Downloaded 25 times


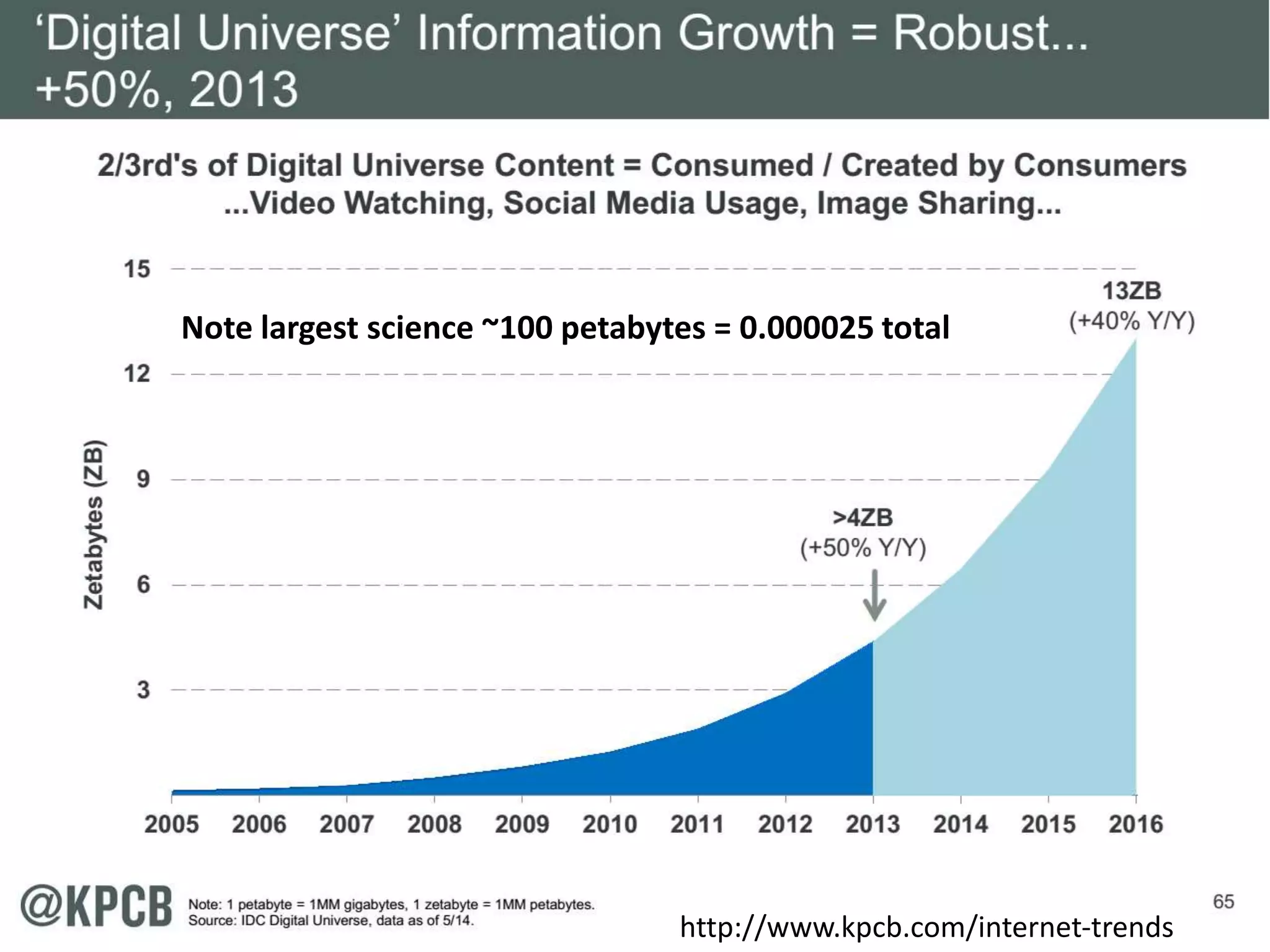

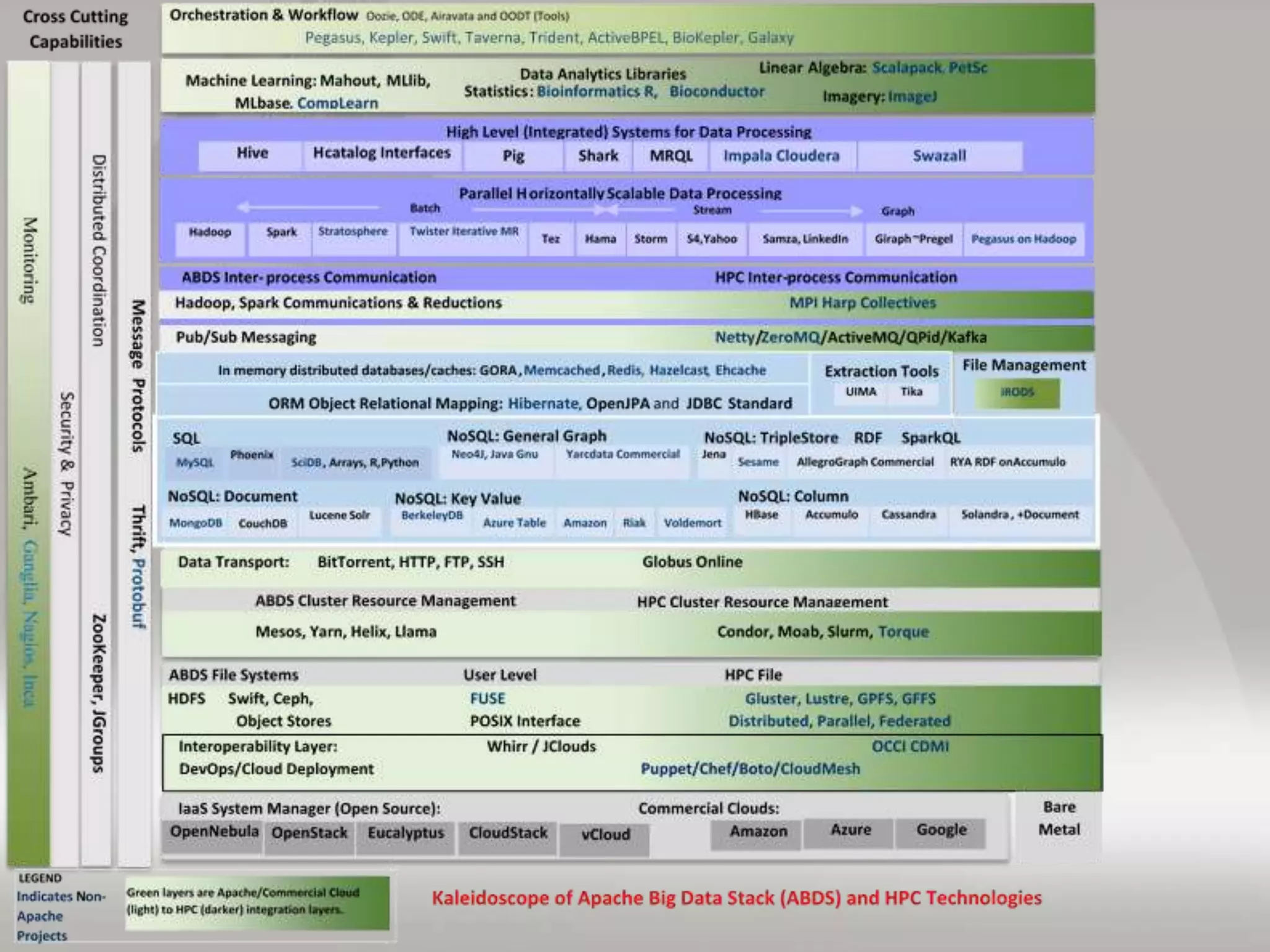
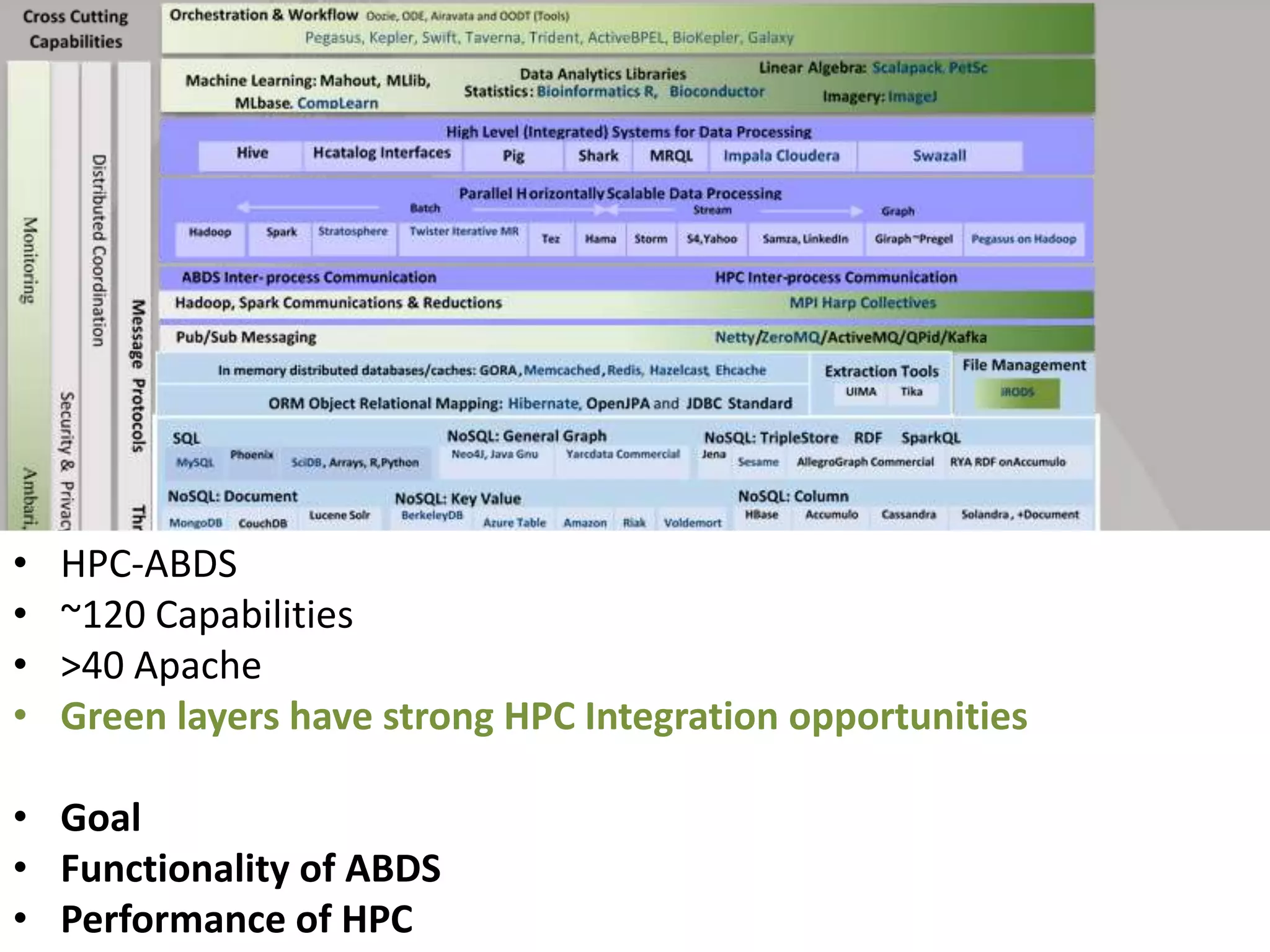



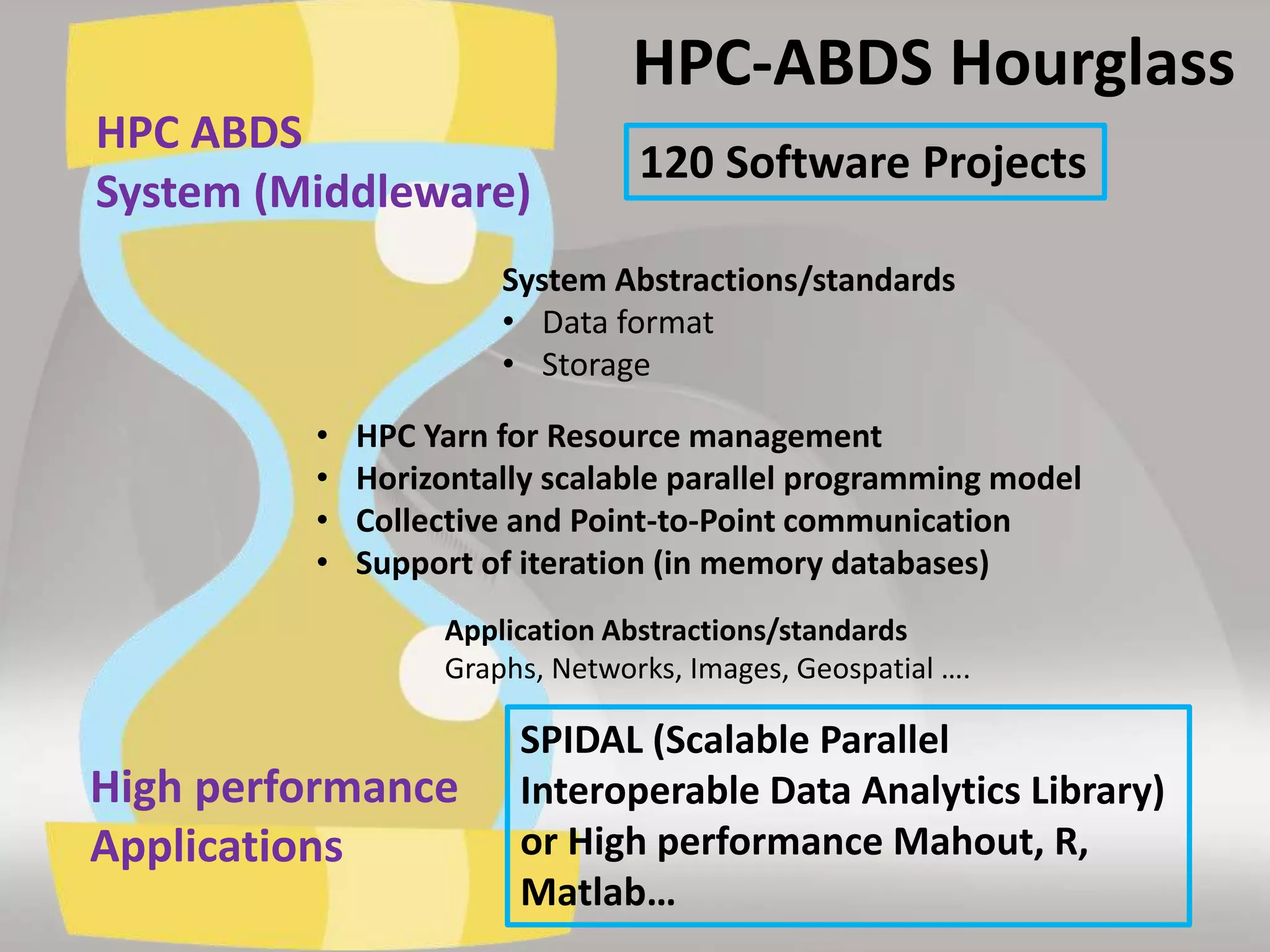

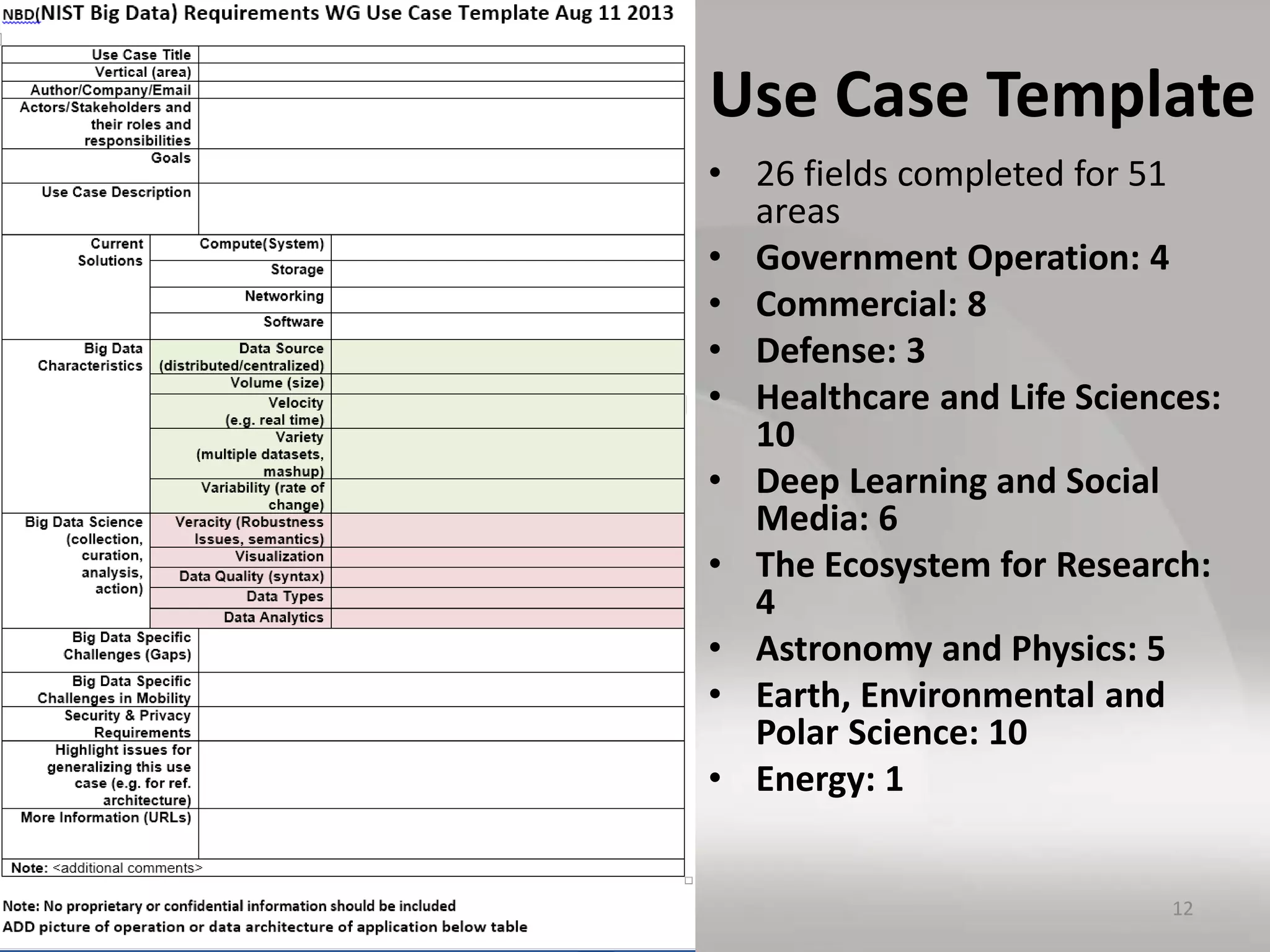

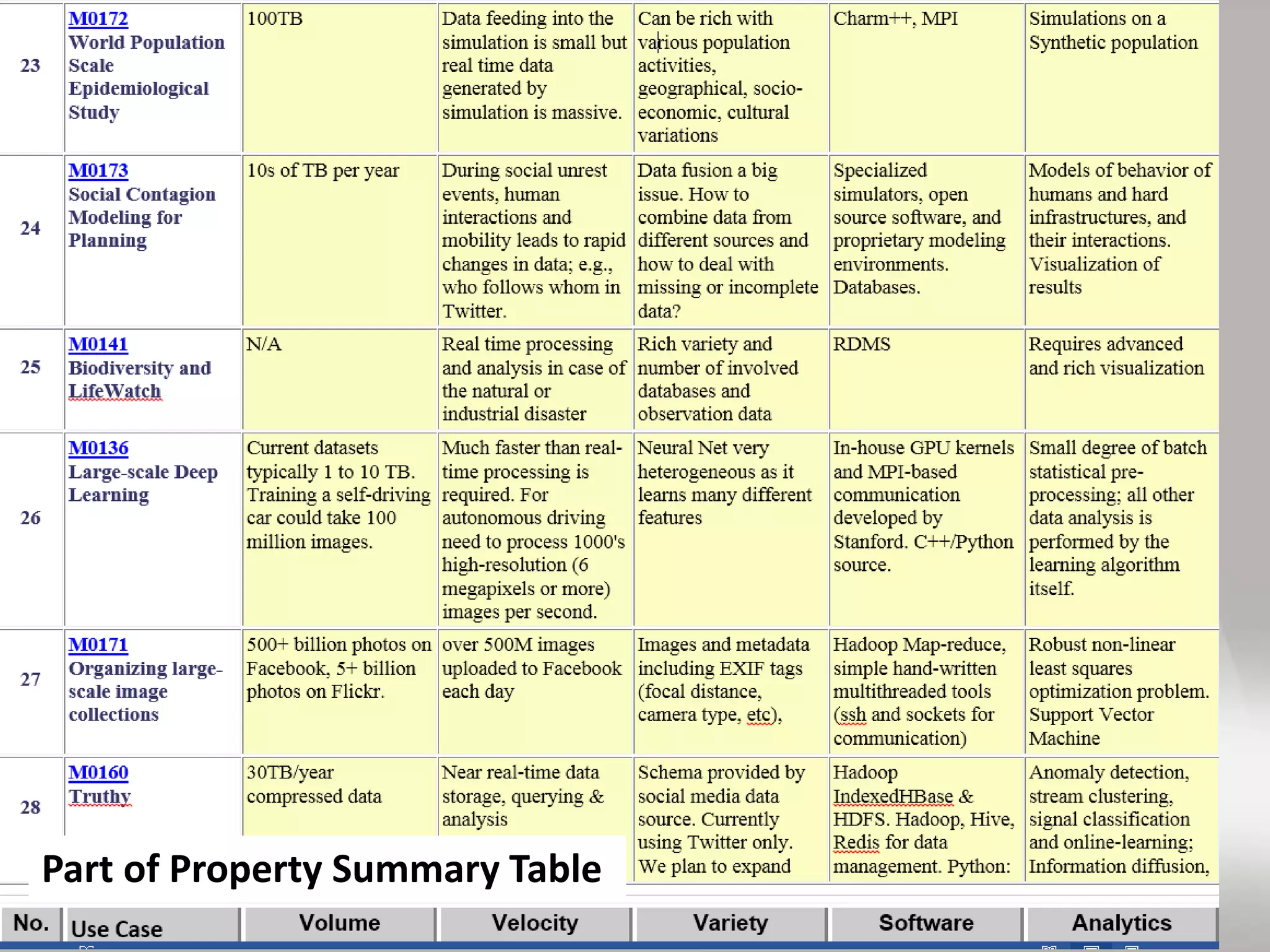












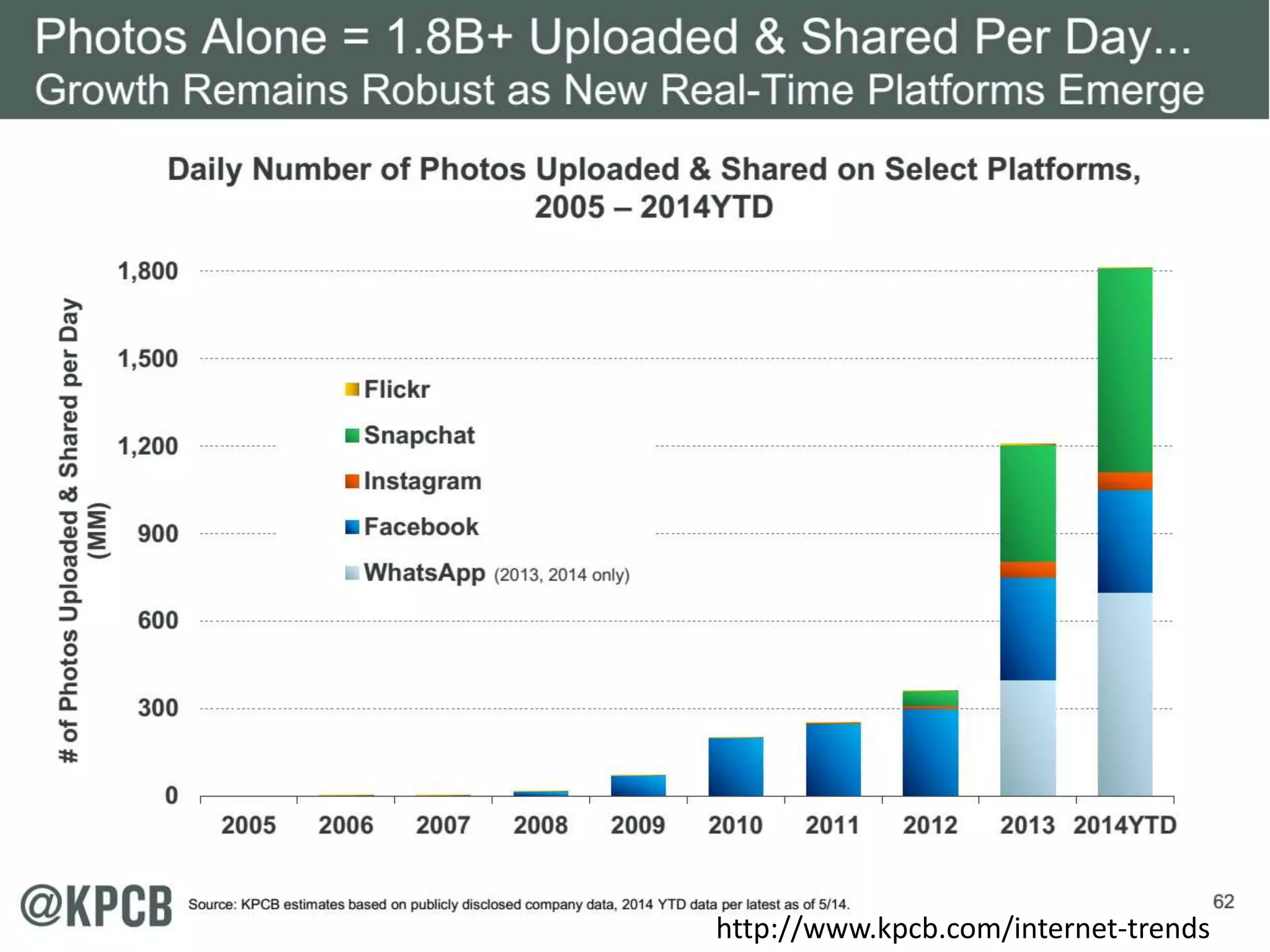
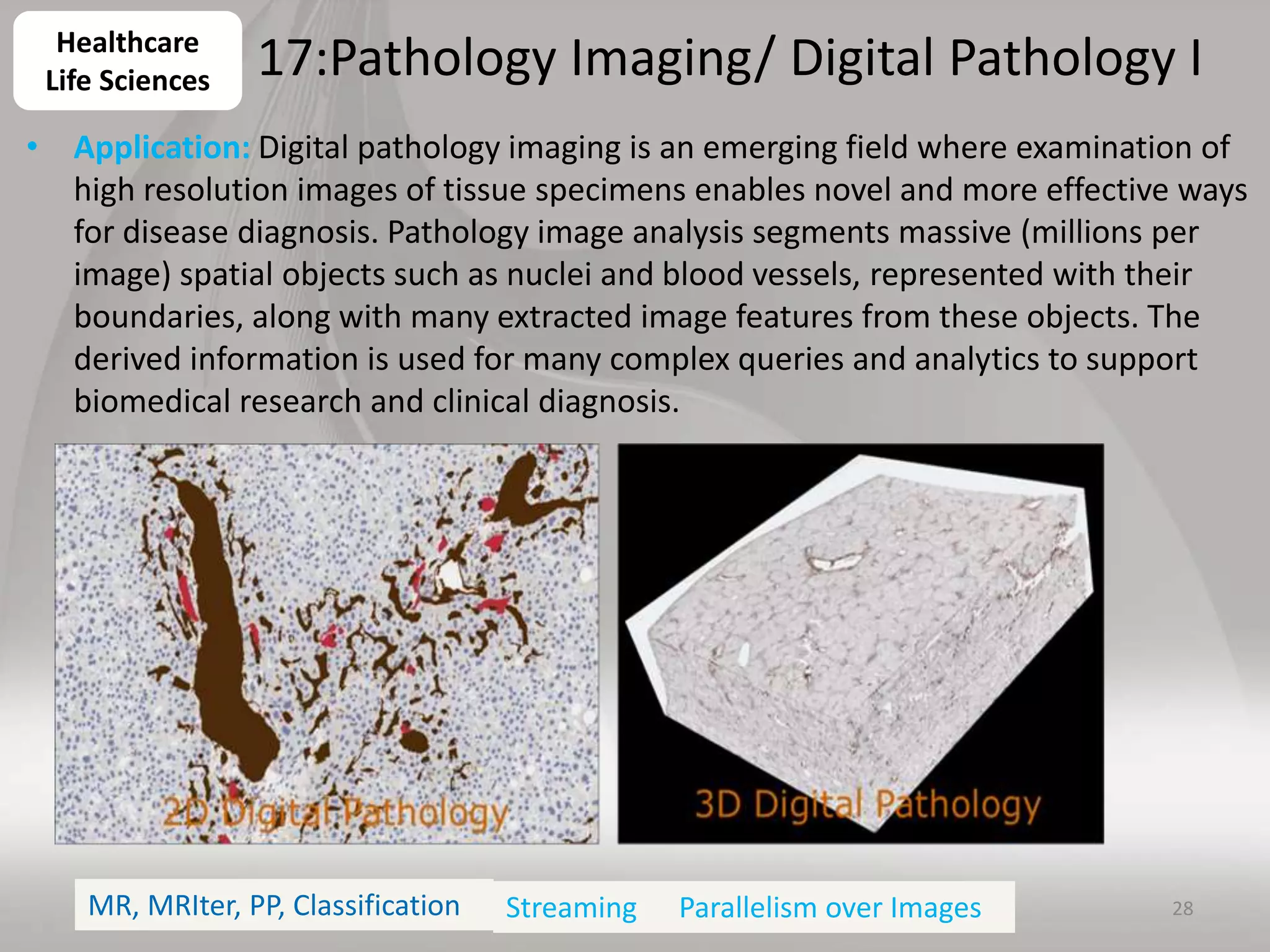
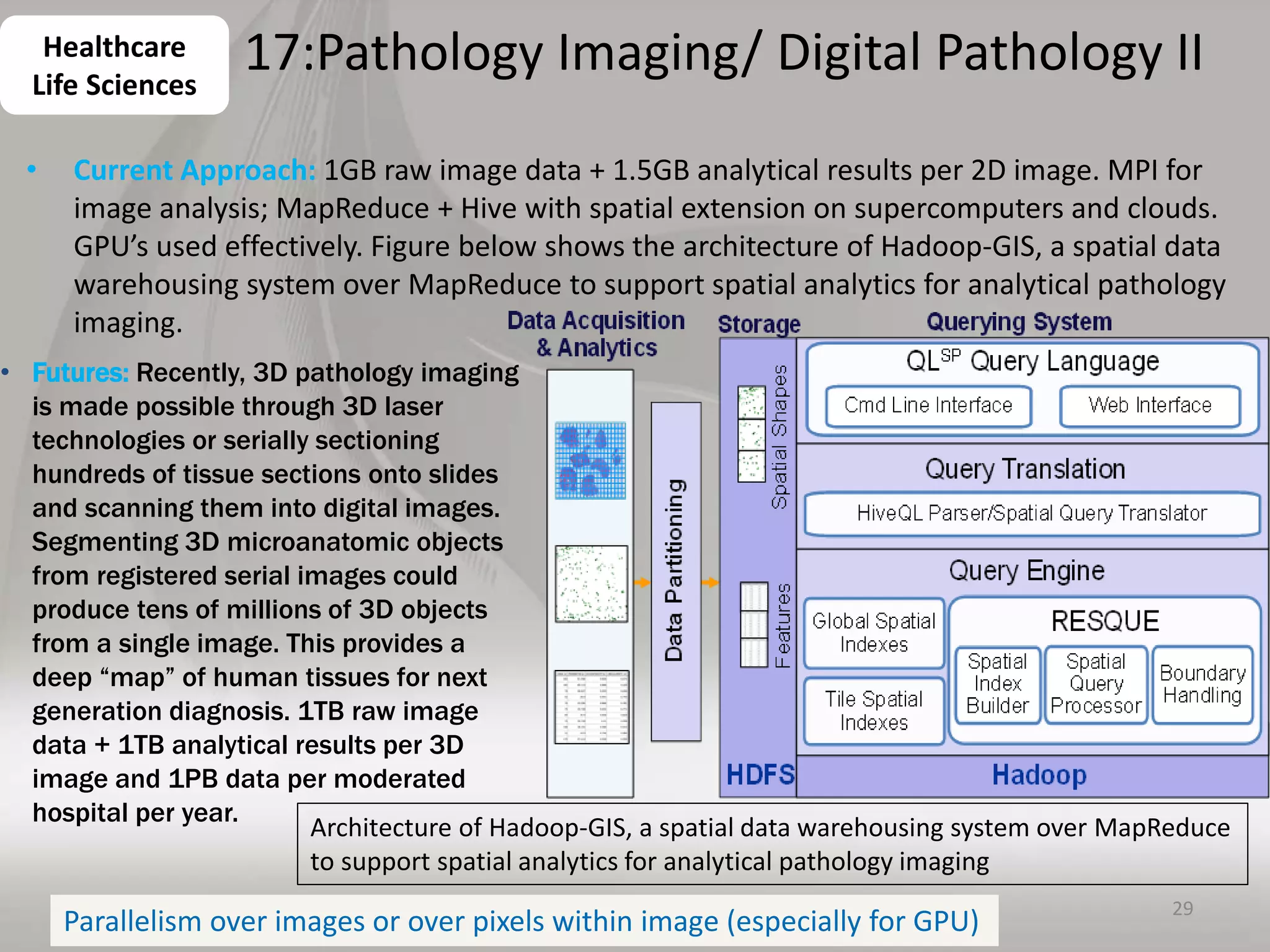





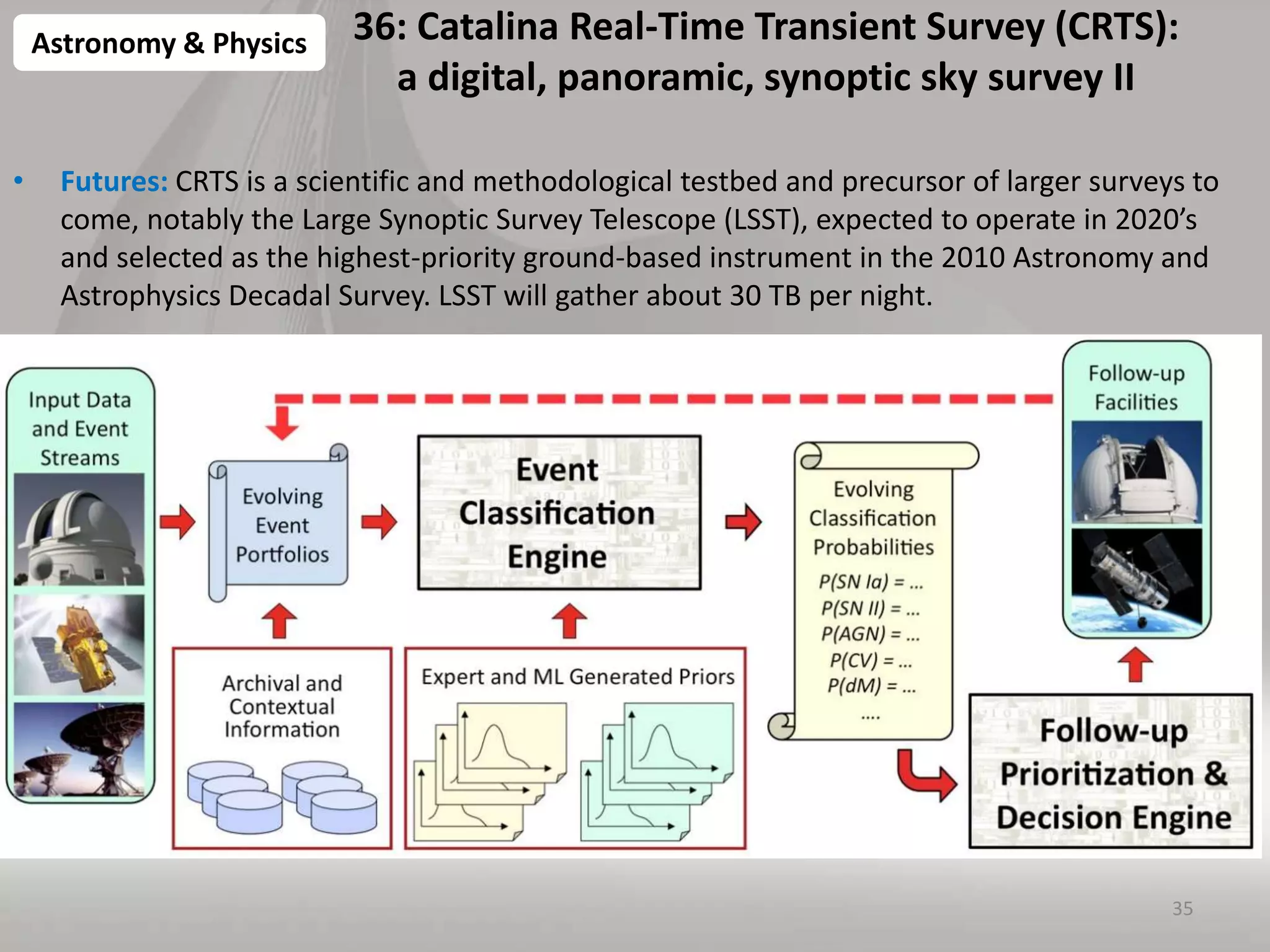
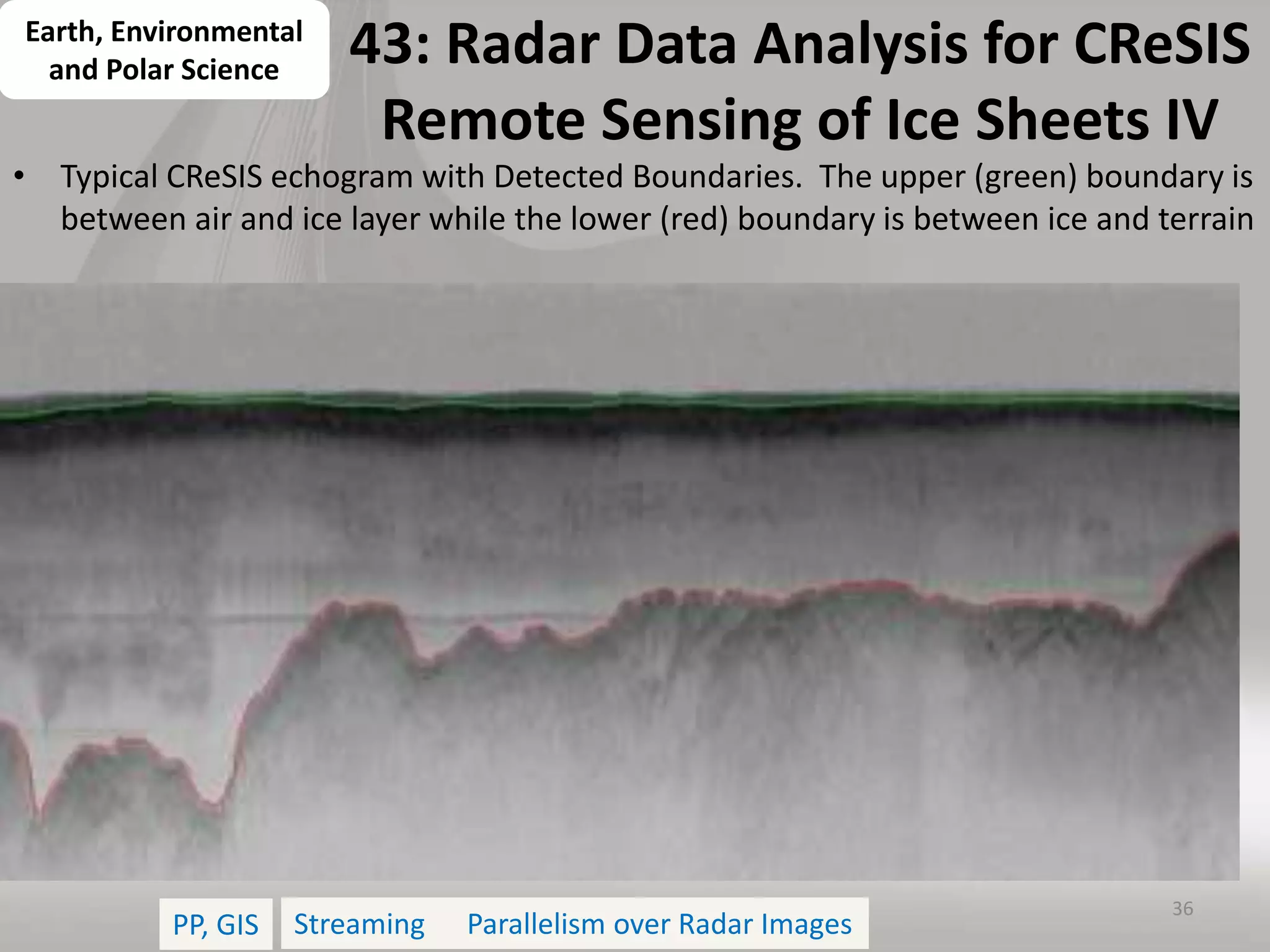
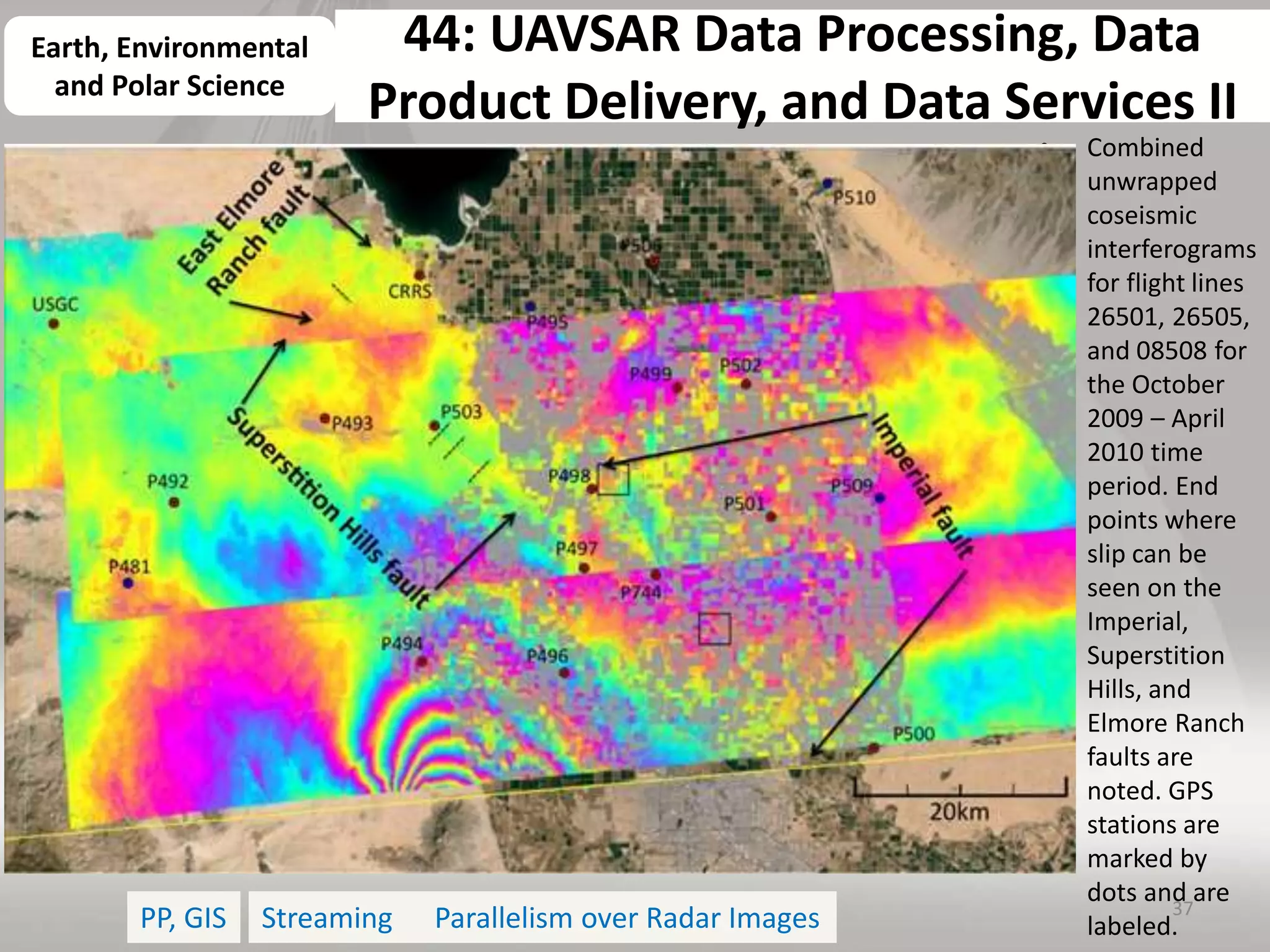



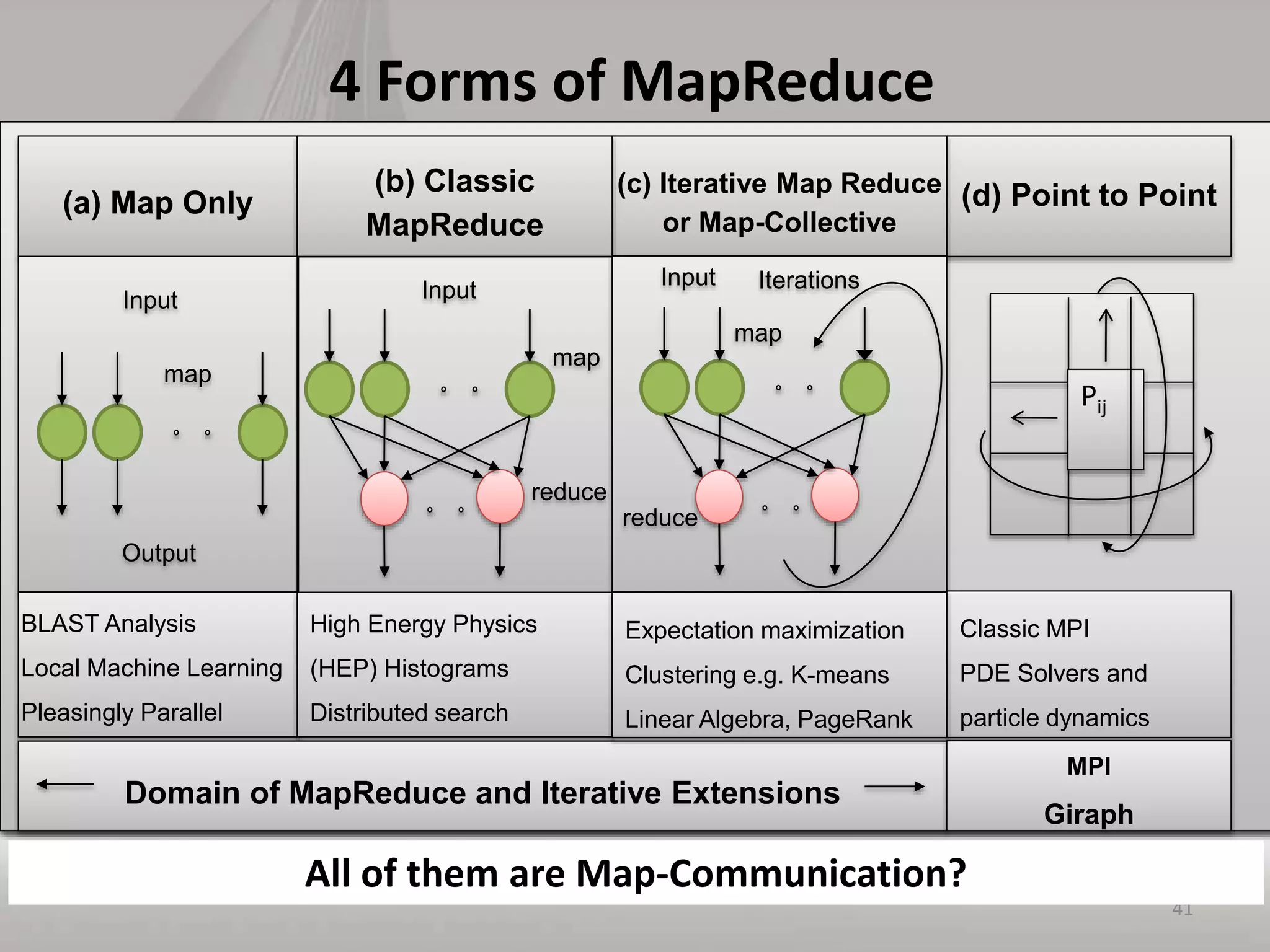






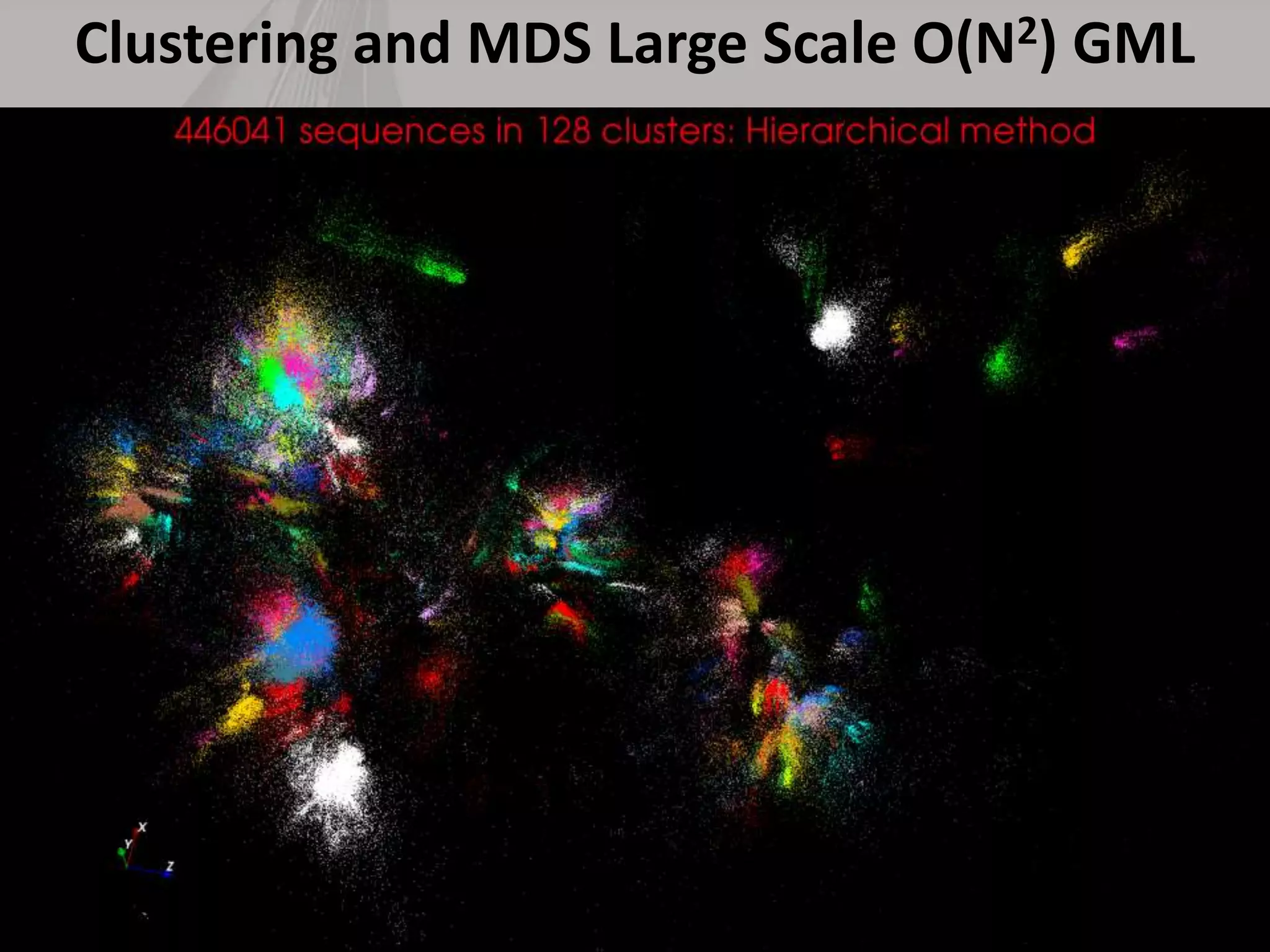
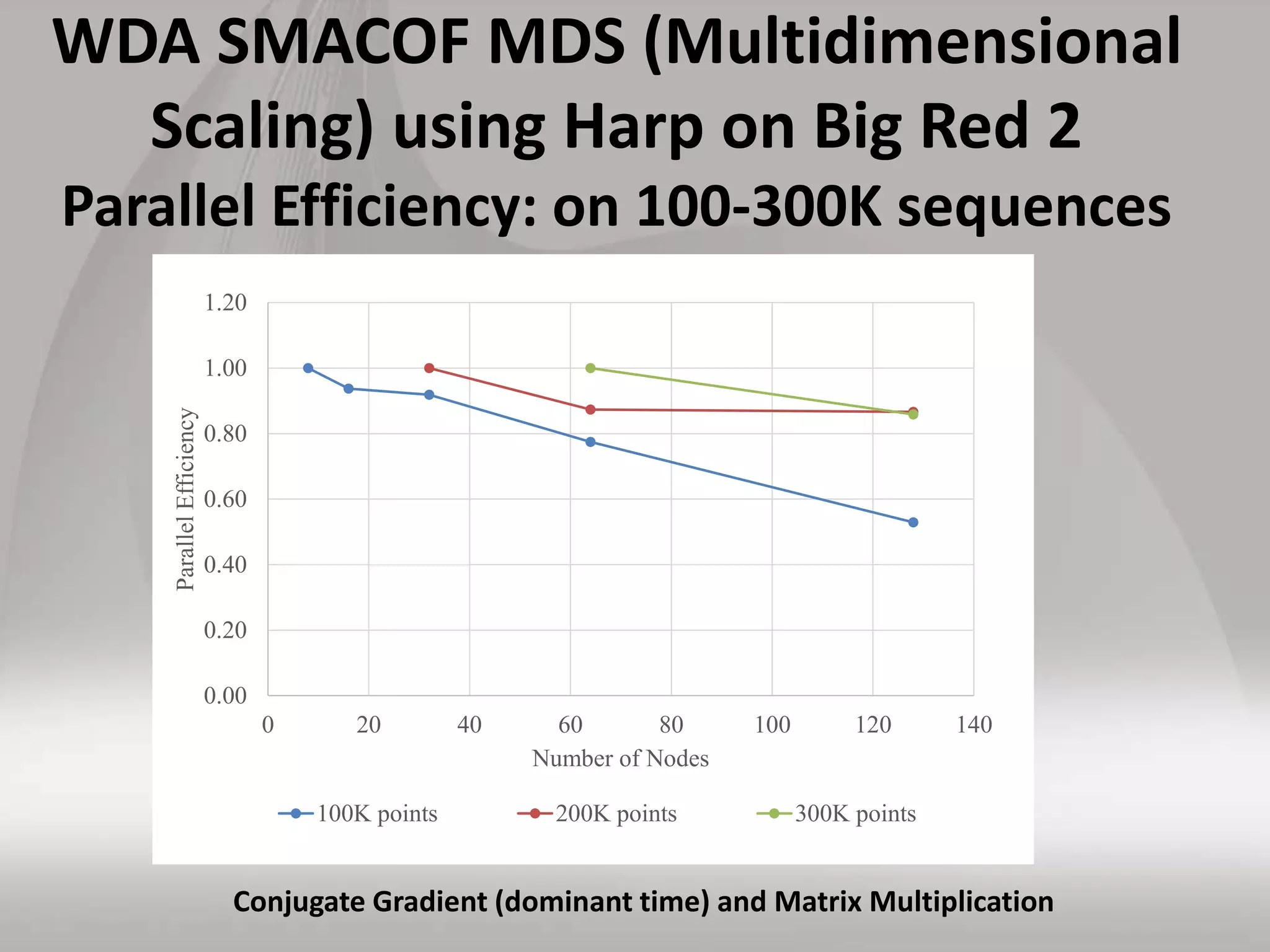

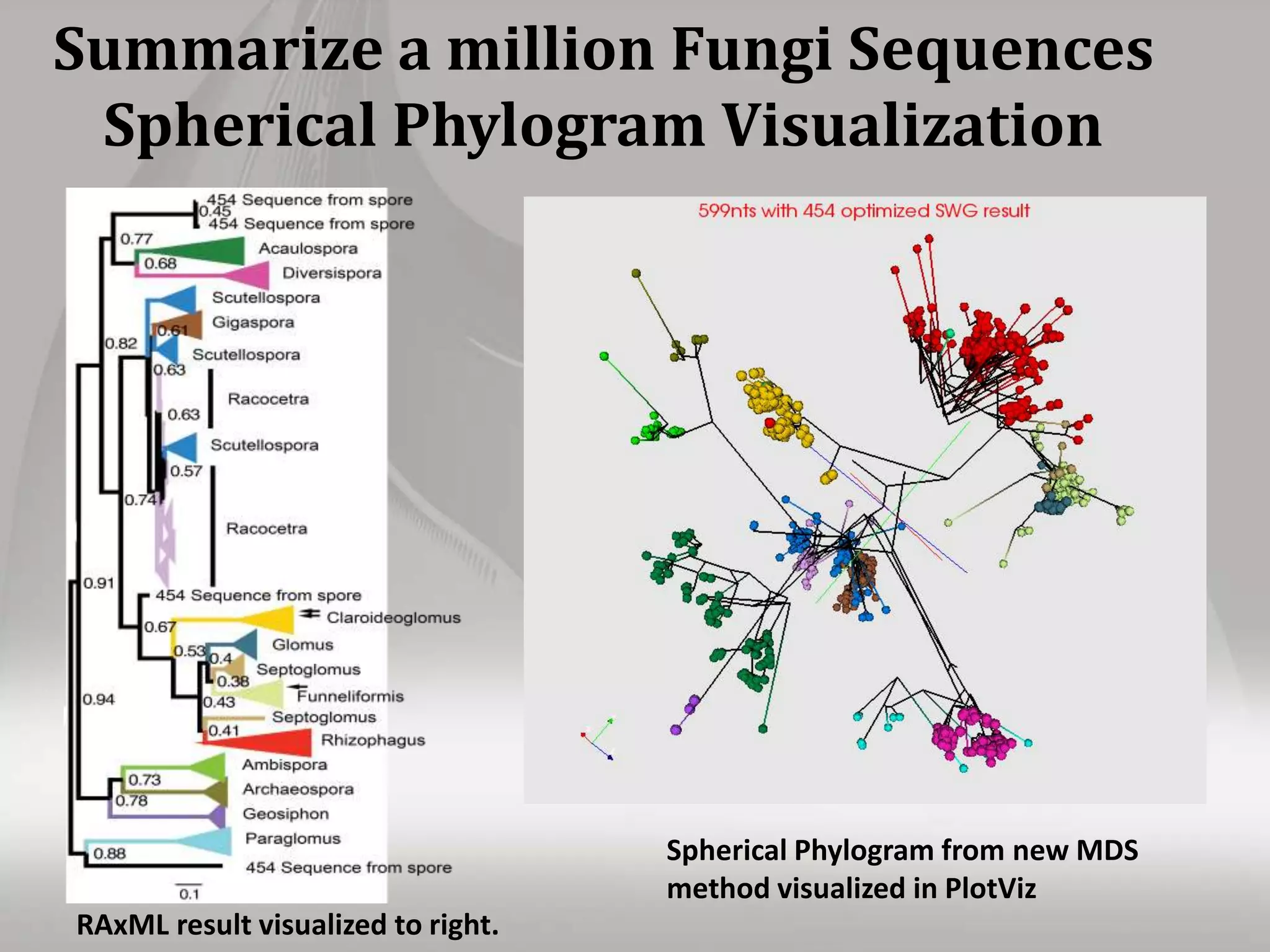



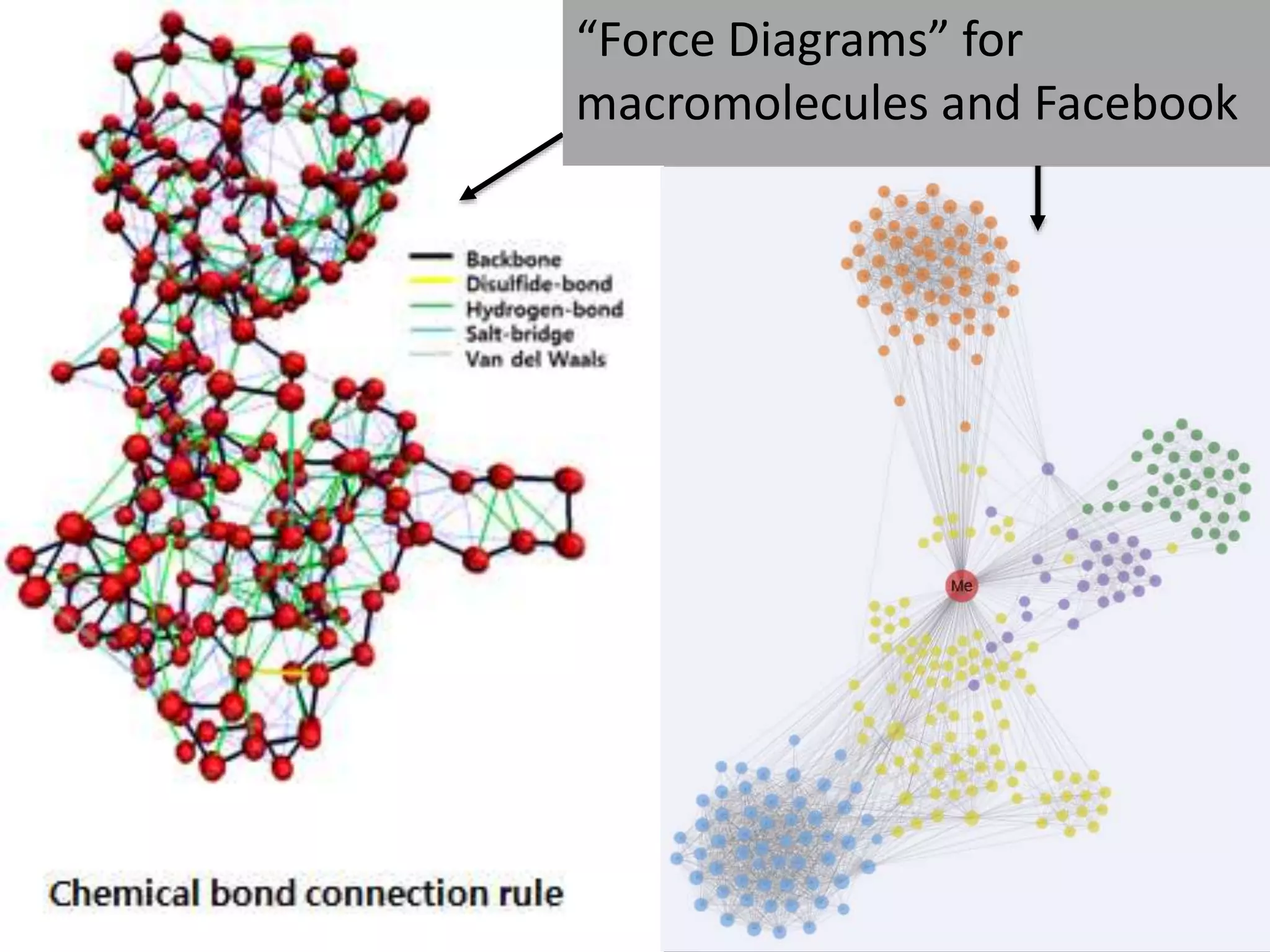

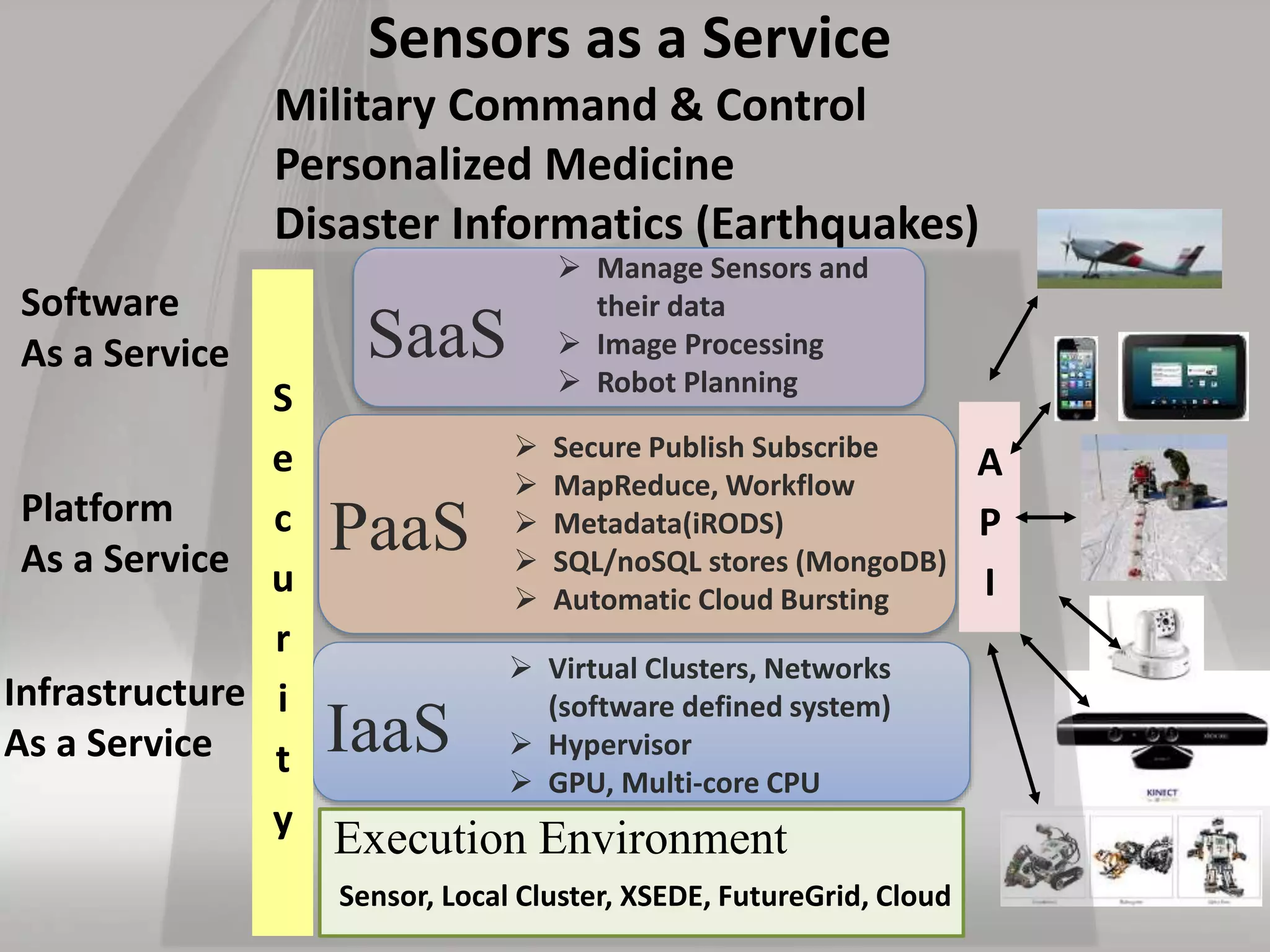

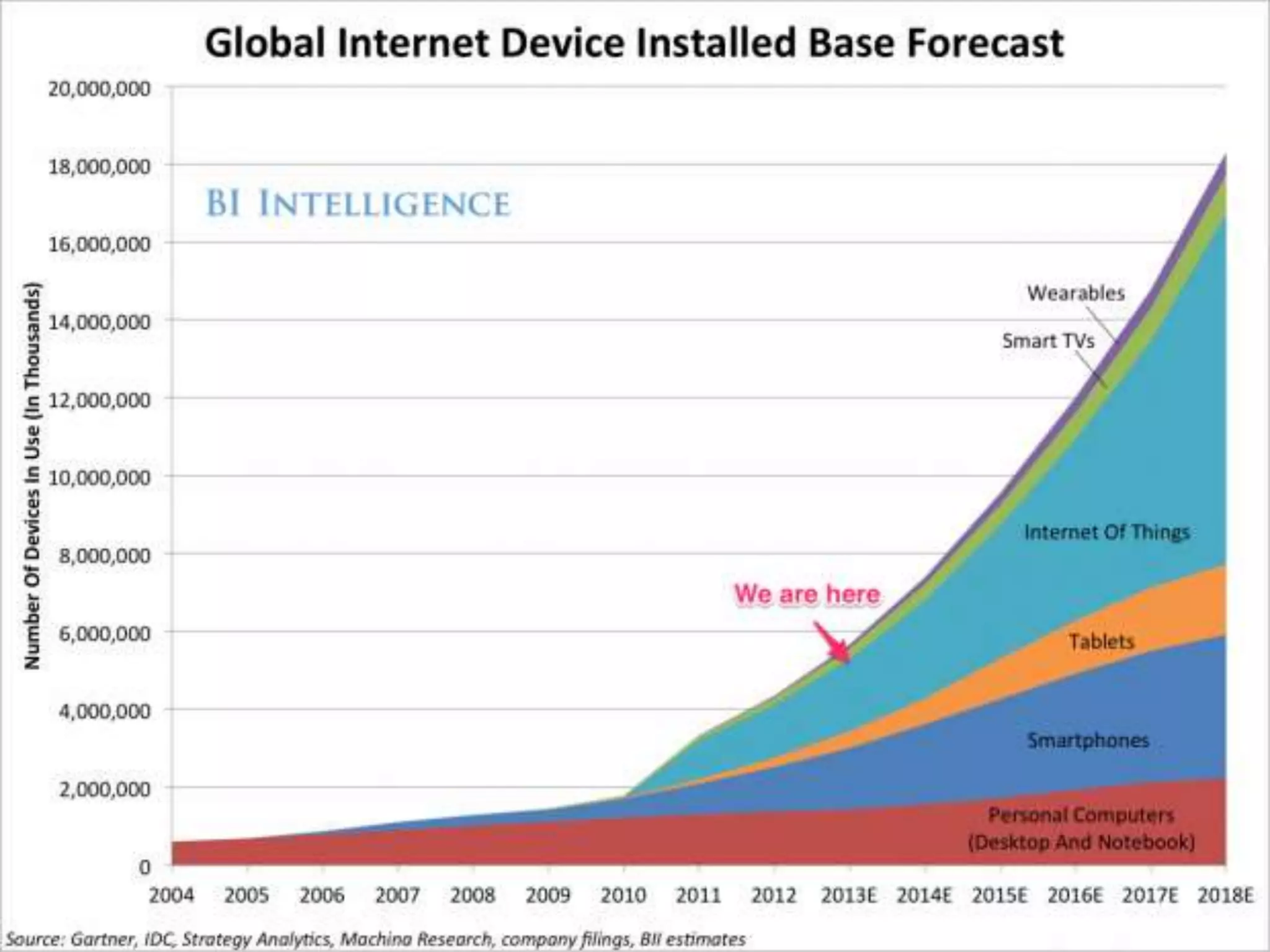
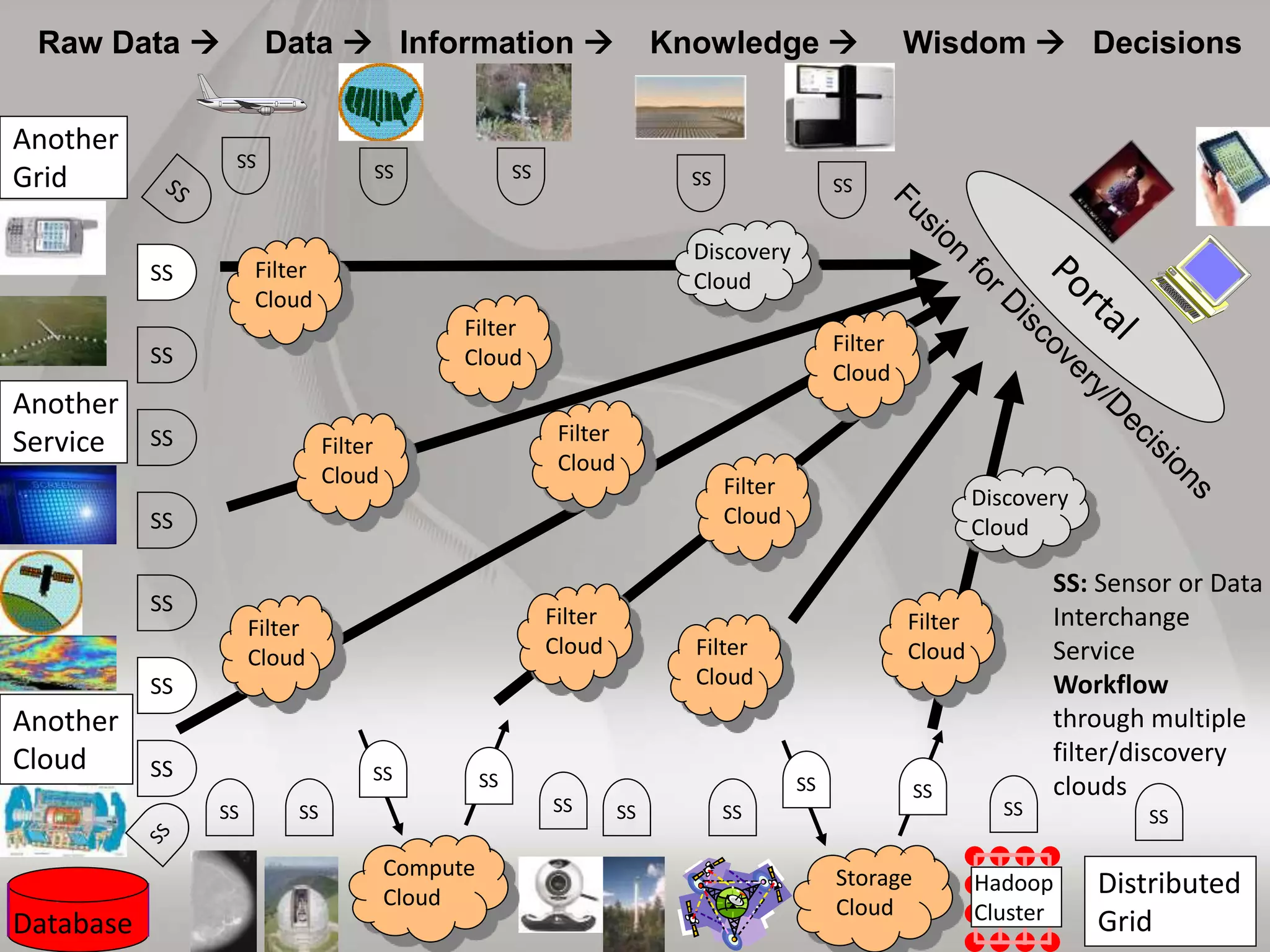
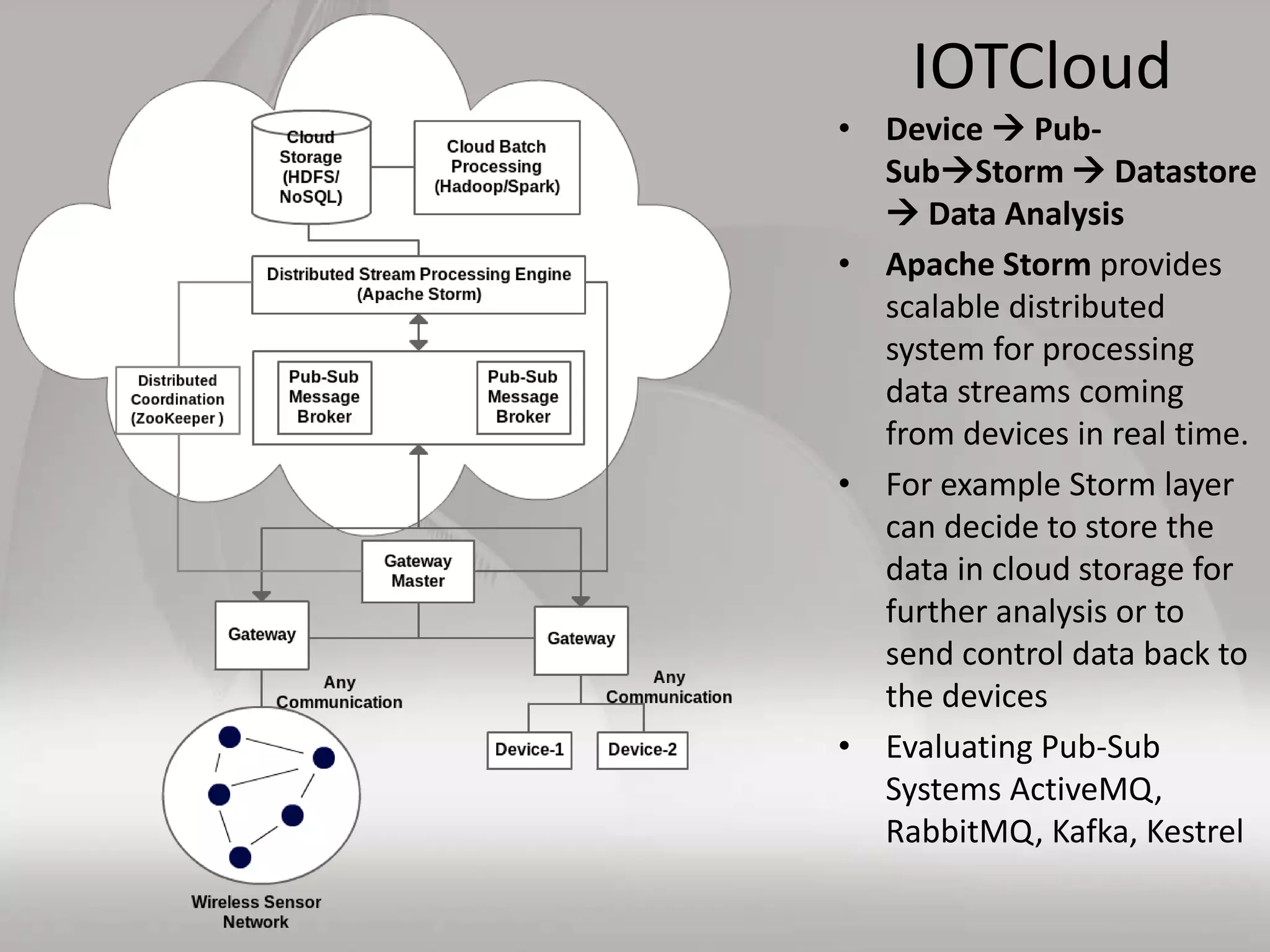
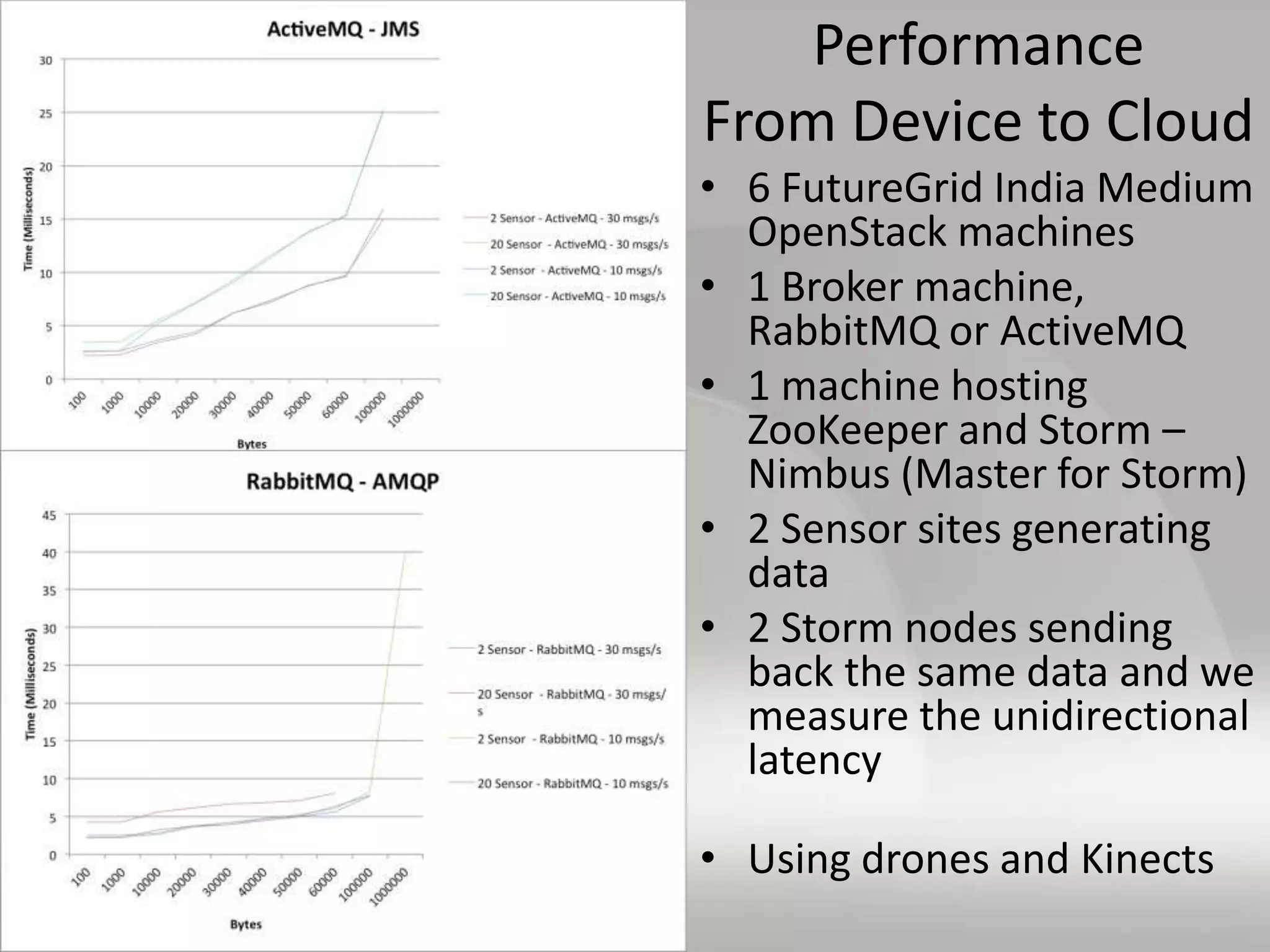






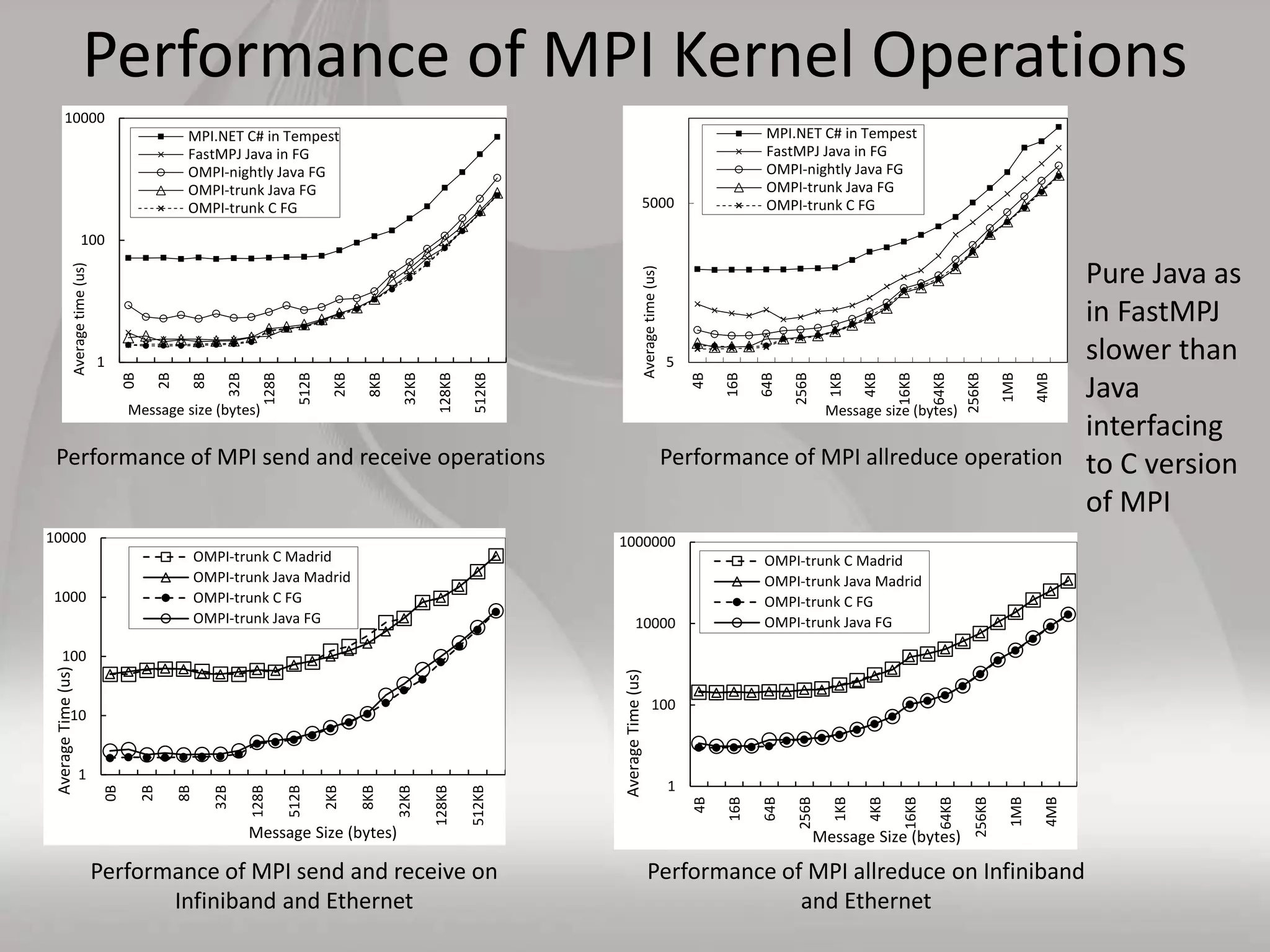

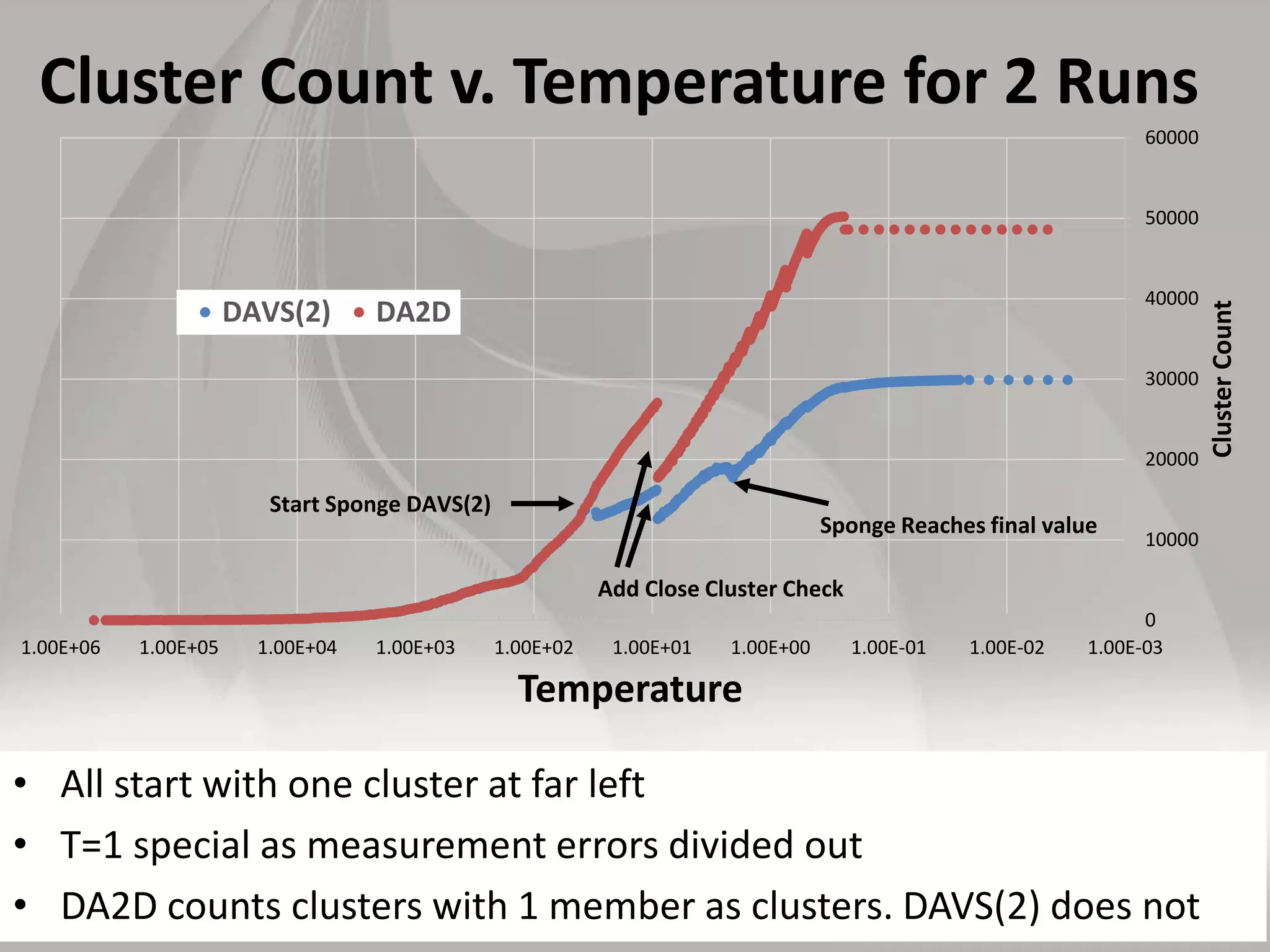


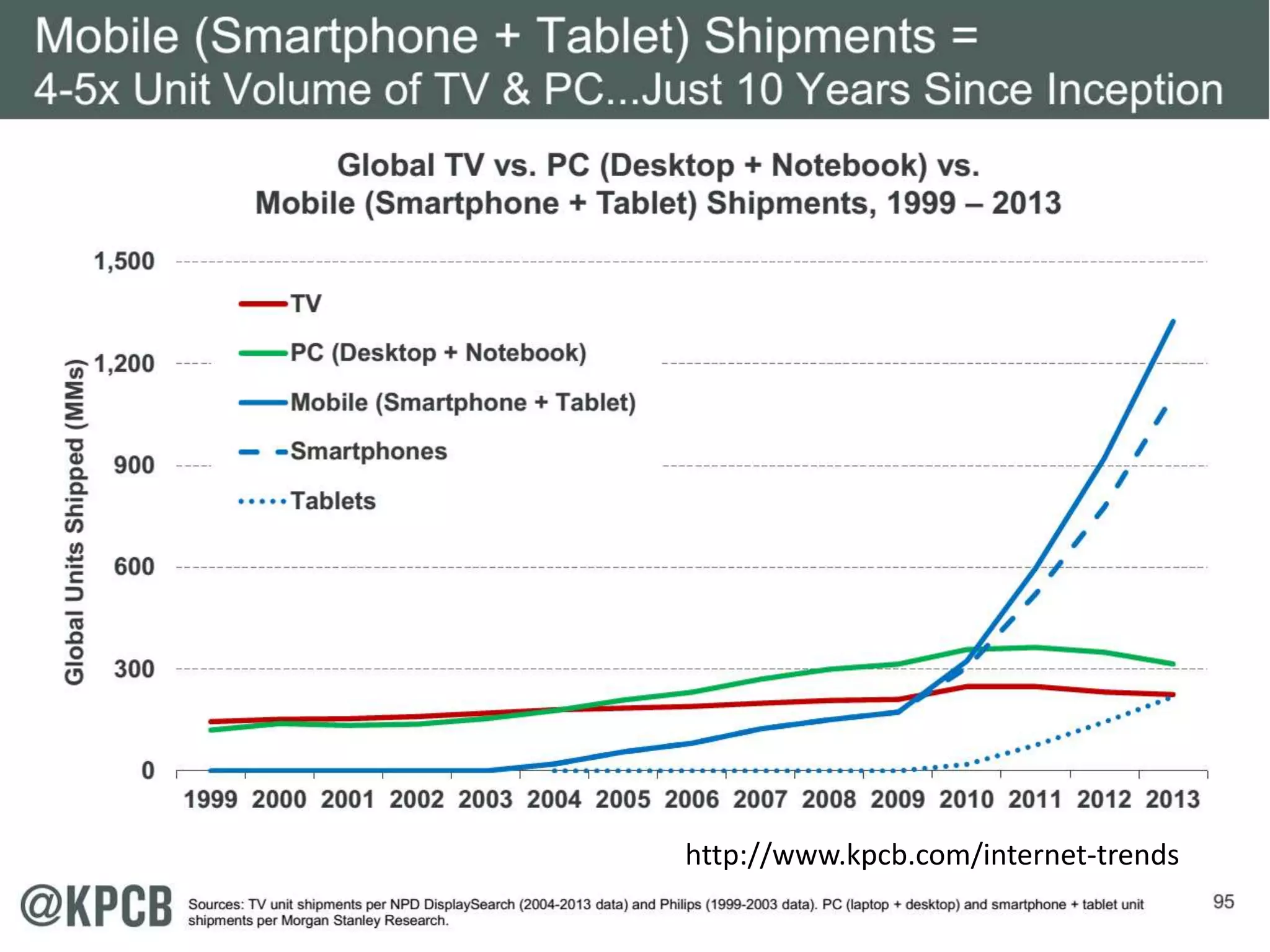

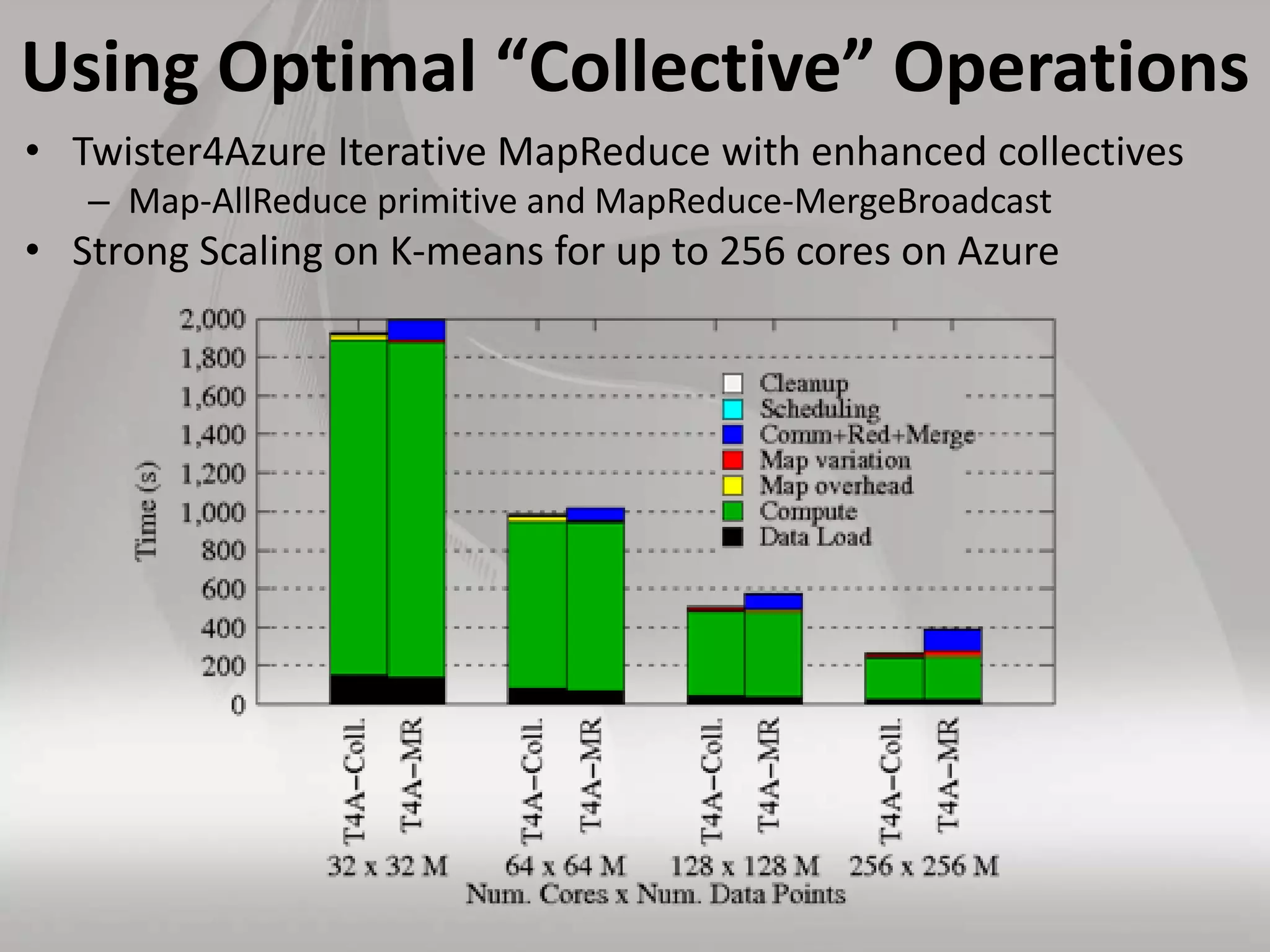
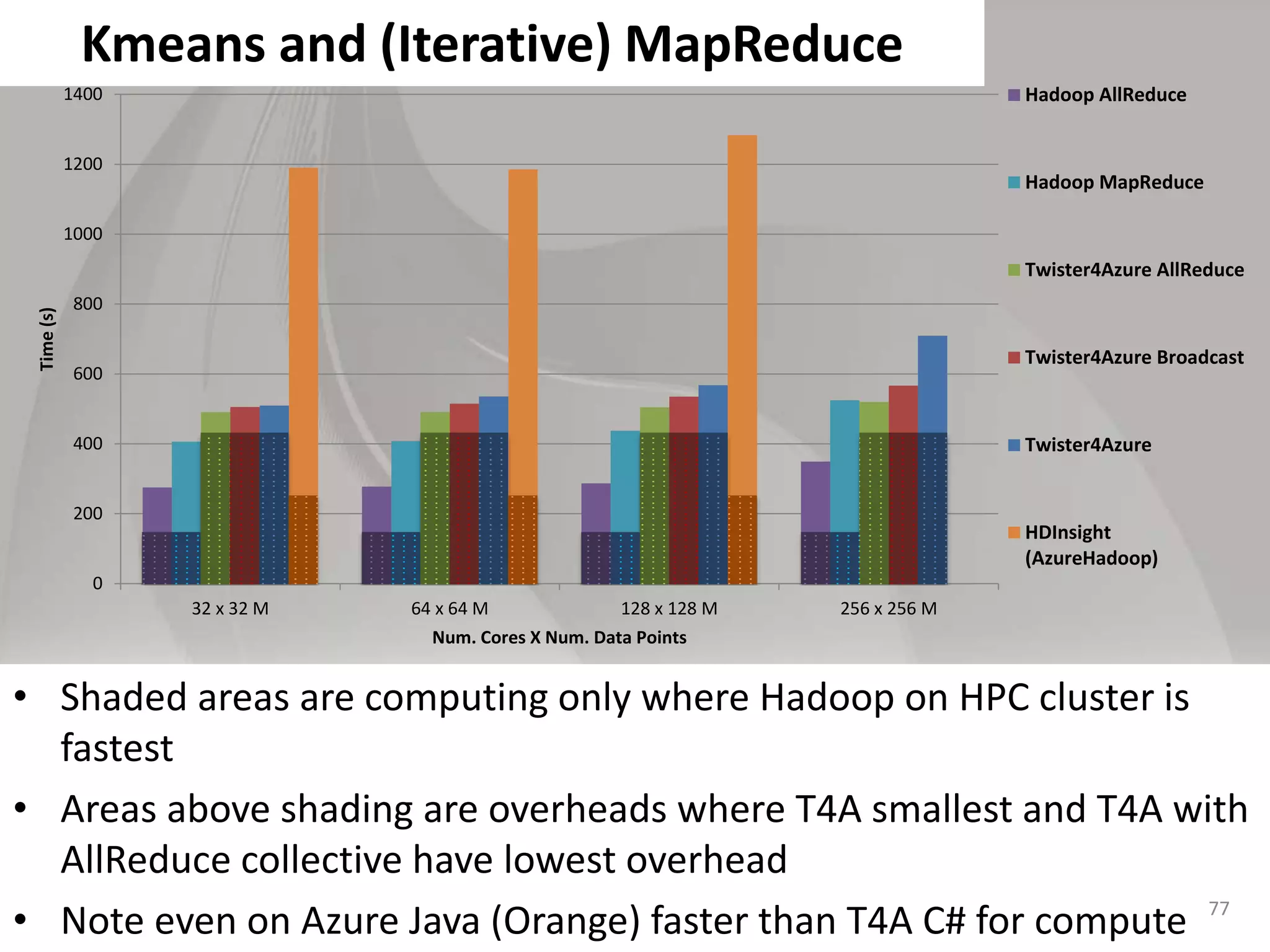
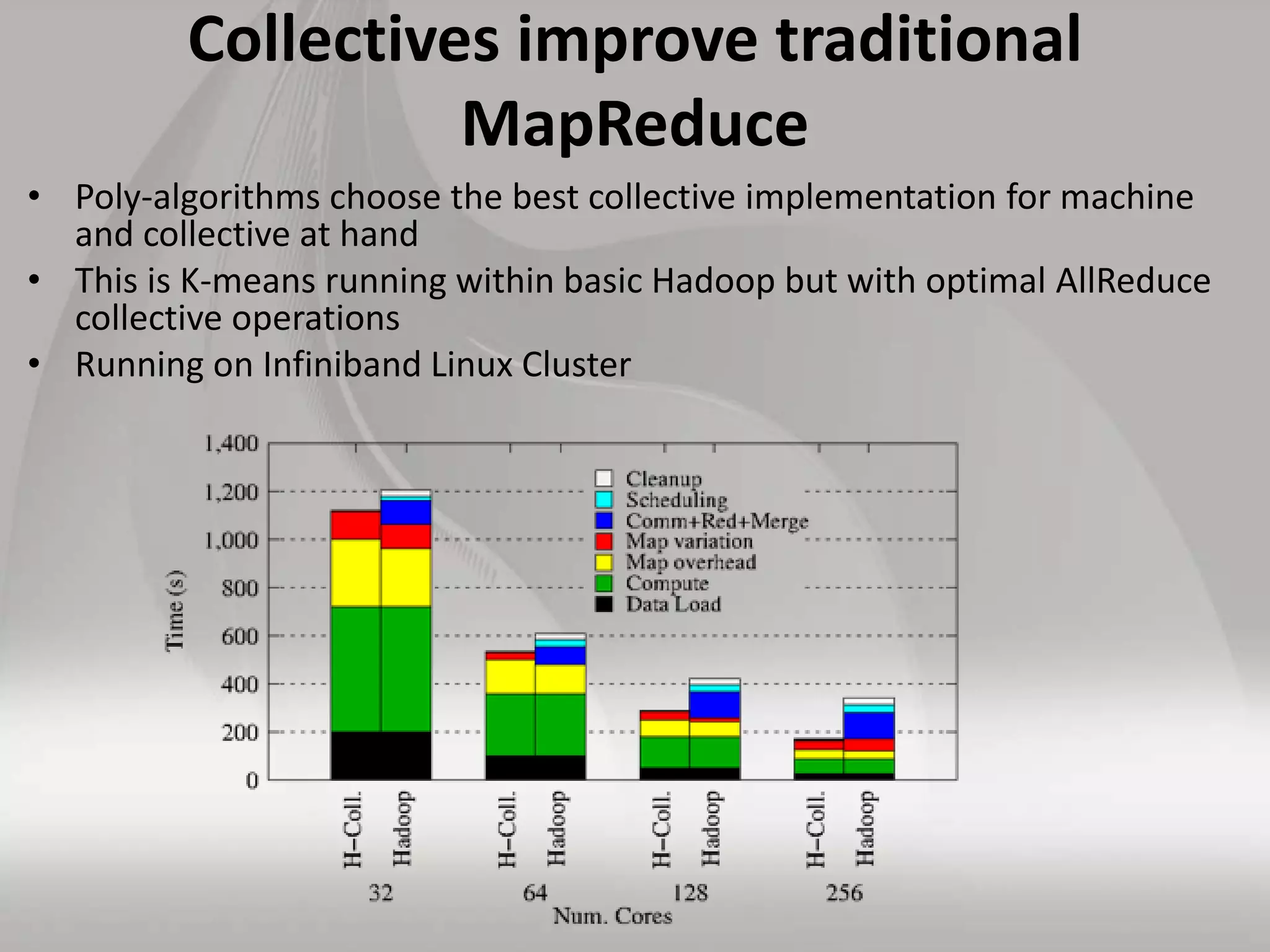

This document discusses matching data intensive applications to hardware and software architectures. It provides examples of over 50 big data applications and analyzes their characteristics to identify common patterns. These patterns are used to propose a "big data version" of the Berkeley dwarfs and NAS parallel benchmarks for evaluating data-intensive systems. The document also analyzes hardware architectures from clouds to HPC and proposes integrating HPC concepts into the Apache software stack to develop an HPC-ABDS software stack for high performance data analytics. Key aspects of applications, hardware, and software architectures are illustrated with examples and diagrams.
















































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)











![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


