Downloaded 53 times












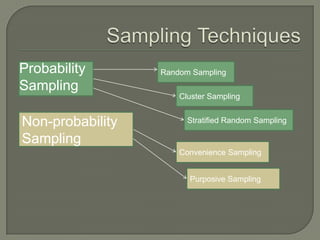


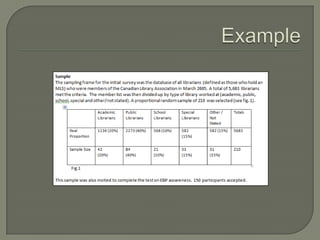








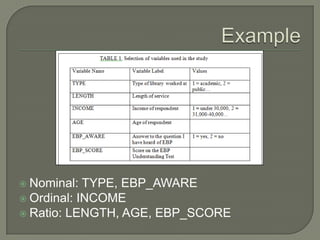

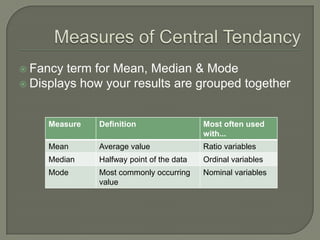
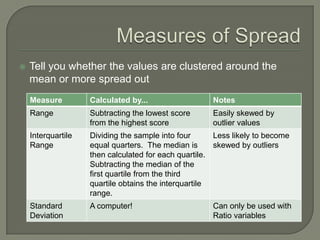




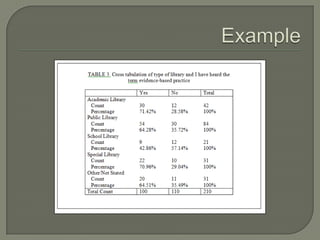
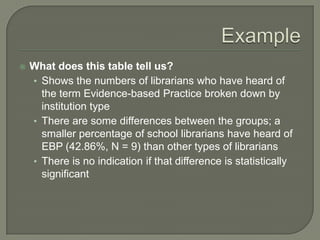












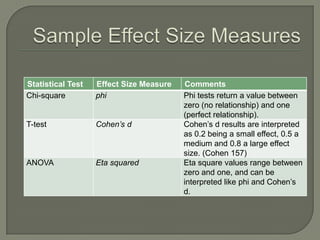



This document provides an overview of key concepts in research methods and statistical analysis. It defines important terms like hypotheses, variables, sampling, and statistical significance. It also describes common statistical tests like t-tests, ANOVA, correlation coefficients, and their appropriate uses and limitations. Various measures of central tendency, dispersion, and their interpretations are outlined. Examples are provided to illustrate statistical concepts. The document serves as a useful introduction and reference guide for understanding research methodology and statistics.























































































