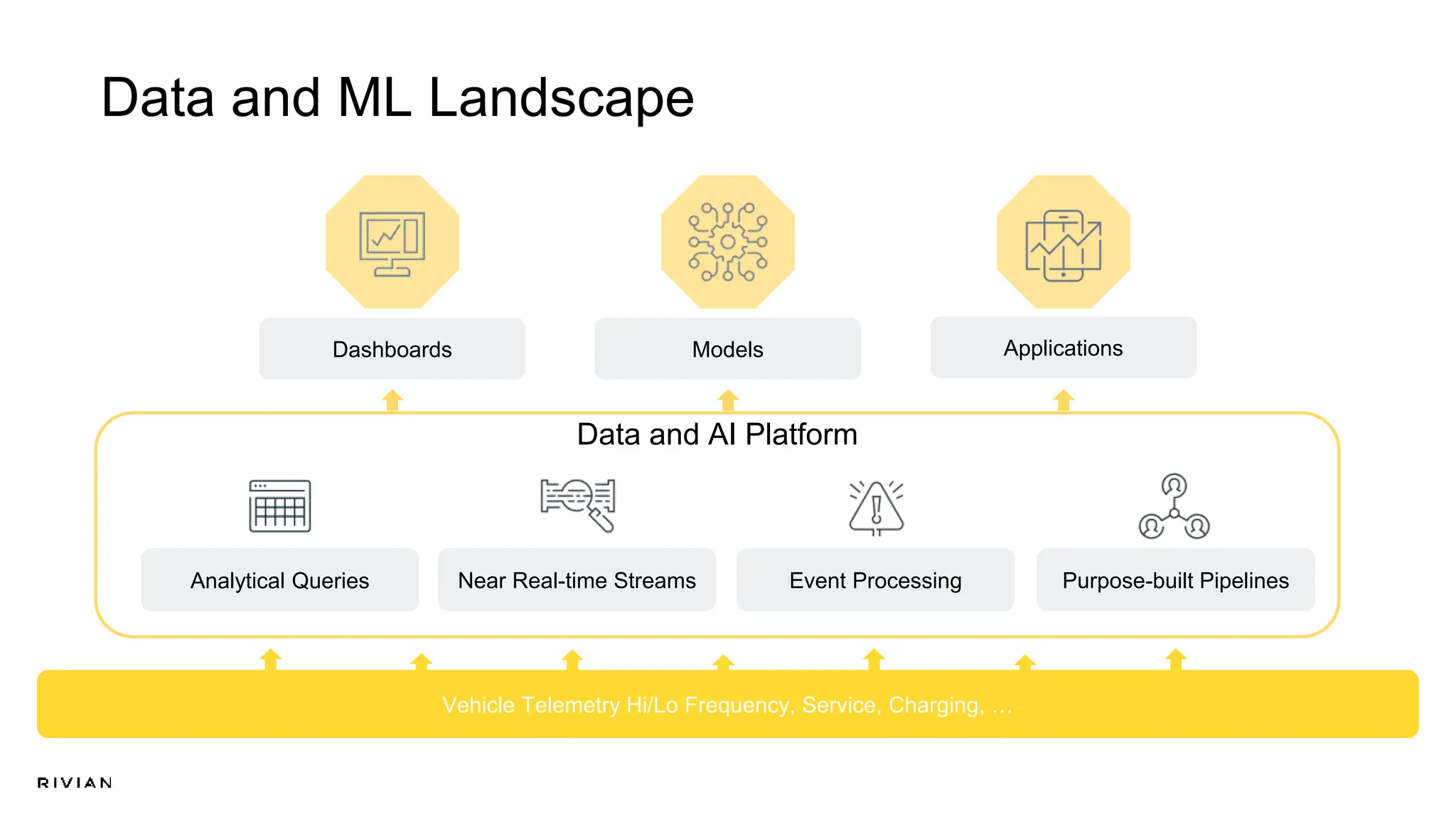
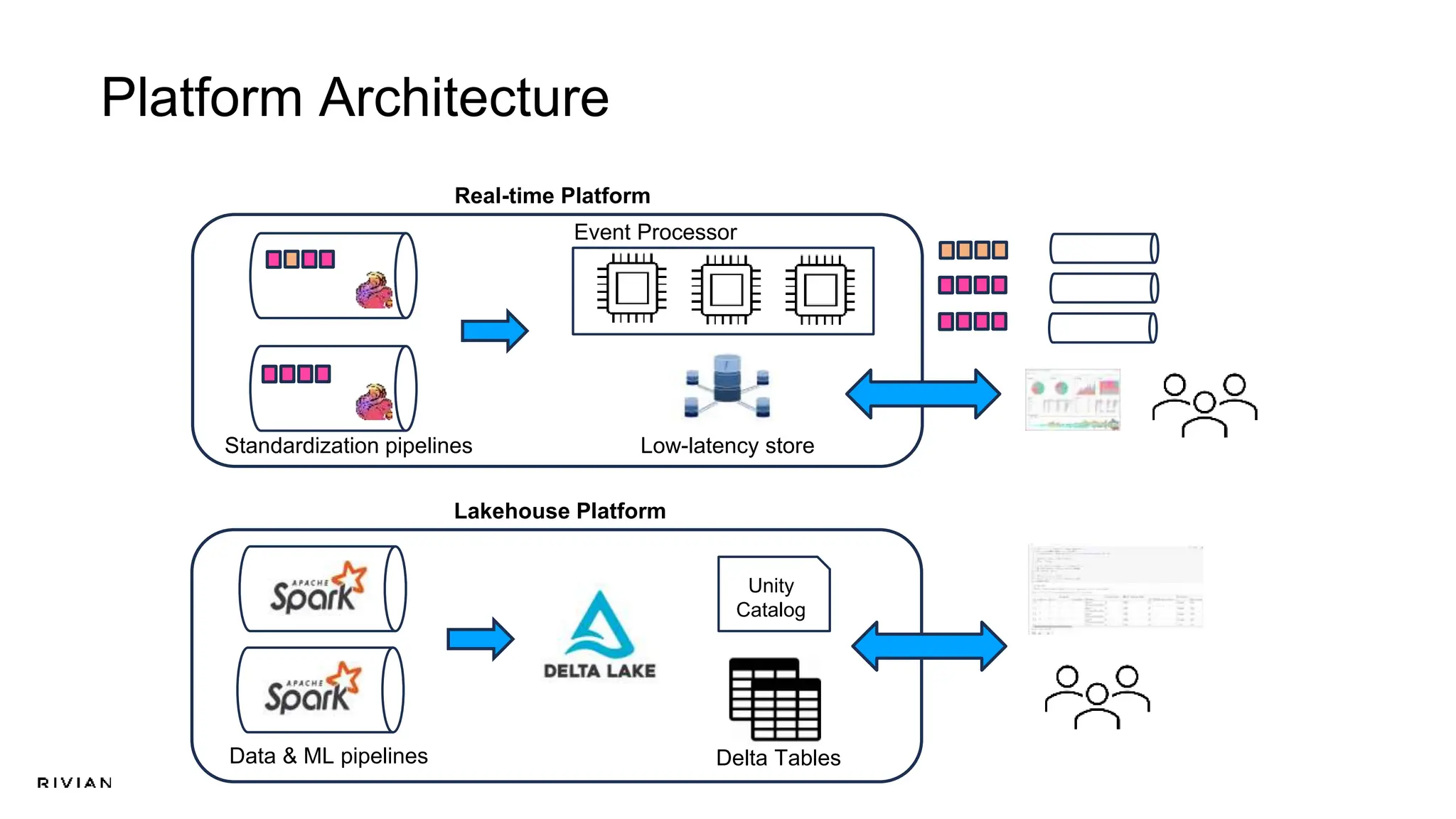
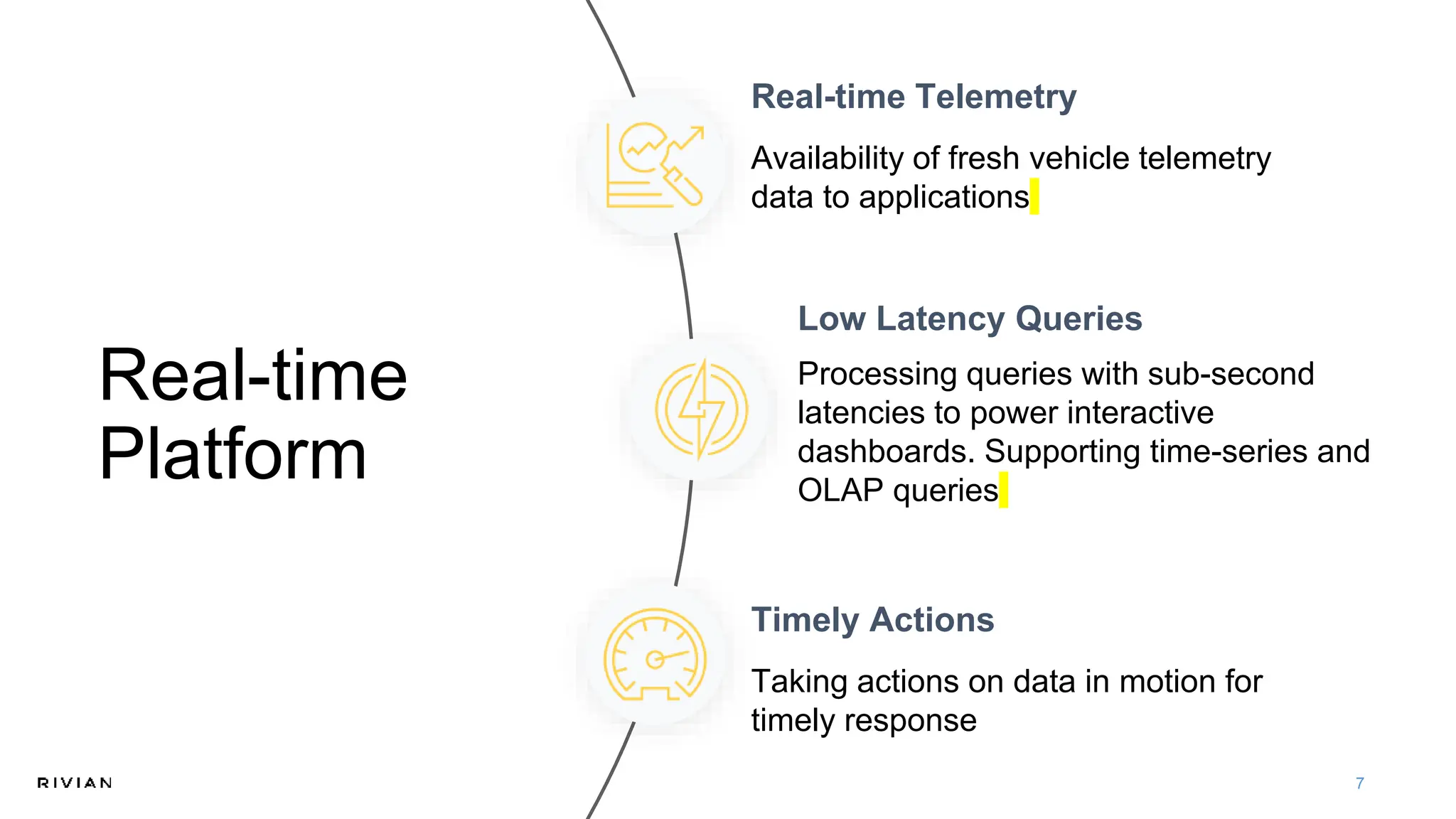
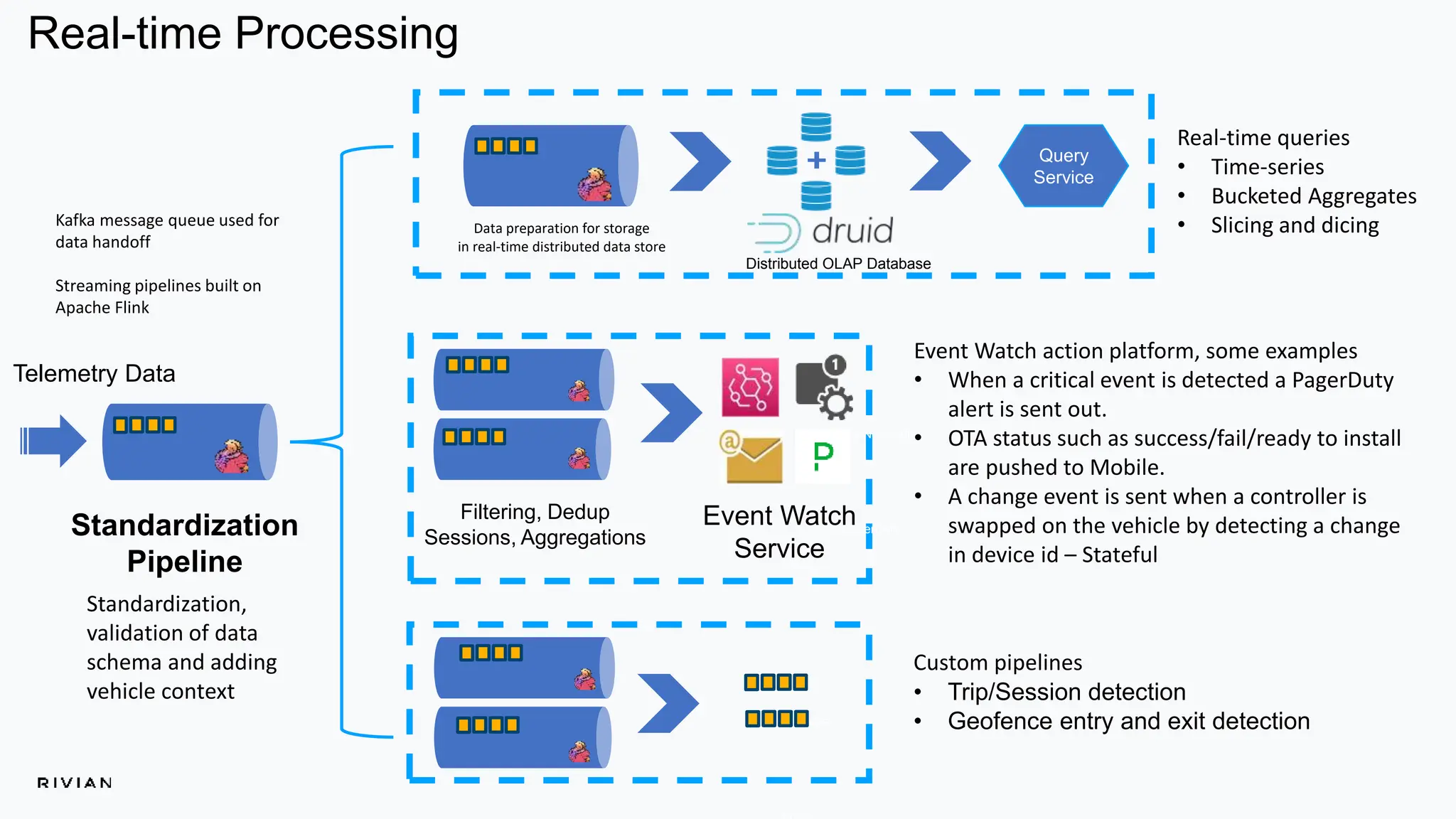
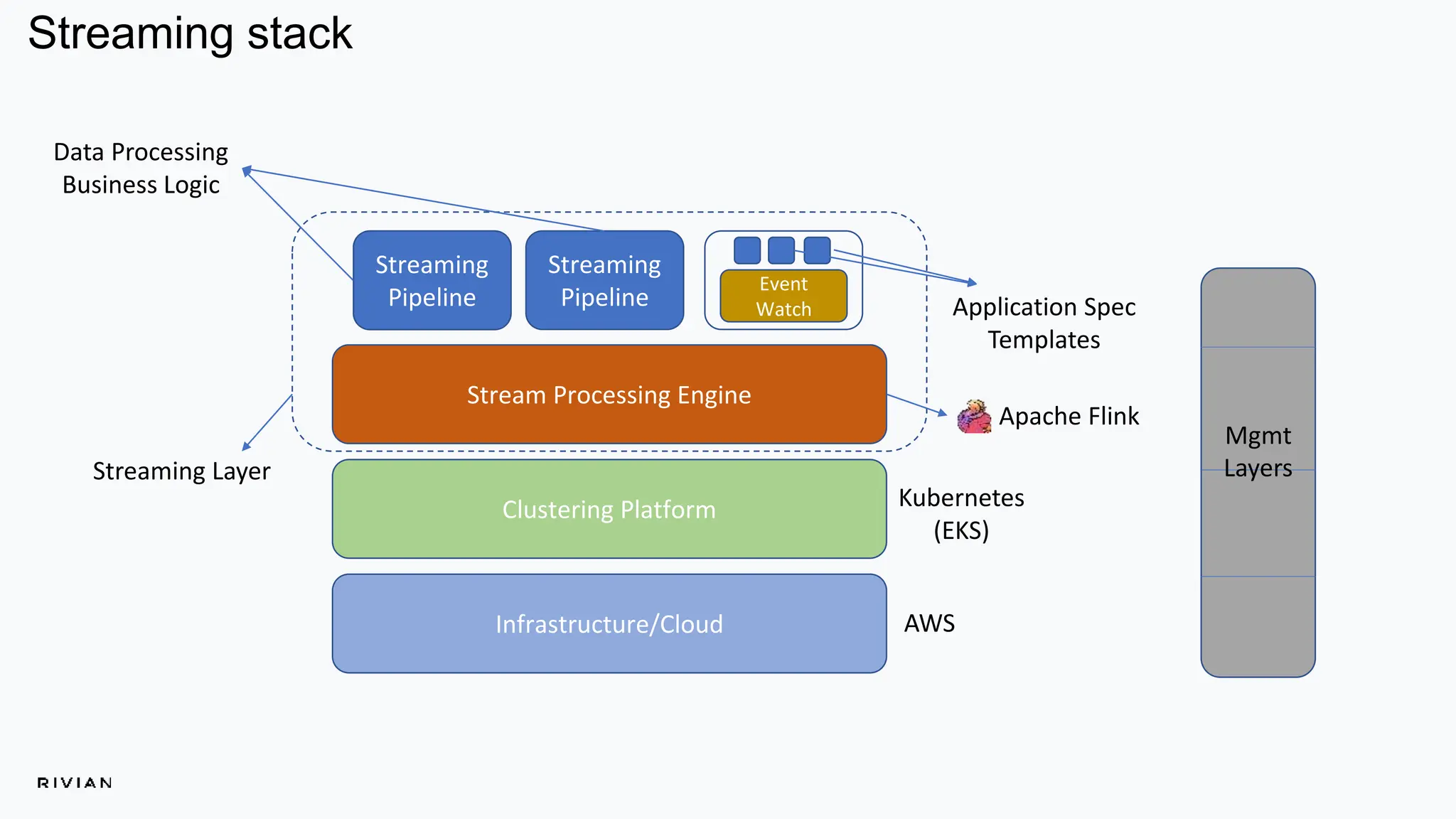
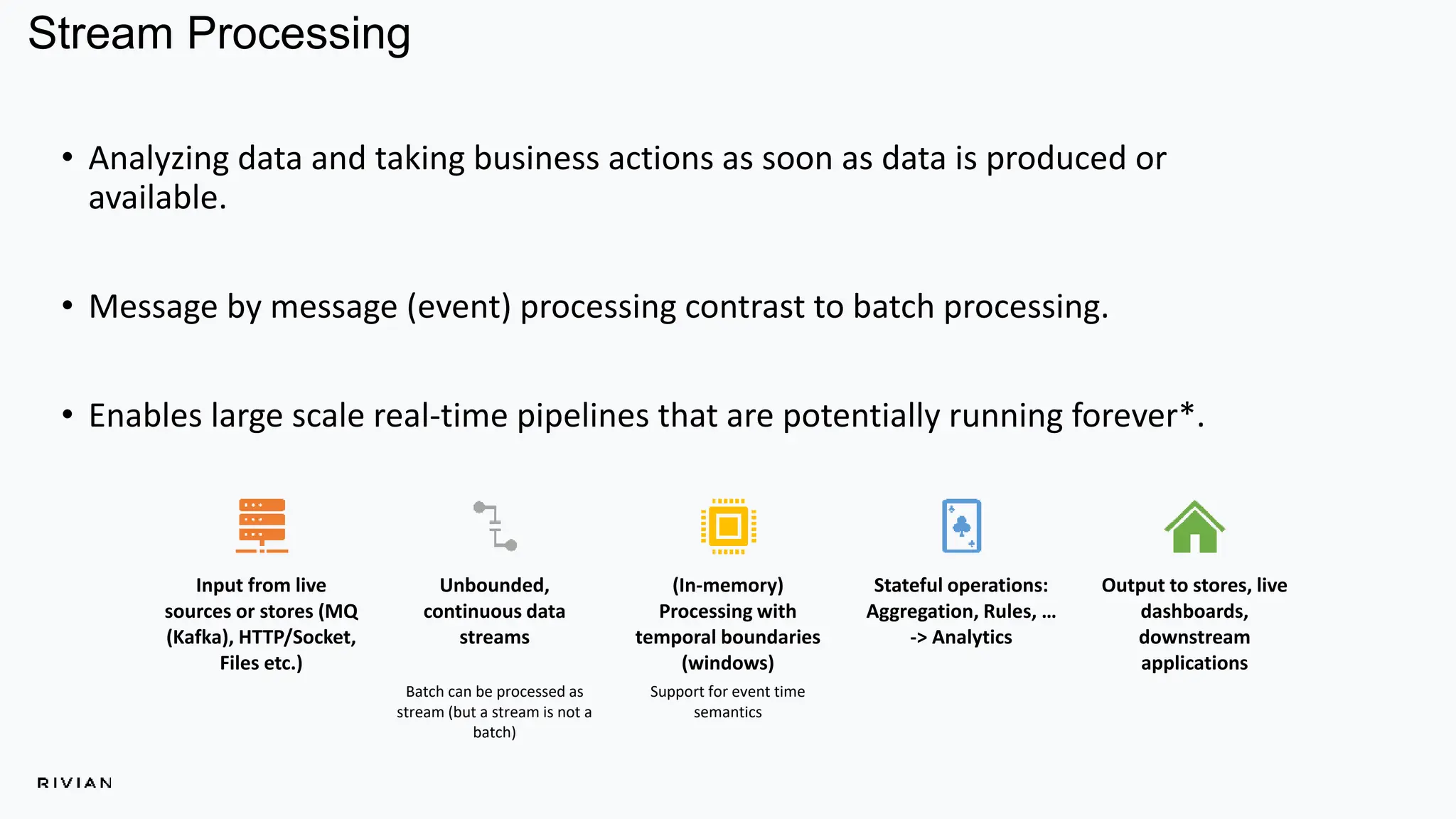
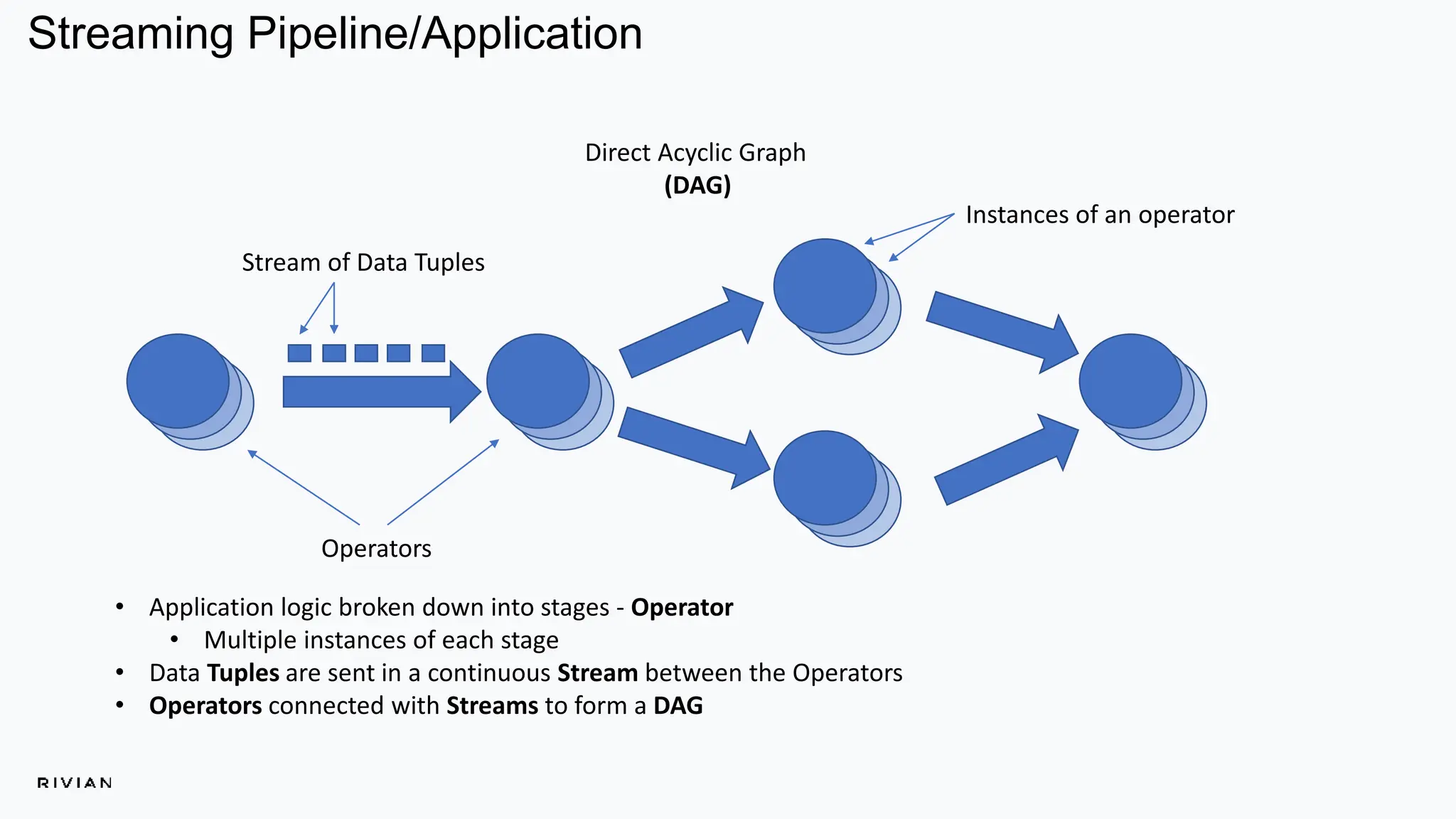
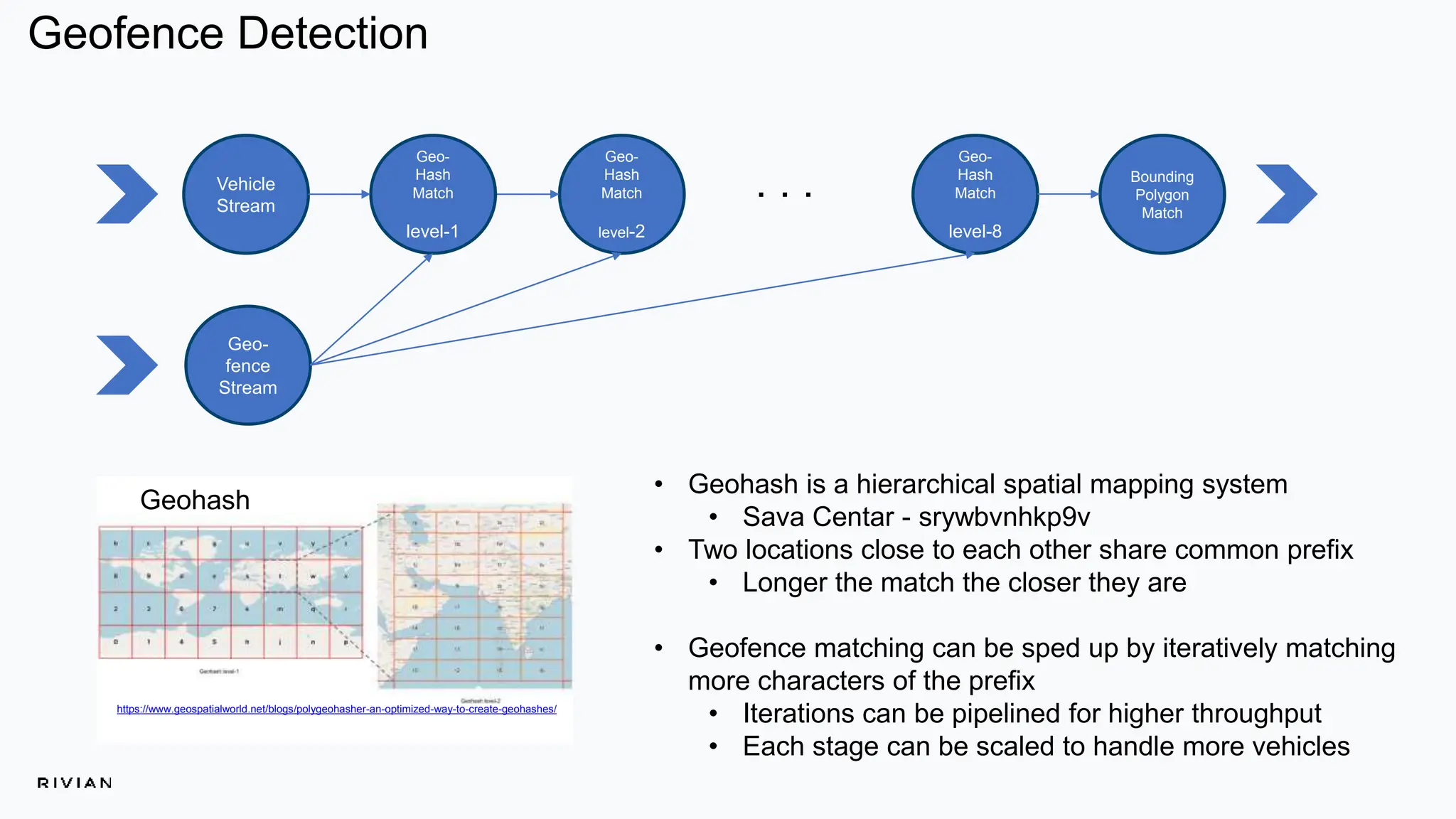
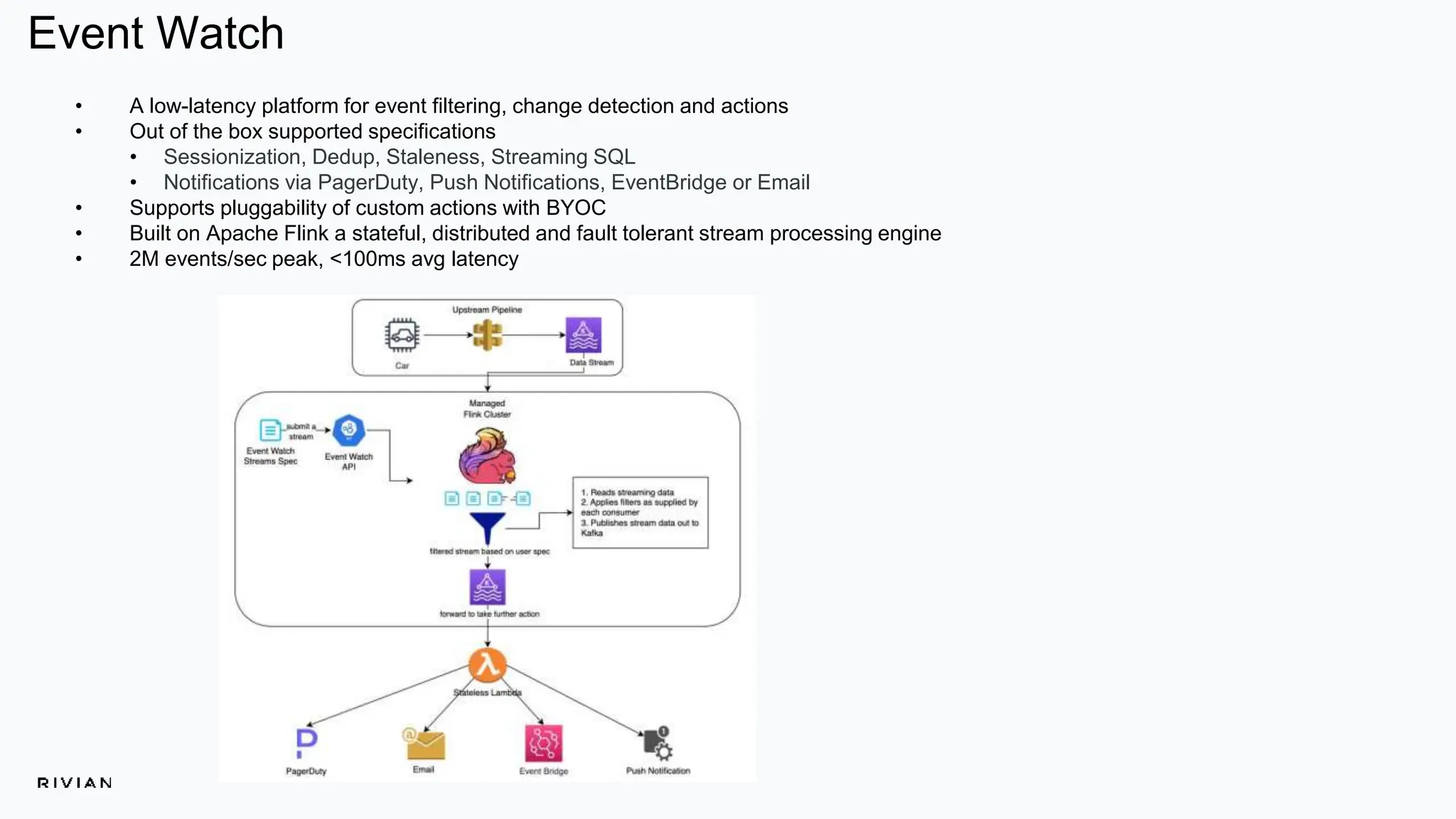
The document outlines Rivian's real-time analytics platform, designed for processing vehicle telemetry data with low latency and high efficiency. It highlights the use of streaming technologies, including Apache Flink and Kafka, to facilitate event detection, data processing, and proactive alerts. The platform supports real-time queries, data visualization, and fleet management through a robust architecture that integrates both historical and real-time data for comprehensive analytics.















![[ODSC EUROPE 2022] Eagleeye - Data Pipeline for Anomaly Detection in Cyber Se...](https://cdn.slidesharecdn.com/ss_thumbnails/odsceurope2022eagleeye-datapipelineforanomalydetectionincybersecurity-250320161155-77fa6dd8-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Pilar Baltar - From Model Drift to Capability Drift: Building...](https://cdn.slidesharecdn.com/ss_thumbnails/c3g3q8vdsc2arxmeclqs-pilar-baltar-from-model-drift-to-capability-drift-251219145036-e930d86d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jordi Vallverdu - Automating Nonsense.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/whnjqmquoeztfcd1htga-ai-in-labour-jordi-vallverdu-v2-251219145036-d8fcc878-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic - Educating Across Boundaries in the Age of A...](https://cdn.slidesharecdn.com/ss_thumbnails/4pthtbtirpqwgga3cydt-2-edtech-251219145616-47eda643-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jordi Vallverdu - MINIBRAIN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/x5xrnom2scxovikrd6zx-minibrain-neuroai-251219145036-2c42e47a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Antonio Durao - From Algorithm to Classroom: How Adaptive AI ...](https://cdn.slidesharecdn.com/ss_thumbnails/ndmhbhiztbcr1oqmalog-3-eduquest-beyond-the-right-answer-final-251219145616-bd45a359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Velibor Ilic - Autonomous Driving - How AI Shapes Technical ...](https://cdn.slidesharecdn.com/ss_thumbnails/gwu9aqths9ovngsrhidc-3-velibor-ilic-autonomous-driving-how-ai-shapes-technical-challenges-251219150035-7436923a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Wolfgang Klein & Olena Brandsch - Operationalizing GenAI: Tur...](https://cdn.slidesharecdn.com/ss_thumbnails/mdjqcqgoriqj6kdjabxk-8-251216105606-9290bc27-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mathias Halkjær Petersen - The AI workforce revolution.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3xviexv7q5gojhdsyvat-the-ai-workforce-revolution-251218084820-f3c286ed-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Assem Hussein - Future-Proof Your Business: AI, Market Fit, a...](https://cdn.slidesharecdn.com/ss_thumbnails/jatyvqbnqc5rbebpup5t-assem-hussein-251218085553-3983d431-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Oliver Kosta Zivic - Vendor Lock-in or Weekend Lock-out: Choo...](https://cdn.slidesharecdn.com/ss_thumbnails/x1wkdzrlr7aain6x3dko-vendor-lock-in-or-weekend-lock-out-choosing-between-databricks-comfort-and-spar-251218084820-88ec7e39-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Matthias Rochtus - Geo-Intelligence: Business insights Throug...](https://cdn.slidesharecdn.com/ss_thumbnails/kv1lkcvasxycdlyirxxa-matthias-dsc-europe-serbia-geospatial-251218084819-1743cb20-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tim Sears - Making AI Real: From Research to Impact.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rgb1innksugkggjhv43s-6-251218084257-61e06116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrej Zdravkovic - AI in Action: Can We Unlock 50% Productiv...](https://cdn.slidesharecdn.com/ss_thumbnails/gb3jwads9ehoagcmmzfz-1-251218084256-bf6869a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mahmoud Fahmy - Transforming Enterprise AI with Scalable LLM ...](https://cdn.slidesharecdn.com/ss_thumbnails/rxsvz5tfstg5fquy016q-3-251218084257-1d2ce5f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dejan Djekic - Building Data Platforms That Build Themselves:...](https://cdn.slidesharecdn.com/ss_thumbnails/ojhu5yyxrl2sb727aghz-dejan-djekic-building-data-platforms-that-build-themselves-dsc-europe-belgrade--251218085301-a0fa979c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)