More Related Content

PPTX
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について 
PDF

PDF
Trust Region Policy Optimization 
PDF

PDF

PDF

PPTX

PDF
What's hot

PPTX

PDF

PDF

PDF

PDF
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder 
PDF
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎 
PPTX
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて- 
PPTX
Positive-Unlabeled Learning with Non-Negative Risk Estimator 
PDF

PPTX

PDF

PDF

PDF
![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019 
PDF
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF

PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章 Viewers also liked

PPTX
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 3.3節と3.4節 
PPTX
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 4.2節 
PPTX
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 2.3節〜2.5節 
PPTX
スパース性に基づく機械学習(機械学習プロフェッショナルシリーズ) 1章 
PDF

PPTX
A simple neural network mnodule for relation reasoning Similar to スパース性に基づく機械学習 2章 データからの学習

PDF

PDF

PDF

PDF

PDF
クラシックな機械学習の入門 4. 学習データと予測性能 
PDF
Hands on-ml section1-1st-half-20210317 
PPTX

PDF

PDF

PPTX

PDF
Sparse estimation tutorial 2014 
PDF
ML: Sparse regression CH.13 
PPTX

PPTX
TECHTALK 20230131 ビジネスユーザー向け機械学習入門 第1回~機械学習の概要と、ビジネス課題と機械学習問題の定義 
PPTX

PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ 
PPTX

PPTX

PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半 
PDF
More from hagino 3000

PDF
Cloud DatalabとBigQueryを使ったアドホックデータ解析 
PDF
異常検知と変化検知 9章 部分空間法による変化点検知 
PDF

PDF
Secure Code for Interactive Programming 
PDF
ハイパフォーマンスブラウザネットワーキング 12章「HTTP 2.0」と現在の仕様 
PDF

PDF
Introduction of Leap Motion 
PDF
Where does my money go チーム発表 
PDF

PDF

KEY
ノンタッチUI時代とフロントエンドエンジニア (Using emotiv) 
PDF

PDF

PDF
Introduction of Kinect Hacks 
PDF
JavaScriptとSalesforceとTwitterマーケティングな話をした時の資料 
PDF

KEY

KEY

KEY
Google App Engine で初めるServerSide JavaScript 
KEY
スパース性に基づく機械学習 2章 データからの学習
- 1.
1章 & 2章
はじめに& データからの学習
機械学習プロフェッショナルシリーズ輪読会
~スパース性に基づく機械学習*1~
2016-2-10
@hagino3000 (Takashi Nishibayashi)
- 2.
- 3.
1章 はじめに
• スパース性とは
•まばらである事
• 多くの変数のうち殆どがゼロでごく一部だけが非ゼロ
• ゲノムの個人差からの予測ケース
• featureが膨大
• 現実的な仮定を置いて、少ないサンプルで推定したい
• 組み合わせ爆発を防いで現実的な計算量で推定したい
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
データから学習するとは
• 訓練データ (xi,yi)i が何らかの規則に従って生成さ
れている時に、データを生成する規則をなるべくよ
く模倣し、再現する事
• (xi, yi) が同時確率P(x,y)から独立同一に生成されて
いるという状況を考えるのが統計的機械学習
• 訓練データには無い、新しく書かれた数字を識別で
きるようになることを汎化すると言う
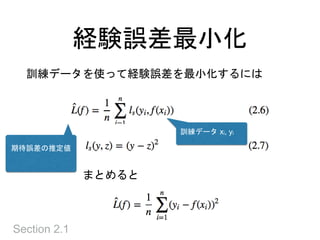
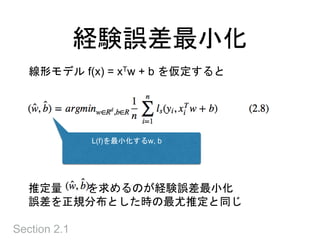
Section 2.1
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
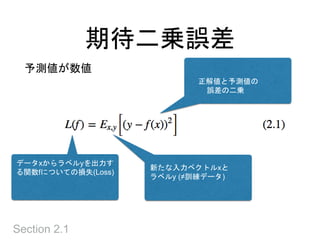
期待誤差
• 未知の確率分布 P(x,y) に関する期待値なので、直
接評価できない
• 期待誤差と呼び、訓練データで計算できる経験誤差
とは区別
• 直接計算できない → 訓練データで近似する
Section 9.1
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
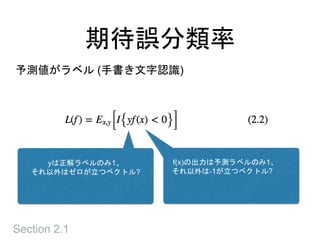
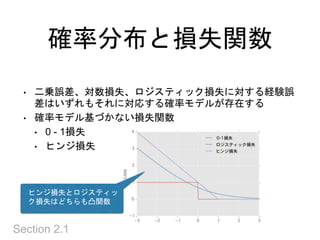
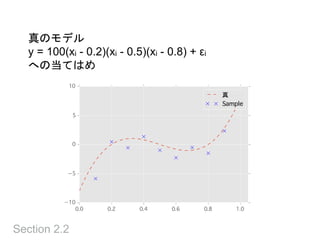
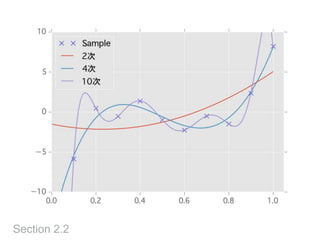
過剰適合を防ぐ
Section 2.2
• 10次の多項式で当てはめると誤差ゼロ
•真の関数だけでなく、ノイズにも適合してしまった
• モデルを制約するには
• 多項式などの独立な基底関数の和として関数fを表現し、
その基底関数の数を小さくおさえる
• 関数fの何らかのノルムを抑える
• モデルを小さくしすぎると、モデル化したい関数も表現で
きなくなる → 過少適合
• モデルの小ささに由来する誤差 → バイアス or 近似誤差
- 28.
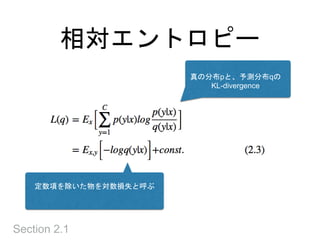
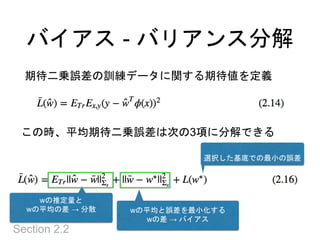
バイアス - バリアンス分解
Section2.2
期待二乗誤差の訓練データに関する期待値を定義
この時、平均期待二乗誤差は次の3項に分解できる
wの推定量と
wの平均の差 → 分散 wの平均と誤差を最小化する
wの差 → バイアス
選択した基底での最小の誤差
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
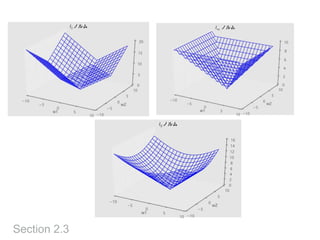
モデル選択
Section 2.4
• モデルの持つパラメータを決定したい
•訓練データに対してはCを大きくすれば当てはまりは良く
なってしまう → 訓練データは使えない
• 検証(validation)データを使う
• データを訓練用と検証用に分ける
• 検証データに対する誤差を最小化する
• 交差確認(cross validation)
• 訓練データをK個に分割し、K-1個で学習し、残りで誤差を
評価する
Kをデータと同じまで増やすとLeave-one-out
- 35.
- 36.
- 37.