Downloaded 272 times

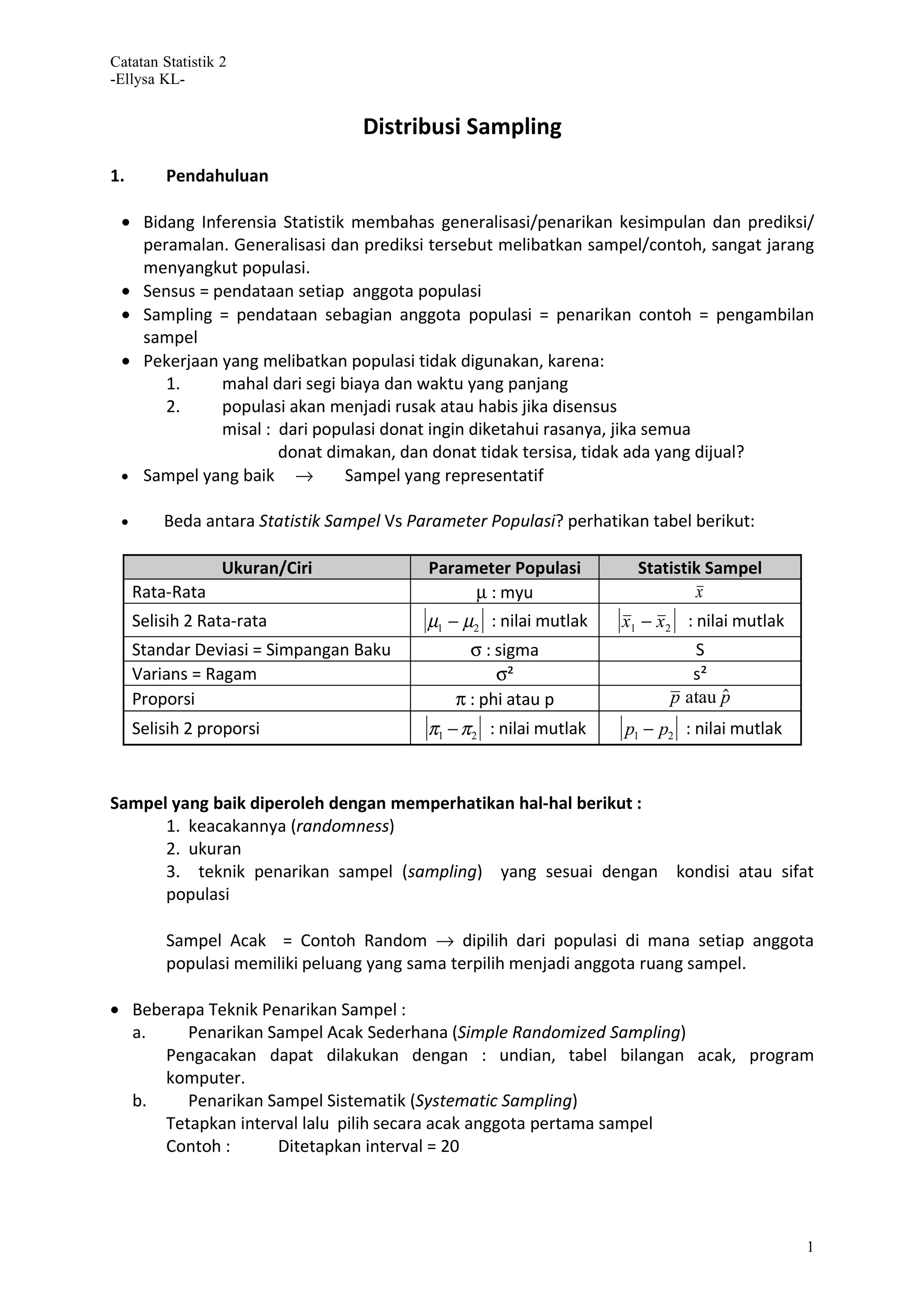










Dokumen tersebut membahas tentang distribusi sampling dan teknik-teknik pengambilan sampel. Terdapat beberapa teknik pengambilan sampel seperti pengambilan sampel acak sederhana, sistematis, acak berlapis, gerombol/kelompok, dan area. Dokumen juga membahas distribusi sampling rata-rata untuk sampel besar dan kecil serta contoh perhitungannya."








































![KELOMPOK_3_STATMAT_(DISTRIBUSI_SAMPLING_&_TEOREMA_LIMIT_PUSAT)[1] [Read-Only]...](https://cdn.slidesharecdn.com/ss_thumbnails/kelompok3statmatdistribusisamplingteoremalimitpusat1read-only-250804224555-5f278eb5-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Modul Ajar KBC SKI Kelas 6 MI [MODULKELAS.COM]](https://cdn.slidesharecdn.com/ss_thumbnails/modulajarkbcskikelas6mimodulkelas-260207160743-753abfd0-thumbnail.jpg?width=640&height=640&fit=bounds)












